一颗赛艇!上海交大搞出SRNN,比普通RNN也就快135倍
安妮 编译整理
量子位 出品 | 公众号 QbitAI
快了135倍。
近日,上海交大的研究人员提出了切片循环神经网络(Sliced recurrent neural networks,SRNN)的结构,在不改变循环单元的情况下,比RNN结构快135倍。
这种如同脚踩风火轮一般的操作,究竟是怎样实现的?
在论文《Sliced Recurrent Neural Networks》中,研究人员给出了具体介绍。我们先来看看“全是重点其他免谈”的论文重点——

“曲线救国”的SRNN
传统RNN结构中最流行的循环单元是LSTM和GRU,二者都能在隐藏层中通过门控机制(Gating Mechanism)存储近期信息,然后决定这些信息将以怎样的程度和输入结合。这种结构的缺点也很明显,RNN很难实现并行化处理。
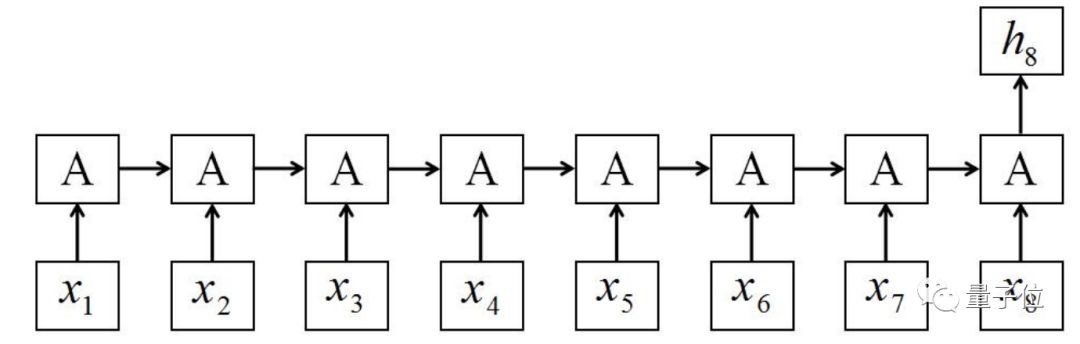
△ 传统RNN结构,A代表循环单元 | 每一步都需要等待上一步的输出结果
因此,很多学者选在在NLP任务中用CNN来代替,但CNN无法有效获取重要的顺序信息,效果并不理想。
SRNN的结构基于RNN结构进行改良,将输入的序列切成最小的等长子序列。在这种结构中,无需等待上一步的输出结果,循环单元可在每一层的每一个子序列中同时开工,并且信息可通过多层神经网络进行传送。
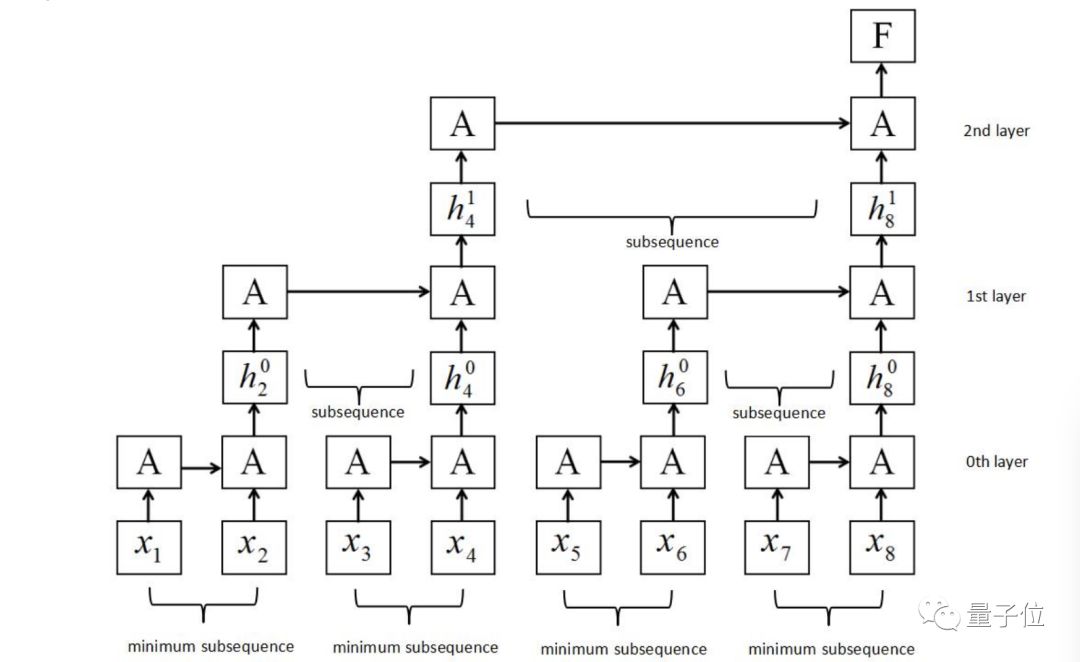
△ SRNN结构图,A代表循环单元
最后,研究人员比较了SRNN和RNN在不同序列长度时的训练时间和与速度。
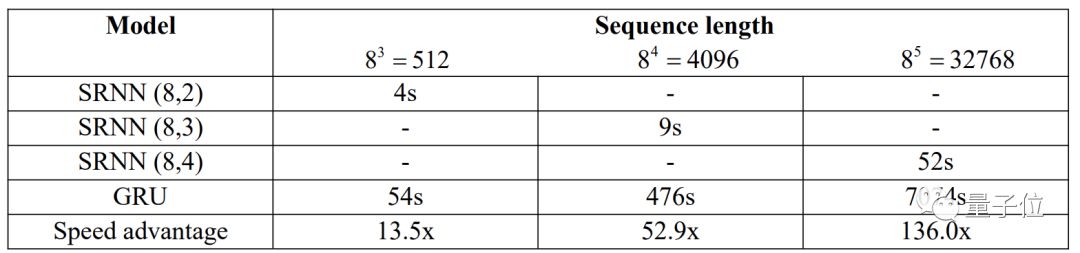
结果显示,序列越长,SRNN的优势越明显,当序列长度为32768时,SRNN的速度达到了RNN的136倍。
论文摘要
在NLP(自然语言处理)的很多任务中,循环神经网络已经取得了成功。然而这种循环的结构让并行化变得很困难,所以,训练RNN的时间通常较长。
在这篇文章中,我们提出了一种切片循环神经网络的结构,能够将序列切割成很多子序列,从而实现并行。这种结构可以在额外参数较少的情况下,通过神经网络的多个层次获取高级信息。
我们已经证明,我们可以将标准的RNN结构理解为是SRNN在使用线性激活函数时的特殊情况。
在不改变循环单元的情况下,SRNN能够比标准RNN快135倍,在训练长序列时甚至更快。我们也在大型情感分析数据集上用实验证实,SRNN的表现优于RNN。

论文传送门
关于这项研究的更具体的细节,可以移步上海交大电气信息与电气工程学院的Zeping Yu和Gongshen Liu的论文《Sliced Recurrent Neural Networks》,地址如下——
https://arxiv.org/abs/1807.02291
玩得开心~
— 完 —
活动报名

实习生招聘
量子位正在招募活动运营实习生,策划执行AI明星公司CEO、高管等参与的线上/线下活动,有机会与AI行业大牛直接交流。工作地点在北京中关村。简历欢迎投递到quxin@qbitai.com
具体细节,请在量子位公众号(QbitAI)对话界面,回复“实习生”三个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




