一文详解LSTM网络
编者按:长短期记忆(Long Short-Term Memory,LSTM)是一种时间递归神经网络(RNN),适合被用于处理和预测时间序列中间隔和延迟非常长的重要事件,经多年实验证实,它通常比RNN和HMM效果更好。那么LSTM的工作原理究竟是什么?为了讲述这个概念,论智搬运了chrisolah的一篇经典文章,希望能给各位读者带来帮助。

递归神经网络
当人类接触新事物时,他们不会从头开始思考。就像你在阅读这篇文章时,你会根据以前的知识理解每个单词,而不是舍弃一切,从字母开始重新学习。换句话说,你的思维有延续性。
神经网络的出现旨在赋予计算机人脑的机能,但在很长一段时间内,传统的神经网络并不能模仿到这一点。而这似乎是个很严峻的缺点,因为它意味着神经网络无法从当前发生的事推断之后将要发生的事,也就是无法分类电影中流畅发生的各个事件。
后来,递归神经网络(RNN)的出现解决了这个问题,通过在网络中添加循环,它能让信息被“记忆”地更长久。
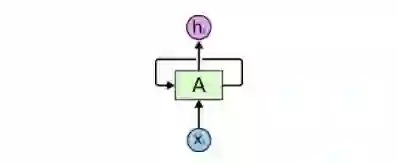
RNN有循环
上图是一个大型神经网络A,输入一些数据xt后,它会输出最终值ht。循环允许信息从当前步骤传递到下一个步骤。
这些循环使它看起来有些神秘。但如果仔细一想,你会发现其实它和普通的神经网络并没有太大区别:一个RNN就相当于是一个神经网络的多个副本,每个副本都会把自己收集到的信息传递给后继者。如果我们把它展开,它是这样的:
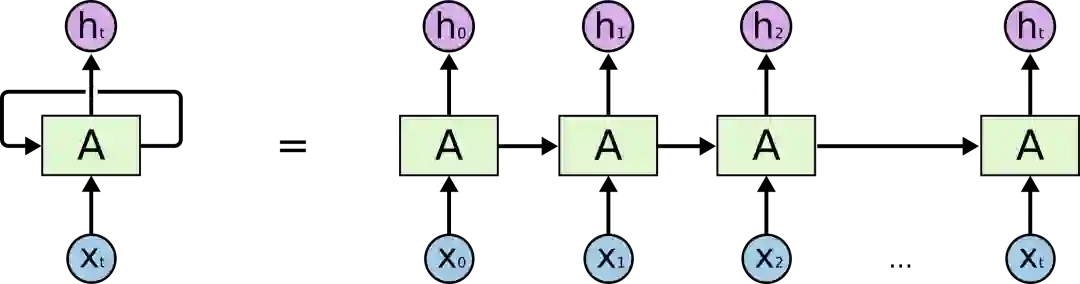
展开的RNN
这种链式性质揭示了RNN和序列、列表之间的密切关系。从某种程度上来说,它就是专为这类数据设计的神经网络自然架构。
