北航张欢:如何运用深度学习进行位姿测量?| 分享总结

AI 研习社按:位姿测量是许多空间任务的基础,也是移动机器人移动的前提,其重要性不必多言。传统的位姿测量方法已经发展了几十年,取得累累硕果的同时也遇到了不少技术瓶颈。深度学习的兴起,重新给了位姿测量新思路,本文为大家介绍的就是基于深度学习的位姿测量。
在近期AI研习社举办的线上公开课上,来自北京航空航天大学的张欢同学分享了一篇CVPR 2015文章中用到的利用深度学习进行位姿测量的方法。没有观看直播的同学可以点击视频回放(http://www.mooc.ai/open/course/343)。
张欢,北京航空航天大学模式识别与智能系统硕士在读,主要研究方向为计算机视觉,利用深度学习进行非合作目标位姿测量方面,曾带队参加MBZIRC第一届世界无人机大赛。
分享主题:基于深度学习的位姿测量
分享提纲:
位姿测量的意义
传统位姿测量方法的分类和挑战
基于学习的位姿测量方法
基于深度学习的位姿测量方法——描述子网络
物体的位姿测量指的是在特定的坐标系下获取目标的三个位置参数和三个姿态参数,特定的坐标系可以是世界坐标系,物体坐标系,相机坐标系。具体应用领域举例,有卫星辅助入轨,维修故障卫星 ,卫星加注燃料等。

物体的位姿测量的应用

物体的位姿测量在机器人、自动化及机器视觉等领域也有着非常重要的应用,尤其是在机器人领域,准确快速的得到物体的六维位姿对于机器人操作物体是非常重要的。在工业生产中更是如此,准确测量配件的位姿,才能使得工业机器人以规定的姿势抓取物体并对准安装,对于提高工业生产效率有着非常重要的意义。
传统位姿测量方法的分类和挑战
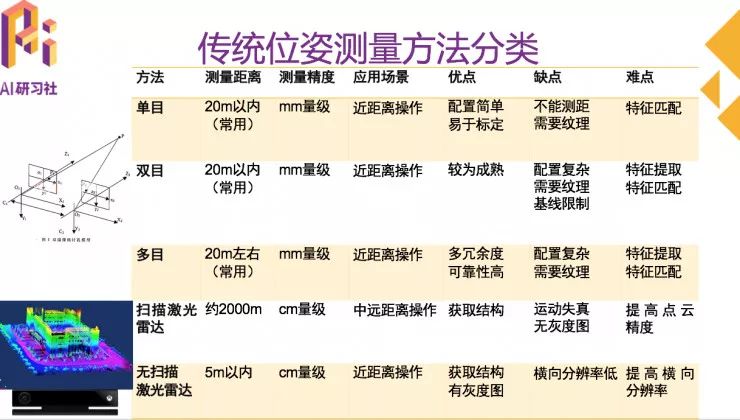
传统的位姿测量方法主要包括基于单目的方法,基于双目的方法,基于多目的方法,基于扫描式激光雷达的方法,基于非扫描式激光雷达的方法,近年来发展迅速的基于SLAM的方法,以及多传感器融合的方法。
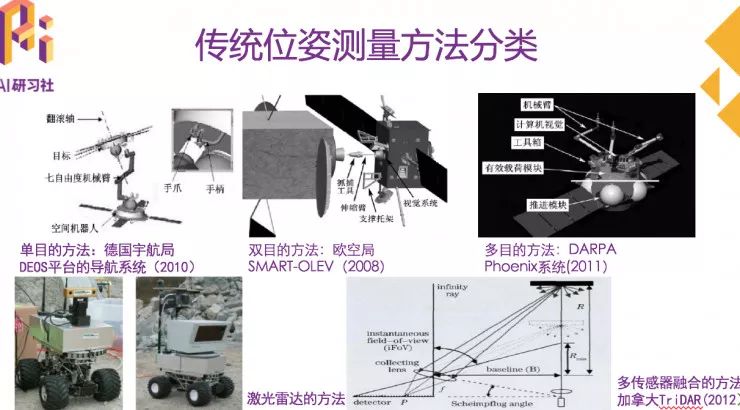
传统位姿测量方法分类
传统位姿测量方法的挑战
传统位姿测量方法的挑战主要包括以下几个方面:
首先,传统的位姿测量方法大多是基于几何特征的方法,而基本的几何方法对于目标表面的纹理具有一定的依赖性,如第一幅图所示。
其次,在真实环境中,由于受到光照等因素影响,相机成像质量会发生退化,基于几何特征的方法容易受到极大影响,如第二幅图所示,空间环境中的成像质量就是非常差的。
第三,复杂的背景也会对基于几何特征的方法产生很大的干扰,第三幅图中的场景是LineMOD数据集,场景比较复杂。
最后,发生局部遮挡等情况下,物体发生了形变,基于几何特征的方法不一定能胜任位姿测量等任务。
而近年来迅速发展的基于学习的算法具有很强的鲁棒性,受环境影响也相对较小,给我们提供了一种新的思路。

