
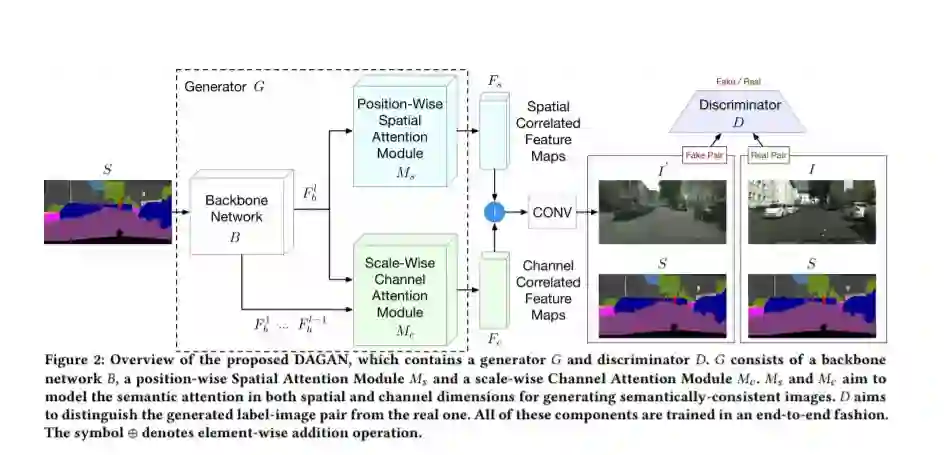
在本文中,我们关注的是语义图像合成任务,目的是将语义标记映射迁移到逼真的图像。现有的方法在保留语义信息方面缺乏有效的语义约束,忽略了空间维度和通道维度上的结构相关性,导致结果模糊且容易产生假象。为了解决这些限制,我们提出了一种新的对偶注意力GAN (DAGAN),它可以合成具有输入布局细节的真实照片和语义一致的图像,而不增加额外的训练开销或修改现有方法的网络结构。我们还提出了两个新的模块,即位置-方向的空间注意力模块和尺度-方向的通道注意模块,分别用于捕获空间和通道维度上的语义结构注意力。具体来说,SAM通过空间注意力图选择性地将每个位置的像素关联起来,从而使得具有相同语义标签的像素无论在空间上的距离如何都相互关联起来。同时,CAM通过通道注意力图选择性地强调每个通道上的标度特征,从而在所有的通道图中集成相关的特征,而不管它们的标度如何。最后对SAM和CAM的结果进行求和,进一步改进特征表示。在四个具有挑战性的数据集上进行的广泛实验表明,DAGAN取得了比最先进的方法显著更好的结果,同时使用更少的模型参数。源代码和经过训练的模型可以在这个https URL中获得。
https://arxiv.org/abs/2008.13024
成为VIP会员查看完整内容
相关内容
Arxiv
4+阅读 · 2020年2月27日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2020年2月27日