实践也证实,RNN确实有用!过去几年里,它在各类任务中取得了令人难以置信的成功:语音识别、语言建模、机器翻译、图像字幕……应用场景十分广阔。几年前,现任特斯拉AI总监Andrej Karpathy写了一篇名为The Unreasonable Effectiveness of Recurrent Neural Networks的博客,专门介绍了RNN“不合理”的适用性,有兴趣的读者可以前去一读。
在文章中我们可以发现,这种适用性的关键是“LSTM”的使用。这是一种非常特殊的RNN,所有能用RNN实现的东西,LSTM都能做,而且相较于普通版,它在许多任务中还会有更优秀的表现。所以下文我们就来看看什么是LSTM。
长期依赖问题
RNN最具吸引力的一点是它能把之前的信息连接到当前的任务上,比如我们可以用之前的视频图像理解这一帧的图像。如果能建立起这种联系,它的前途将不可限量。所以它真的能做到吗?答案是:不一定。
有时候,我们只需要查看最近的信息就能执行当前任务,如构建一个能根据前一个词预测下一个词的语言模型。如果我们要预测“天空中漂浮着云朵,”这个句子的最后一个词语,模型不需要任何进一步的语义背景——很明显,最后一个词是“云朵”。在这种情况下,如果相关信息和目标位置差距不大,RNN完全能学着去用以前的知识。

但有时我们也会希望模型能联系下上文进行理解,比如预测“我在法国长大......我会说流利的法语。”这句话的最后一个词。最近的信息提示是这个词很可能是一种语言的名称,如果要精确到是哪种语言,我们就需要结合句子开头的“法国”来理解。这时两个相关信息之间间隔的距离就非常远。
不幸的是,随着距离不断拉大,RNN会逐渐难以学习其中的连接信息。
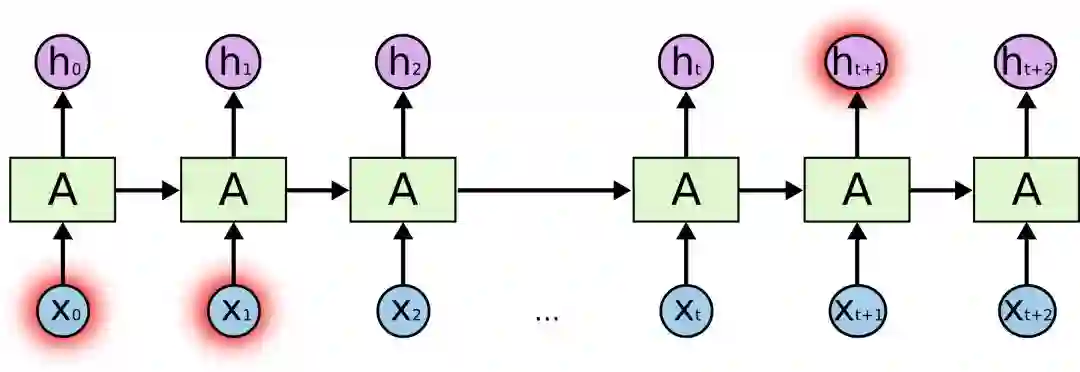
从理论上看,RNN绝对有能力去处理这种长期依赖性,我们可以不断调参来解决各种玩具问题,但在实践中,RNN却彻头彻尾地失败了。关于这个问题,之前Hochreiter(1991)和Bengio等人(1994)已经做了深入探讨,此处不再赘述。
