Conformer: 卷积增强的Transformer

最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系。
以下是要写的文章,本文是这个系列的第二十一篇,内容较为深入,需要学习基础的同学点击链接进入文章列表查看基础知识相关文章。
Overall
自从Transformer被提出以来,在NLP领域大放异彩。同时,卷积也是视觉领域的扛把子。这两种模型特性是有差别的。Transformer在提取长序列依赖的时候更有效,而卷积则是擅长提取局部特征。那么有没有可能把这两种特性结合起来去做模型了。参考文献[1]和[2]分别给出了探索的结果。
参考文献[1]中提出的conformer是用卷积去加强Transformer在语音识别领域的效果。而参考文献[2]则是用注意力机制去增强卷积网络的效果。下面,我们先来看一下conformer是如何做的。
Conformer
语音识别使用的也是一个seq2seq模型,在这里,只使用卷积来改变encoder部分。
Conformer Encoder的总体架构如下,其中conformer block是由Feedforward module,Multi-head self attention Module, Convolution Module三个Module组成的,其中每个Module上都用了残差。从这里可以看到,卷积和Attention通过串联起来达到增强的效果。
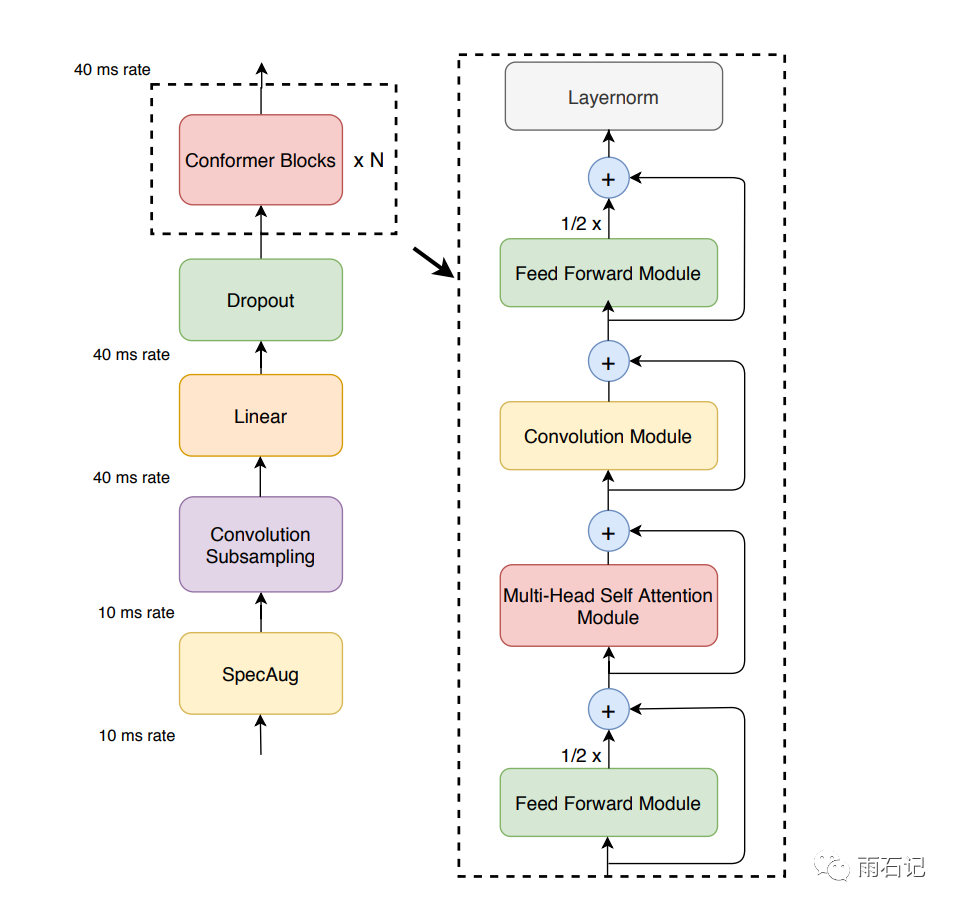
对于Convolution Module来说,使用了pre-norm残差,point-wise卷积和线性门单元(Gated Linear Unit)。如下图所示:

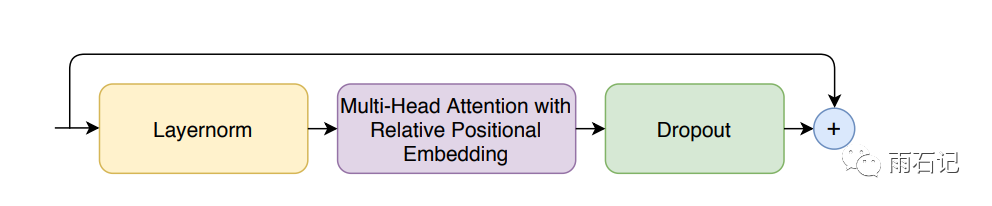
对于Multi-head self attention Module,使用了相对位置编码,dropout和pre-norm残差。
对于Feedforward Module来说,使用了Swish激活函数和dropout,如下图所示:

再回顾Conformer block,其实这很像一个三明治结构,因为前后都是Feedforward module,这点是受Macaron-Net启发得到的,即使用两个FFN,但是每个FFN都贡献一半的值。其计算公式如下:

实验
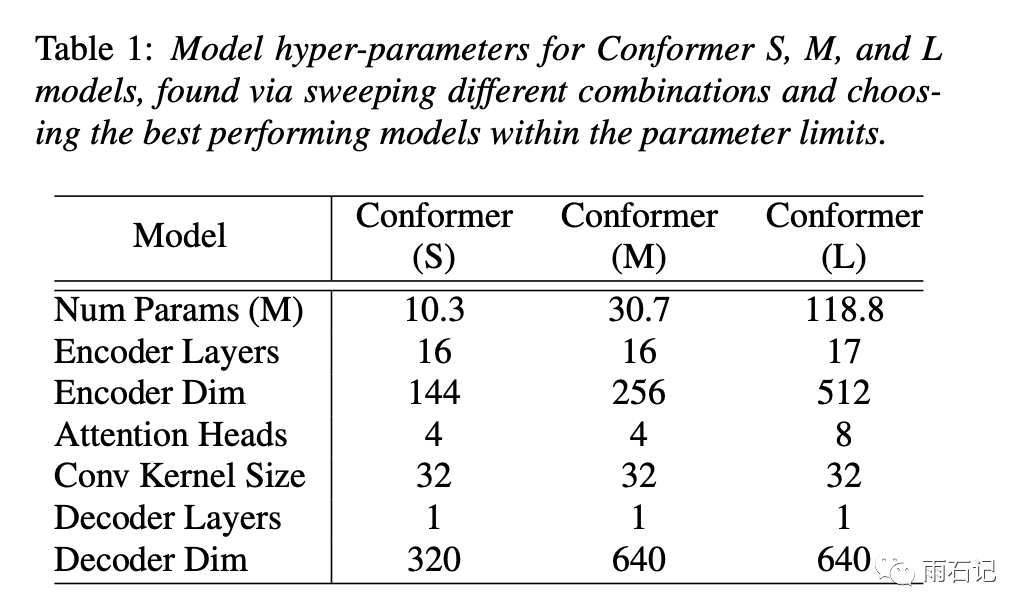
为了比较不同配置的Encoder的好坏,统一使用单层的LSTM作为decoder,模型使用Lingvo toolkit实现。
