用自注意力增强卷积:这是新老两代神经网络的对话(附实现)
选自arXiv
作者:Irwan Bello、Barret Zoph、Ashish Vaswani、Jonathon Shlens、Quoc V. Le
机器之心编译
参与:Panda
2014 年,Bahdanau 等人针对机器翻译任务提出了注意模型,现在它已成为一种常用的神经网络方法。近日,谷歌大脑在 arXiv 上公布了一篇新论文,提出使用注意机制增强卷积以加强获取全局相关性的能力。在图像分类和目标检测上的实验结果表明这种方法确实有效。
卷积神经网络(CNN)在大量计算机视觉应用中取得了极大成功,尤其是图像分类。卷积层的设计需要通过受限的感受野来确保局部性(locality),以及通过权重共享来确保平移等效性(translation equivariance)。研究表明,这两种属性是设计图像处理模型时关键的归纳偏置。但是,卷积核固有的局部性使它无法得到图像中的全局语境;而为了更好地识别图像中的对象,全局语境必不可少。
自注意力(self-attention)机制是获取长程交互性方面的一项近期进展,但主要还只是用在序列建模和生成式建模任务上。自注意机制背后的关键思路是求取隐藏单元计算出的值的加权平均。不同于池化或卷积算子,用在加权平均运算中的权重是通过隐藏单元之间的相似度函数动态地得到的。由此,输入信号之间的交互就取决于信号本身,而不是由它们的相对位置预先确定。尤其值得提及的是,这使得自注意机制能在不增多参数的前提下获取长城交互性。
这篇论文研究了将自注意(用作卷积的替代)用于判别式视觉任务的问题。研究者开发了一种全新的二维相对自注意机制,能够在纳入相对位置信息的同时维持平移等效性,这使得其非常适用于图像。研究表明,这种自注意方案非常有竞争力,足以完全替代卷积。尽管如此,对照实验表明,将自注意与卷积两者结合起来得到的结果最佳。因此,完全摈弃卷积思想是不妥的,而应该使用这种自注意机制来增强卷积。其实现方式是将卷积特征图(强制局部性)连接到自注意特征图(能够建模更长程的依赖)。
图 1 展示了这种注意增强方法在图像分类任务上的改进效果。