谢天谢地,LSTM没有这些问题。
LSTM网络
长期短期记忆网络——通常被称为“LSTM”——是一种特殊的RNN,能学习长期依赖性。它最早由Hochreiter&Schmidhuber于1997年提出,后经众多专家学者提炼和推广,现在因性能出色已经被广泛使用。
LSTM的设计目的非常明确:避免长期依赖性问题。对LSTM来说,长时间“记住”信息是一种默认的行为,而不是难以学习的东西。
之前我们提到了,RNN是一个包含大量重复神经网络模块的链式形式,在标准RNN里,这些重复的神经网络结构往往也非常简单,比如只包含单个tanh层:

标准RNN中只包含单个tanh层的重复模块
LSTM也有与之相似的链式结构,但不同的是它的重复模块结构不同,是4个以特殊方式进行交互的神经网络。
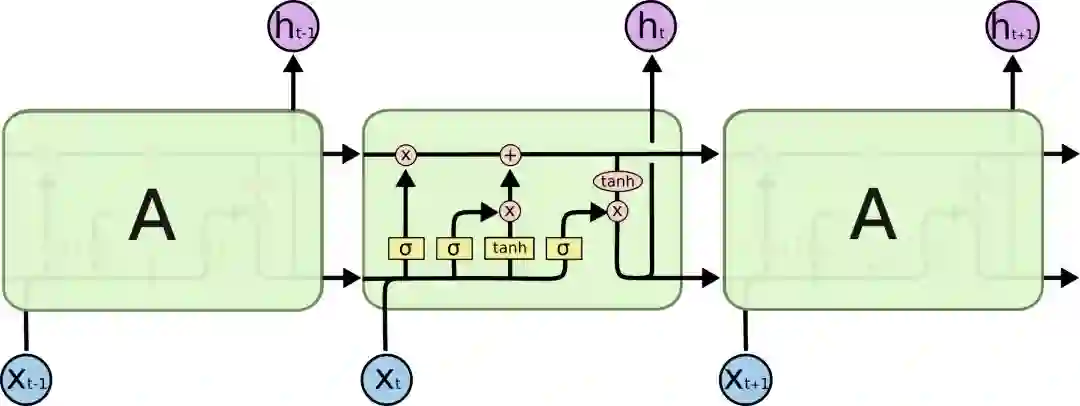
LSTM示意图
这里我们先来看看图中的这些符号:

在示意图中,从某个节点的输出到其他节点的输入,每条线都传递一个完整的向量。粉色圆圈表示pointwise操作,如节点求和,而黄色框则表示用于学习的神经网络层。合并的两条线表示连接,分开的两条线表示信息被复制成两个副本,并将传递到不同的位置。
LSTMs背后的核心理念
LSTMs的关键是cell的状态,即贯穿示意图顶部的水平线。
cell状态有点像传送带,它只用一些次要的线性交互就能贯穿整个链式结构,这其实也就是信息记忆的地方,因此信息能很容易地以不变的形式从中流过。
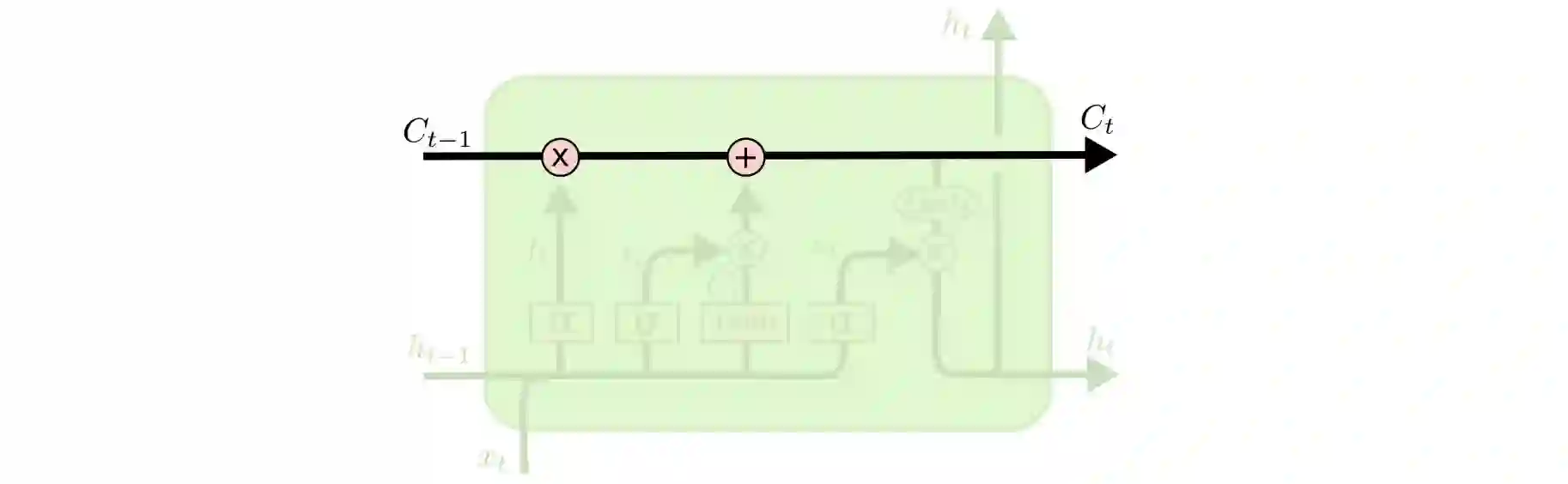
为了增加/删除cell中的信息,LSTM中有一些控制门(gate)。它们决定了信息通过的方式,包含一个sigmoid神经网络层和一个pointwise点乘操作。
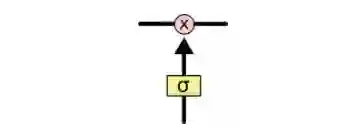