基于学习的位姿测量方法
主要包括基于稀疏特征的方法,基于稠密特征的方法,基于模板匹配的方法。

基于稀疏特征的方法从图像中提取兴趣点,用局部描述子来描述这些兴趣点,并匹配到数据库。
Lepetit等把匹配问题转化成分类问题,把物体每个关键点的所有可能的外观集归成一类。每个关键点至少一张样本图,然后根据样本图生成样本集训练分类器,使用随机森林作为分类器,对每个关键点进行分类。
Collet等提出了在混乱的场景中物体识别和位姿测量系统POSESEQ,该系统学习物体特征并制作数据库,运行时检测物体并从数据库中搜索,获取物体6D位姿。针对系统延迟较大的问题,Manuel等人增加了系统的可拓展性。
基于稀疏特征的方法和传统的基于几何的方法有一定的相似性,都是对于纹理较少的物体识别较为困难,对于此类物体的识别,后面介绍的基于模板的方法较好。

基于稠密特征的方法中,用每个像素对想要的结果进行预测,以下是近几年研究方法的发展和改进。

在实际应用中,随机森林的复杂度会随着物体种类的增加而增加;物体种类少的话,训练出的效果又不是很好。这是用三个物体进行训练的训练结果;第一张图是把物体分割出来;第二张图是分割出的物体的能量函数图;第三张图是跑出来的位姿结果;每张图片里左边都是groundtruth,右边是测试结果,估计出来的位姿和groundtruth还是有一定差距的。