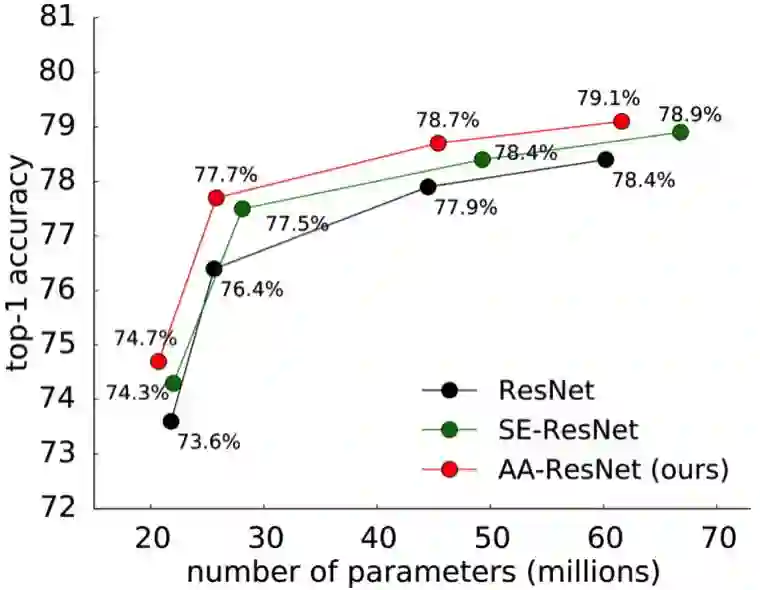
图 1:注意增强能系统性地改善不同规模的不同类型网络的图像分类结果。这里展示了不同参数量下不同模型的 ImageNet 分类准确度,其中 ResNet 是基准模型、SE-ResNet 使用了通道式注意增强、AA-ResNet 是本论文新提出的架构。
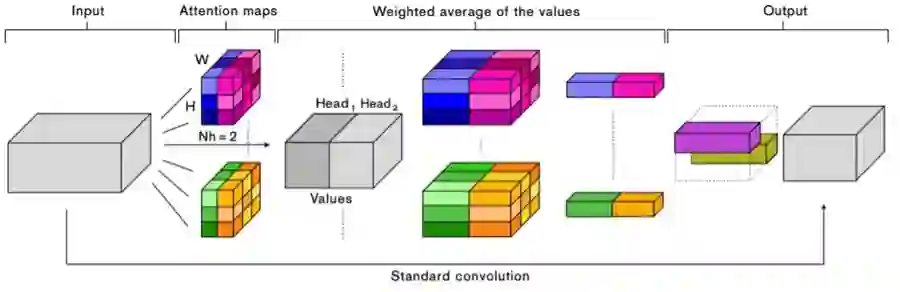
图 2:注意增强型卷积:对于每个空间位置 (h, w),都根据查询和键值在图像上计算出 N_h 个注意图(attention map)。这些注意图被用于计算 N_h 个这些值的加权平均 V。然后将所得结果连接起来,再重新调整形状以匹配原来的体空间维度并与一个逐点卷积混合。多头注意是以并行的方式应用于标准的卷积运算,输出再连接到一起。
新方法在 CIFAR-100 和 ImageNet 分类任务以及 COCO 目标检测任务上进行了测试,涉及到多种不同的架构和不同的计算成本预算,包括一种当前最佳的资源受限型架构。注意增强仅需极少量的计算负担就能实现系统性的改善,并且在所有实验中都明显优于流行的 Squeeze-and-Excitation 通道式注意方法。尤其值得提及的是,注意增强在 ImageNet 上实现的 top-1 准确度优于 ResNet50 基准 1.3%,在 COCO 目标检测上超过 RetinaNet 基准 1.4 mAP。实验还有个让人惊讶的结果:在 ImageNet 上全自注意模型(注意增强的一种特例)的表现仅略逊于对应的全卷积模型,这说明自注意本身就是一种强大的图像分类基本方法。
论文:Attention Augmented Convolutional Networks

论文链接:https://arxiv.org/pdf/1904.09925.pdf
