【泡泡一分钟】基于合成数据训练的卷积神经网络的目标检测与姿态估计
泡泡一分钟,带你精读机器人顶级会议文章
标题:Object Detection and Pose Estimation Based on Convolutional Neural Networks Trained with Synthetic Data
作者:Josip Josifovski, Matthias Kerzel, Christoph Pregizer, Lukas Posniak, Stefan Wermter
来源:2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
翻译:黄思宇
审核:颜青松
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

基于实际物体的目标检测和精细位姿估计是计算机视觉领域中的研究重点。尽管基于关键点的传统方法可以得到精确的位姿估计,但其在机器人任务上的应用上的适用性依赖于受控环境和有细节信息的刚性物体。另一方面,基于CNN的方法在不受控的环境中的通用的物体识别任务中能得到较好的结果,如基于类别的粗糙的位姿估计,但其需要大量的全标记的训练图像数据集,这不利于采用CNN方法进行实际物体的位姿估计。
我们提出了一种新型的结合CNN的鲁棒性和基于精细分辨率的3D位姿估计方法,该模型在由物体的3D模型自动生成的全标记的合成训练数据上进行训练。我们提出了一个实验配置,来仔细研究利用合成数据训练的模型在真实物体的图像上的识别性能。结果表明,本文提出的模型能够仅通过物体三维模型的合成渲染来训练,并能成功的运用到真实物体的图像上,识别精度适用于一些机器人任务如目标抓取。基于该结果,我们提出了更多关于用合成图像训练神经模型的一般见解,以便应用于真实世界的图像。
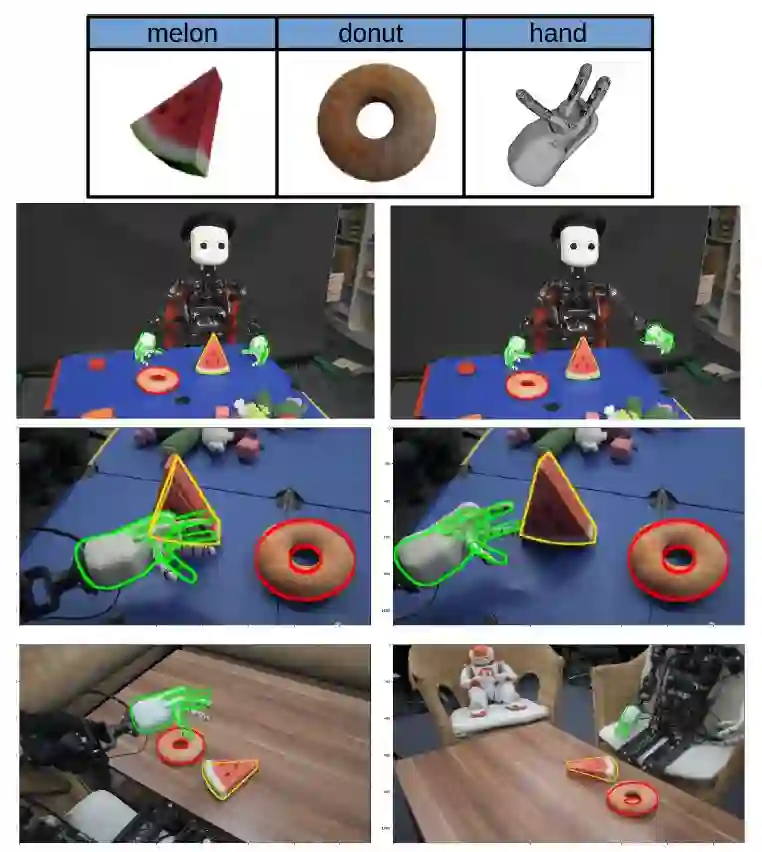
图1 顶部为用来产生合成训练数据集的3D模型,底部为用本文方法估计的3D物体的位姿和机械抓手
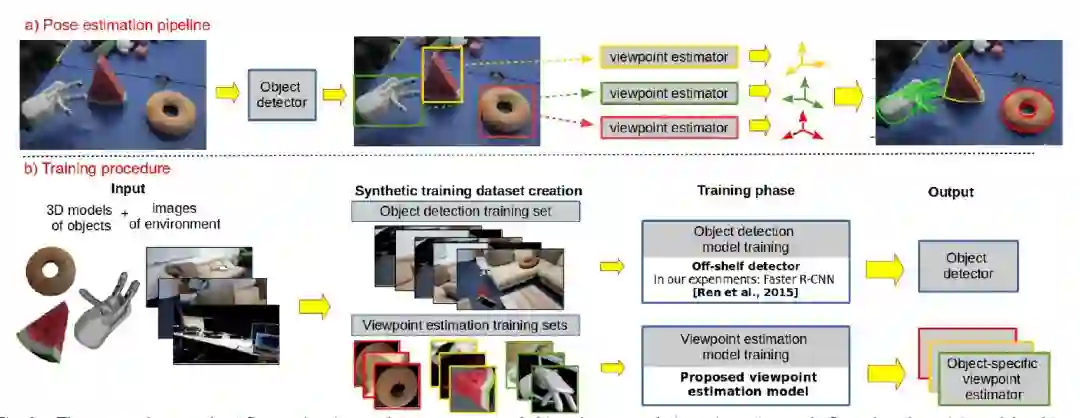
图2 顶部为位姿估计模型构成,包含一系列物体检测器和视角估计器,底部为训练物体检测器和视角估计器的流程。
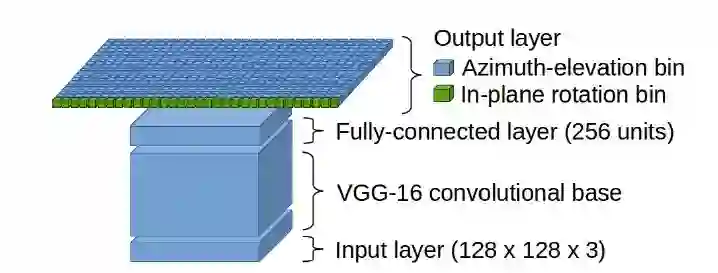
图3 本文提出的基于CNN的视角估计器的网络架构
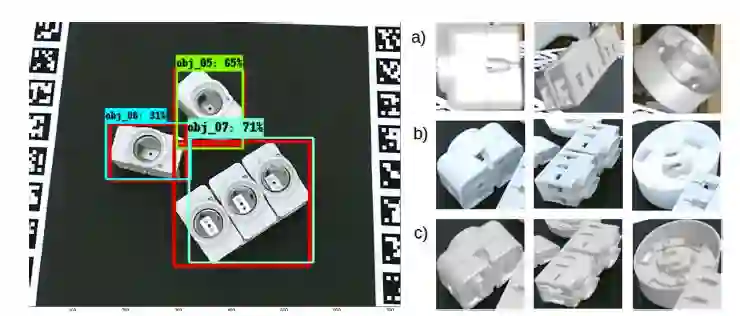
图4 左为用本模型对T-LESS数据集中图片进行目标检测的结果,右为视角估计器实验中用到的一些示例图片,a)合成训练图像,b)不包含bounding box的真实测试图像中的物体,c)根据真实测试图像中生成的合成测试图像。

Abstract
Instance-based object detection and fine pose estimation is an active research problem in computer vision. While the traditional interest-point-based approaches for pose estimation are precise, their applicability in robotic tasks relies on controlled environments and rigid objects with detailed textures. CNN-based approaches, on the other hand, have shown impressive results in uncontrolled environments for more general object recognition tasks like category-based coarse pose estimation, but the need of large datasets of fully-annotated training images makes them unfavourable for tasks like instance-based pose estimation.
We present a novel approach that combines the robustness of CNNs with a fine-resolution instance-based 3D pose estimation, where the model is trained with fully-annotated synthetic training data, generated automatically from the 3D models of the objects. We propose an experimental setup in which we can carefully examine how the model trained with synthetic data performs on real images of the objects. Results show that the proposed model can be trained only with synthetic renderings of the objects’ 3D models and still be successfully applied on images of the real objects, with precision suitable for robotic tasks like object grasping. Based on the results, we present more general insights about training neural models with synthetic images for application on real-world images.
如果你对本文感兴趣,请点击点击阅读原文下载完整文章,如想查看更多文章请关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
百度网盘提取码:xpys
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