sigmoid层输出0到1之间的数字,点乘操作决定多少信息可以传送过去,当为0时,不传送;当为1时,全部传送。
像这样的控制门,LSTM共有3个,以此保护和控制cell状态。
深入了解LSTM
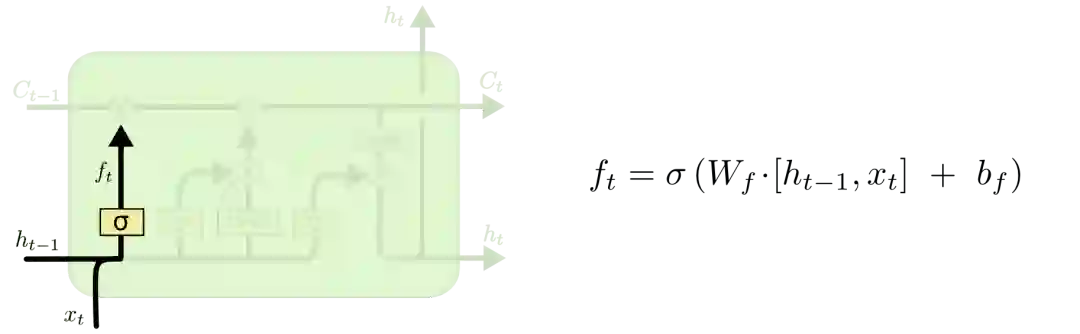
我们先来看看cell该删除哪些信息,做这个决定的是包含sigmoid层的遗忘门。对于输入xt和ht-1,遗忘门会输出一个值域为[0, 1]的数字,放进细胞状态Ct−1中。当为0时,全部删除;当为1时,全部保留。
以之前预测下一个词的语言模型为例,对于“天空中漂浮着云朵,”这个句子,LSTM的cell状态会记住句子主语“云朵”的词性,这之后才能判断正确的代词。等下次再遇到新主语时,cell会“忘记”“云朵”的词性。
我们再来看看cell该如何增加新信息。这可以分为两步,首先,LSTM会用一个包含sigmoid层的输入门决定哪些信息该保留,其次,它会用一个tanh层为这些信息生成一个向量C~t,用来更新细胞状态。
在语言模型例子中,如果句子变成了“天空中漂浮着云朵,草地上奔跑着骏马”。那LSTM就会用“骏马”的词性代替正在被遗忘的“云朵”的词性。
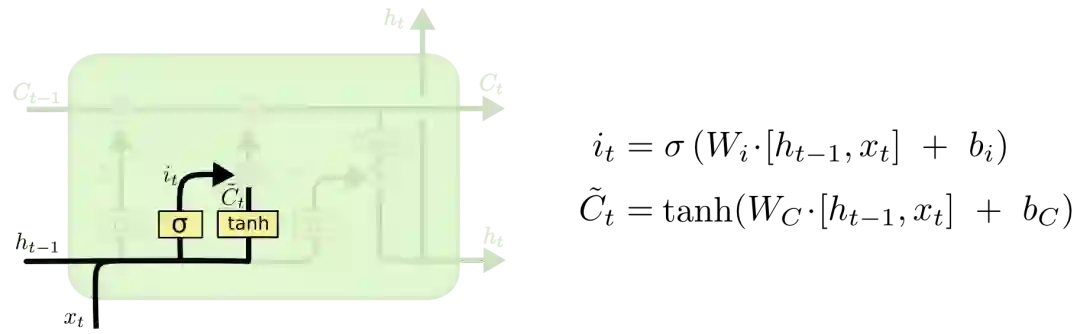
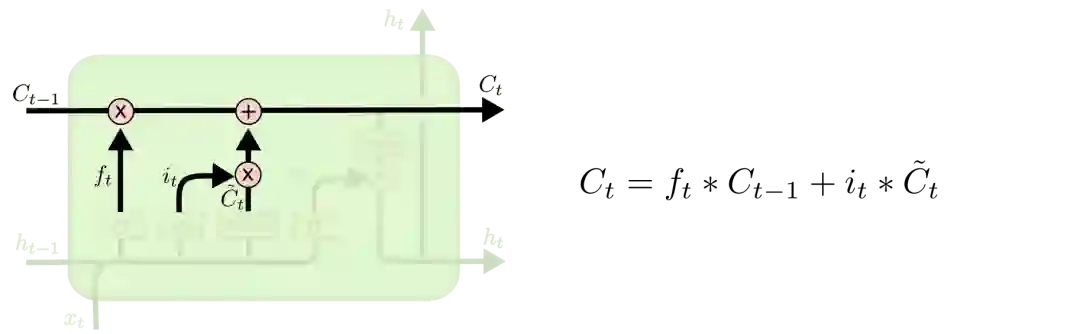
有了遗忘门和输入门,现在我们就能把细胞状态Ct−1更新为Ct了。如下图所示,其中ft×Ct−1表示希望删除的信息,it×Ct表示新增的信息。
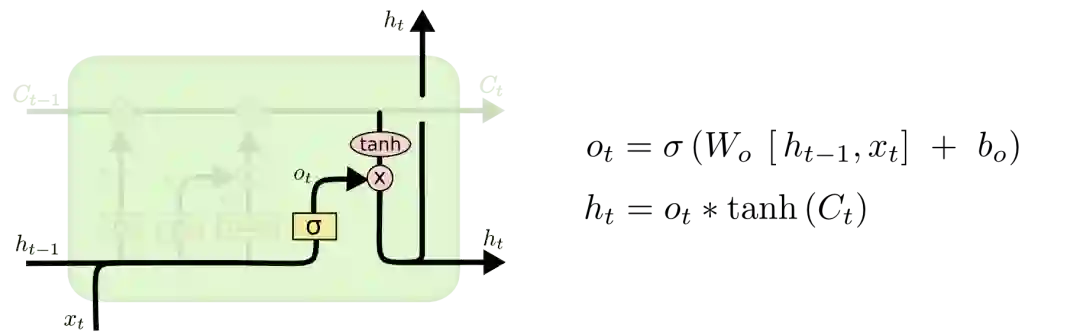
最后就是决定LSTM输出内容的输出门。它的信息基于cell状态,但还要经过一定过滤。我们先用sigmoid层决定将要输出的cell内容,再用tanh层把cell状态值推到-1和1之间,并将其乘以sigmoid层的输出,以此做到只输出想要输出的部分。