实验了三种不同尺寸的Conformer,如下表:
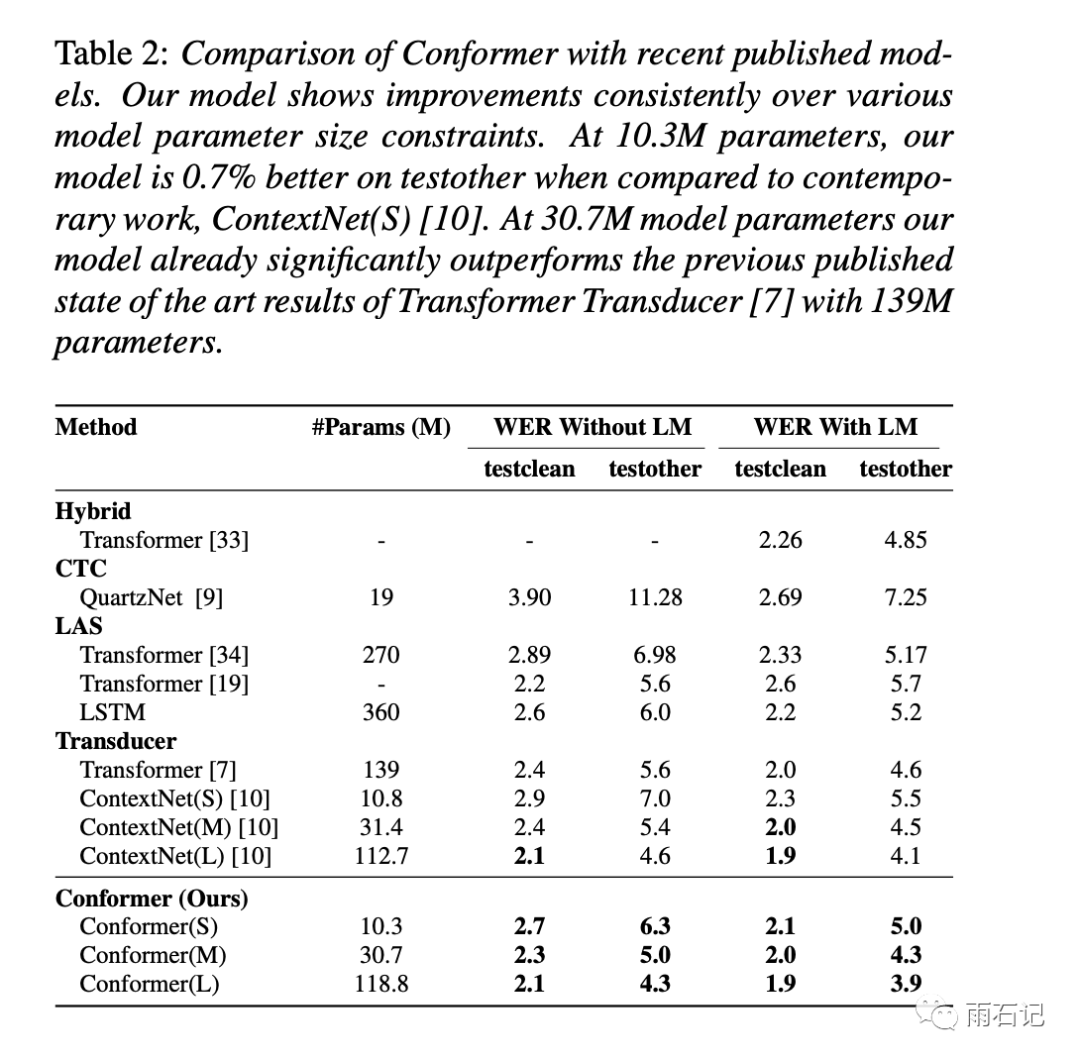
和其他模型的对比如下,Conformer都达到了较好的效果。
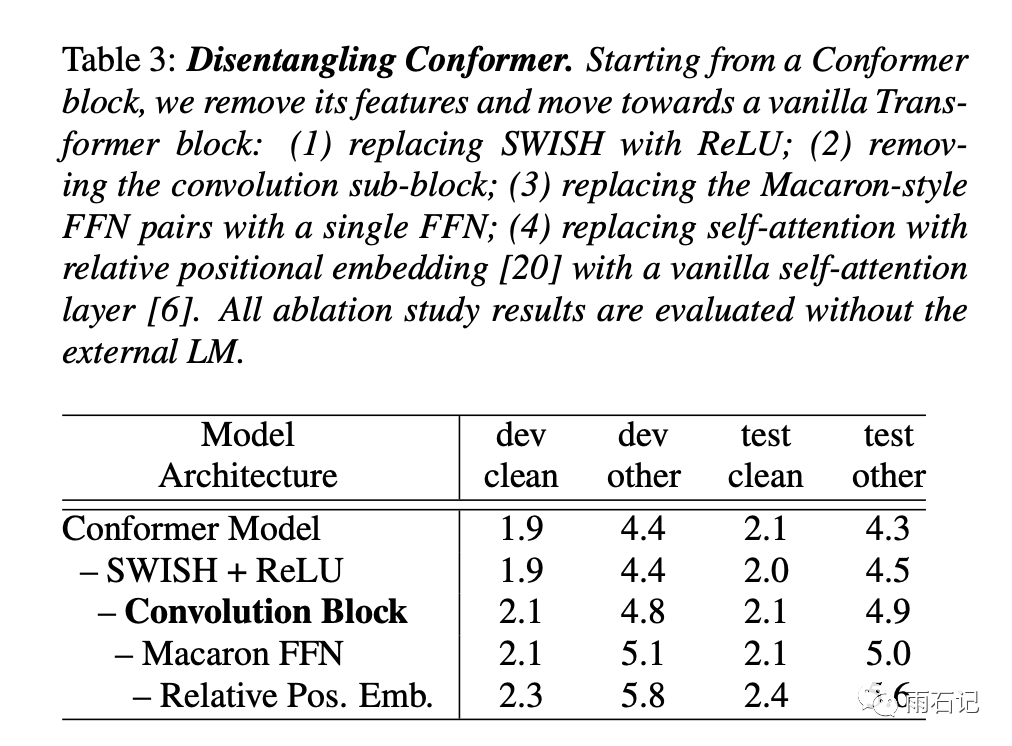
消融实验结果如下,卷积块在效果上最为重要,Macaron-style的三明治FFN对比只有一个FFN要好。Swish激活函数的使用使得模型收敛更快。
参考文献
-
[1]. Gulati, Anmol, et al. "Conformer: Convolution-augmented Transformer for Speech Recognition." arXiv preprint arXiv:2005.08100 (2020). -
[2]. Bello, Irwan, et al. "Attention augmented convolutional networks." Proceedings of the IEEE International Conference on Computer Vision. 2019.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