在很多计算机视觉应用中,卷积网络都是首选范式。但是,卷积运算有一个显著缺陷,即仅在局部近邻上工作,也由此会错失全局信息。另一方面,自注意则是获取长程交互性方面的一项近期进展,但还主要应用于序列建模和生成建模任务上。在这篇论文中,我们研究了将自注意(作为卷积的替代)用于判别式视觉任务的问题。我们提出了一种全新的二维相对自注意机制,研究表明这足以在图像分类任务上替代卷积作为一种单独的原语。我们在对照实验中发现,当结合使用卷积与自注意时所得到的结果最好。因此我们提出使用这种自注意机制来增强卷积算子,具体做法是将卷积特征图与通过自注意产生的一组特征图连接起来。我们使用不同规模不同类型的模型(其中包括 ResNet 和一种当前最佳的可移动式受限网络)进行了广泛的实验,结果表明注意增强能在 ImageNet 图像分类与 COCO 目标检测任务上实现稳定的提升,同时还能保证参数数量大体接近。尤其值得提及的是,我们的方法在 ImageNet 上实现的 top-1 准确度优于 ResNet50 基准 1.3%,并且也优于 Squeeze-and-Excitation 等其它用于图像的注意机制。我们的方法还在 COCO 目标检测上超过 RetinaNet 基准 1.4 mAP。
方法
图 2:注意增强型卷积。
我们现在用数学形式描述新提出的注意增强方法。我们使用的符号表示为:H、W、F_in 分别表示一个激活图的高度、宽度和输入过滤器的数量。N_h、d_v 和 d_k 分别是指多头注意(multihead-attention / MHA)中头(head)的数量、值的深度、查询和键值的深度。我们进一步假设 N_h 均匀地划分 d_v 和 d_k,并用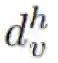
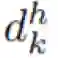
自注意
给定一个形状为 (H, W, F_in) 的输入张量,我们将其展开为一个矩阵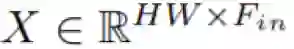
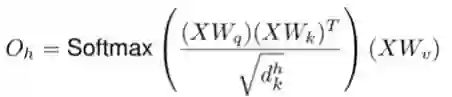
其中,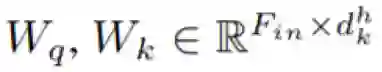
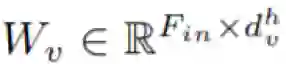
所有头的输出可以连接起来:
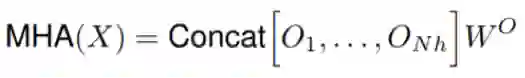
其中
注意增强型卷积
不同于之前的方法,我们使用的注意机制可以联合注意空间子空间和特征子空间;另外我们是引入额外的特征图,而不是对它们进行精细化处理。图 2 总结了我们提出的增强型卷积。

图 3:注意增强型 2D 卷积的 Python 代码
实验
我们在 CIFAR100、ImageNet 和 COCO 数据集上通过 ResNet 和 MnasNet 等标准计算机视觉架构对注意增强方法进行了实验测试。结果表明,在不同的架构和计算需求上,注意增强都能在图像分类和目标检测任务上实现系统性的提升。我们也通过消融实验评估了所提出的二维相对注意机制。在所有的实验中,我们都用自注意特征图替代卷积特征图,因为这能与基准模型进行更轻松的比较。除非另有说明,所有结果都对应于我们的二维相对自注意机制。
CIFAR-100 图像分类
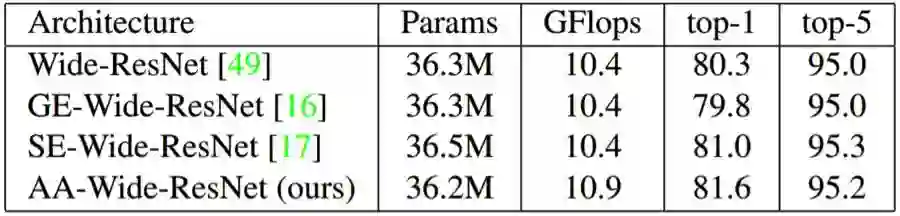
表 1:使用 Wide-ResNet 28-10 架构在 CIFAR-100 数据集上的图像分类结果。我们比较了基准模型与参数更少的 Gather-Excite (GE)、Squeeze-Excite (SE) 和新提出的注意增强 (AA) 的 top-1 与 top-5 准确度。
使用 ResNet 的 ImageNet 图像分类
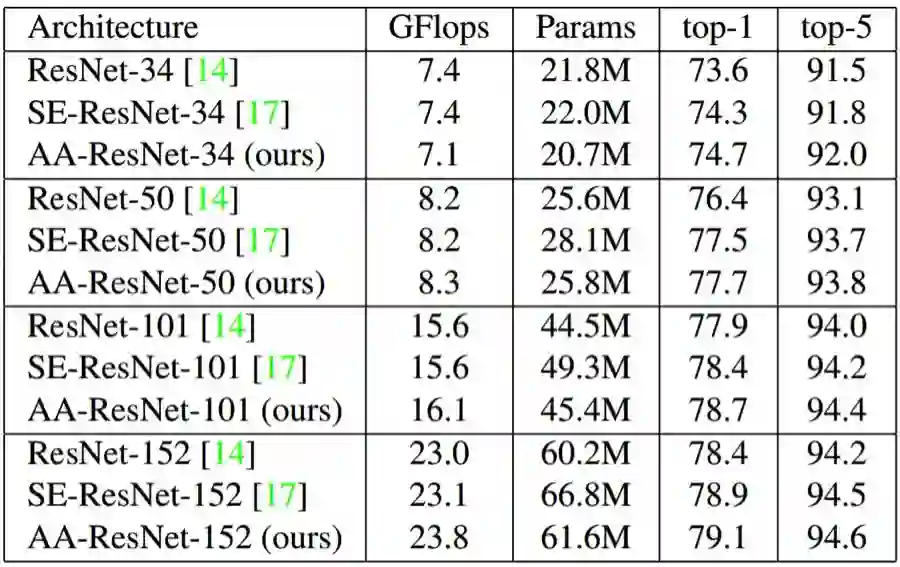
表 2:不同 ResNet 架构在 ImageNet 数据集上的图像分类结果。
使用 MnasNet 的 ImageNet 图像分类

表 3:宽度乘数为 0.75、1.0、1.25 和 1.4 时,基准和注意增强的 MnasNet 的准确度。
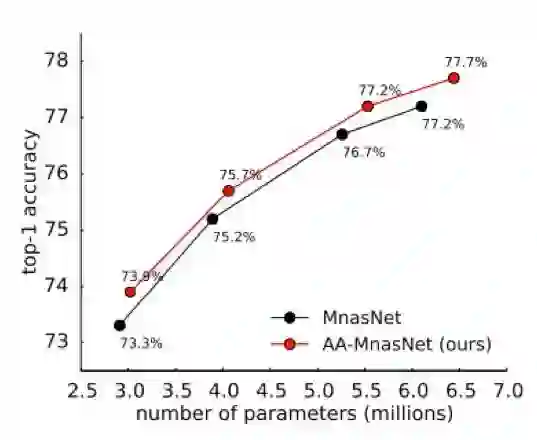
图 4:MnasNet(黑)和注意增强型 MnasNet(红)的 ImageNet top-1 准确度随参数数量的变化,深度乘数为 0.75、1.0、1.25 和 1.4。