LSTM的变体
以上介绍的是一个非常常规的LSTM,但在实践中我们也会遇到很多很不一样的神经网络,因为一旦涉及使用,人们就会不可避免地要用到一些DIY版本。虽然它们差异不大,但其中有一部分值得一提。
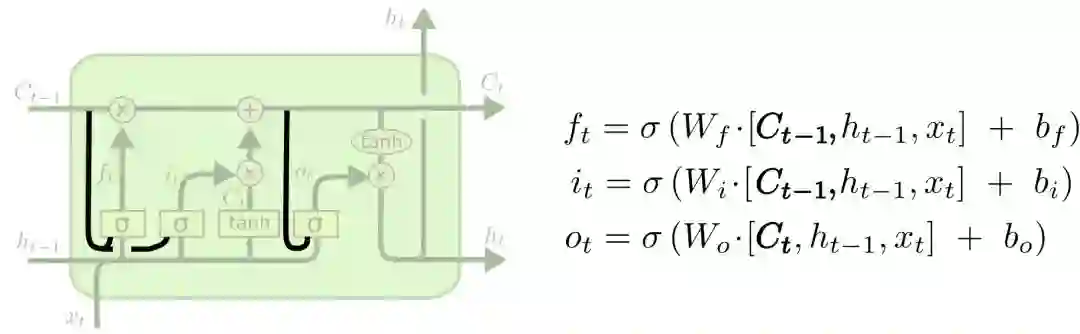
2000年的时候,Gers&Schmidhuber提出了一种添加了“peephole connections”的LSTM变体。它意味着我们能在相应控制门内观察cell状态。下图为每个门都添加了窥视孔,我们也可以只加一处或两处。
第二种变体是耦合遗忘门和输入门,让一个模块同时决定该增加/删除什么信息。
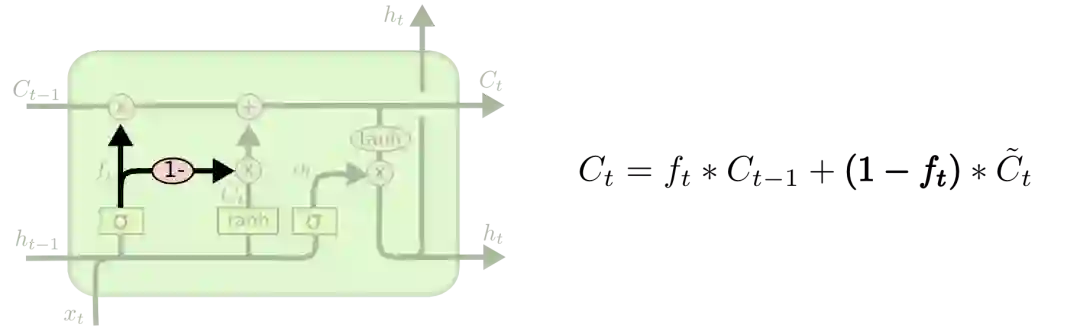
第三种稍具戏剧化的变体是Cho等人于2014年提出的带有GRU的LSTM。它把遗忘门和输入门组合成一个“更新门”,合并了cell状态和隐藏状态,并做了一些其他的修改。这个模型的优点是更简单,也更受欢迎。
以上只是几个最知名的LSTM变体,还有很多其他的,比如Yao等人的Depth Gated RNN。此外一些人也一直在尝试用完全不同的方法来解决长期依赖问题,比如Koutnik等人的Clockwork RNN。
小结
如果只是列一大堆数学公式,LSTM看起来会非常吓人。因此为了让读者更容易理解掌握,本文制作了大量可视化图片,它们也一直深受业内人士认可,在各类文章中被广泛引用。
LSTM是完善RNN的重要内容,虽然它到现在已经成果累累,但我们以此为起点,探索RNN身上的其他研究方向,如近两年非常红火的注意力机制(Attention Mechanism)、在GAN中使用RNN等。过去几年对神经网络来说是激动人心的一段时光,相信未来会更加如此!
原文地址:colah.github.io/posts/2015-08-Understanding-LSTMs/