基于稀疏特征的方法和基于稠密图像块的方法,也就是随机森林的方法,都是属于学习的方法,但还不是属于深度学习的方法,接下来我们介绍的基于模板匹配的方法是真正属于深度学习的方法。
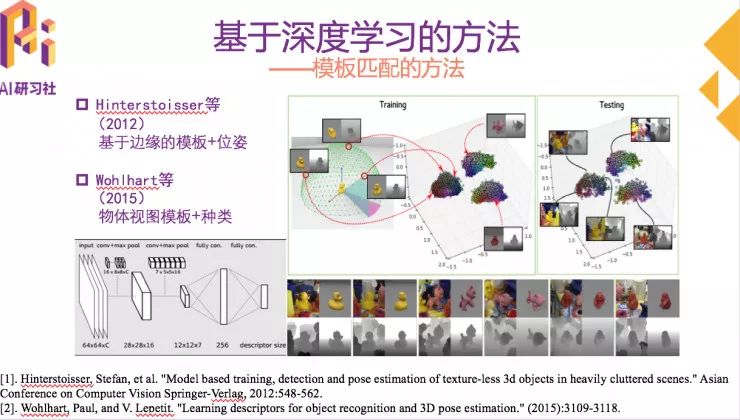
基于模板的方法
基于模板的方法是用固定的模板扫描图片,寻找最佳的匹配。
Hinterstoisser 等研究者对物体在半球节点位置生成大量边缘模板,并把基于边缘的模板和相应的位姿一起进行训练,验证时根据模板进行位姿识别。
在此基础上,Wohlhart等将物体种类和物体视图模板一起进行训练,学习代表物体种类和位姿的描述子。
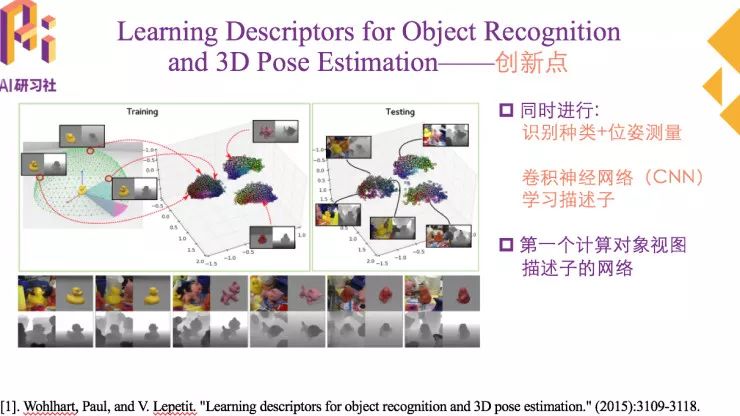
接下来分享的的文章就是学习目标识别和位姿估计的描述子。这是CVPR 2015上收录的一篇文章。
这篇文章的创新点在识别物体种类的同时进行位姿估计。他是通过卷积神经网络学习描述子实现的。这里的描述子不是局部描述子,而是整张图片的描述子。
给定一个物体的输入图像X,想得到他的分类和位姿估计,具体的实现步骤如下图。
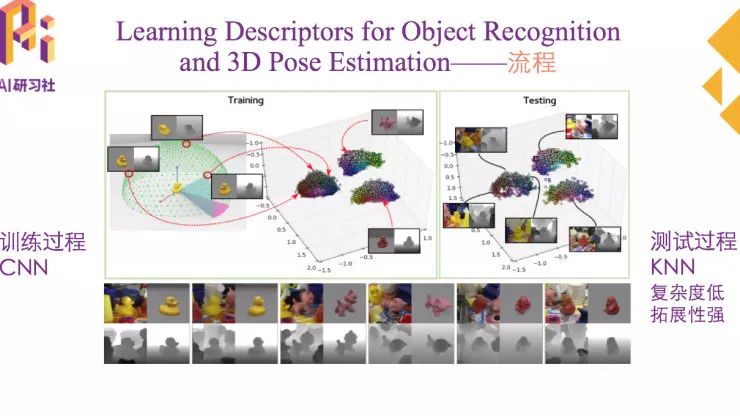
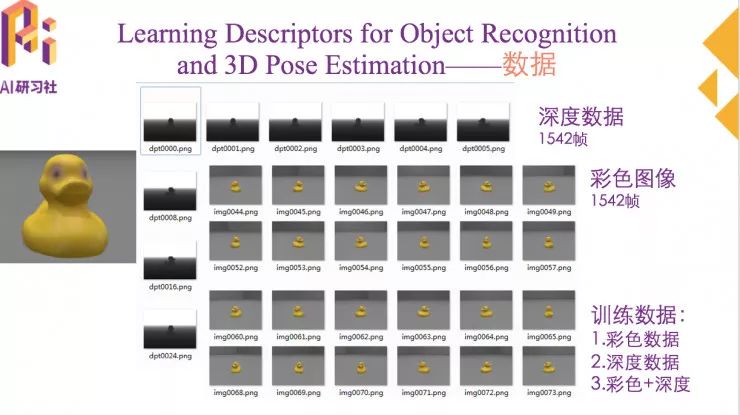
训练数据都是合成数据,训练数据包括彩色图像和深度图像,可以用两种数据一起进行训练,也可以单独指定某一种进行训练。测试数据是真实图像,也包括彩色图像和深度图像。
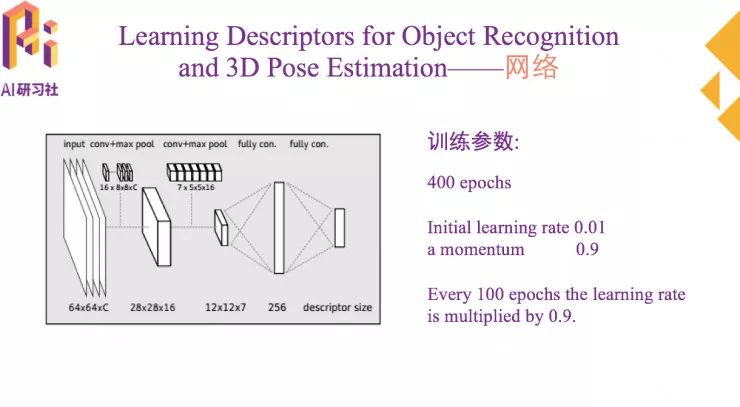
网络主体是一个卷积神经网络,网络的结构比较简单,两个卷基层,一个池化层,两个全连接层。具体的训练参数如图所示:
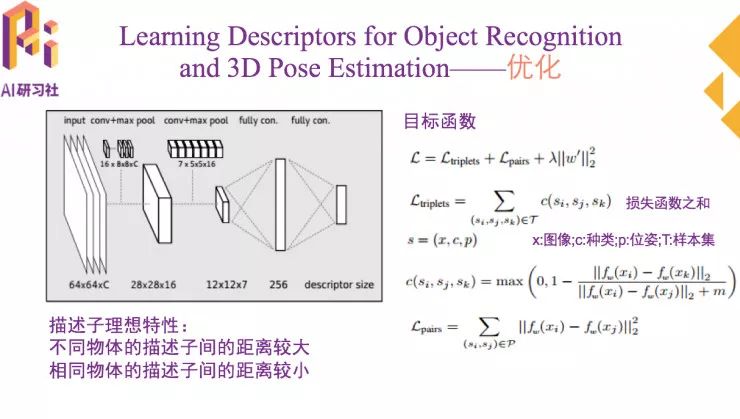