基于 COCO 数据集的目标检测
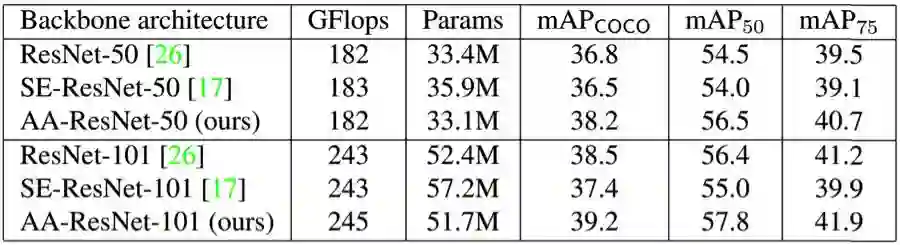
表 4:使用不同骨干架构的 ResNet 架构在 COCO 数据集上的目标检测结果。我们报告了在三个不同 IoU 值上的平均精度均值。
控制变量实验
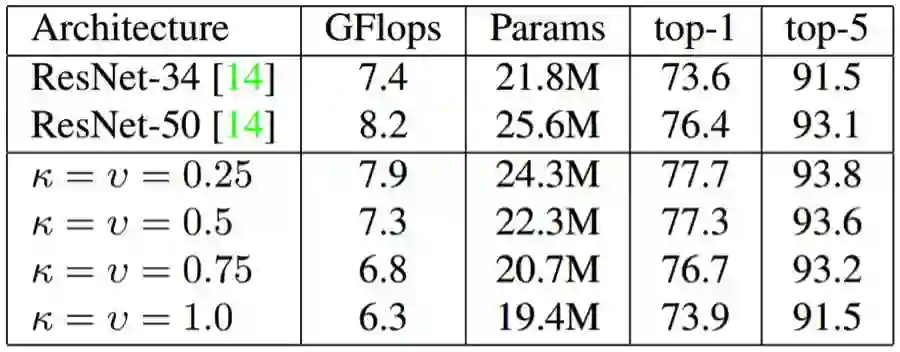
表 5:使用不同注意通道比例的注意增强型 ResNet-50。
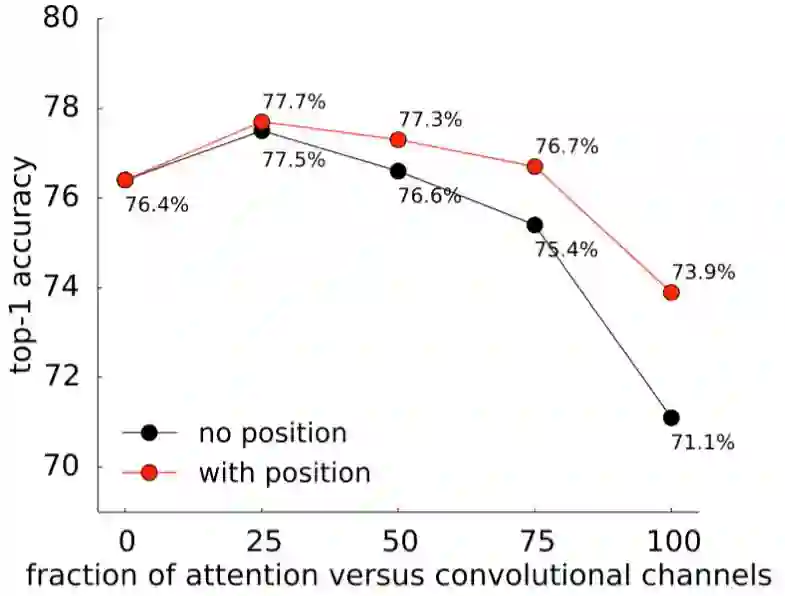
图 5:在我们的注意增强型 ResNet50 上,随注意通道的比例增加的相对位置嵌入的效果。
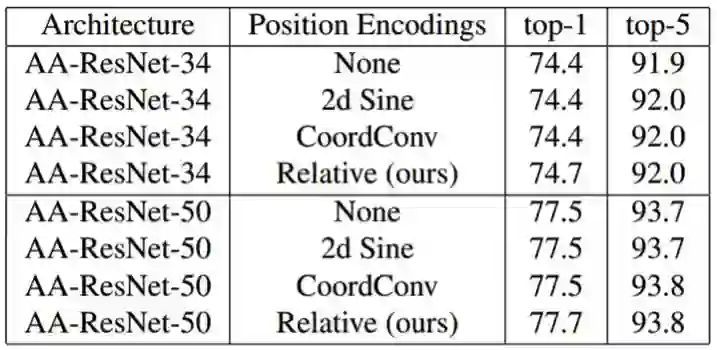
表 6:在 ImageNet 分类上,注意增强中不同位置编码的效果
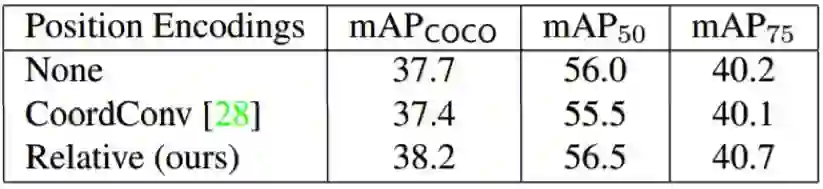
表 7:在 COCO 目标检测任务上,使用 RetinaNet AA-ResNet-50 骨干时注意增强中不同位置编码的效果。
实现
该论文中展示了这一新方法的 TensorFlow 实现。近日,研究者 Myeongjun Kim 开源了其对该方法的 PyTorch 实现。
PyTorch 实现地址:https://github.com/leaderj1001/Attention-Augmented-Conv2d
其中包括两个版本的实现:
论文版本:https://github.com/leaderj1001/Attention-Augmented-Conv2d/blob/master/attention_augmented_conv.py
AA-Wide-ResNet 版本:https://github.com/leaderj1001/Attention-Augmented-Conv2d/blob/master/AA-Wide-ResNet/attention_augmented_conv.py
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