为了实现同时进行识别和位姿测量,想要获得的描述子需要有两个重要特性。不同物体的描述子间的距离较大。相同物体的描述子间的距离较小。
训练样本中,直接小批量训练样本会反复训练,浪费计算资源,因此,网络是按照下图的方法进行训练的。
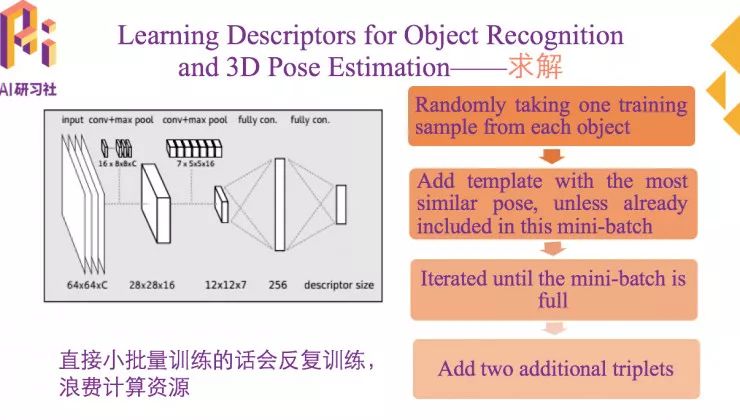
首先从每个物体里随机选取一个训练样本;然后添加训练样本最接近的位姿模板,pairs就是这些最接近的位姿模板和原来随机选取的训练样本产生的;迭代完成,直到小批量总数取满为止。取完之后,在每个训练样本中添加另外的triplets量,来自不同物体最相似的模板或者相同物体位姿差异较大的模板。训练样本取好之后,就可以进行训练了。
以上是网络主体部分介绍,接下来是实验部分。
数据集采用的是Line Mod数据集进行测试,这个数据集有15个物体的视图模板,包括合成数据和真实数据。这个数据集还有物体的精确位姿,需要注意的是数据集里包含常规的物体,也包括水杯,碗这样非常规物体。这样的物体形态具有对称性,测量它的位姿是具有一定挑战的。

具体实验部分,可以观看AI慕课学院公开课视频回放。
总结
最后,总结一下这篇论文提到的基于模板方法的几个缺点,也是基于模板匹配方法的通病:
首先是需要整个模板匹配到一个特定物体,相比之下,基于稀疏特征的方法鲁棒性更强,遮挡情况下不容易匹配到。然后是对于可变性的物体挑战很大,需要大量模板,最后是该方法也容易受到光照等因素影响。
更多公开课直播预告敬请关注「AI 研习社」。如果错过了直播课程,还可到AI慕课学院查找该期的视频回放(http://www.mooc.ai/open/course/343)。


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
人脸检测与识别的趋势和分析
▼▼▼




