【速览】ACM MM 2021丨跨模态压缩:一种基于跨模态的图像-文本语义压缩框架
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
跨模态压缩:一种基于跨模态的图像-文本语义压缩框架
通讯作者:贾川民
◆ ◆ ◆ ◆
近年来图像、视频数据的信息量呈指数级提升,尤其是用于机器分析的数据量相较以往显著增加。因此,在图像/视频等数据的压缩框架中,语义保真相比传统的信号保真变得越来越重要(不同保真的对比如图1所示)。因为信号保真是面向信号层面的,也与机器分析的要求有明显的差异,所以广泛使用信号保真的传统的压缩方法与机器分析的要求并不一致。除此之外,场景视频的语义信息,例如行人相关的身份,数量,或者车辆的流量等,而不是原始的场景图像,也变得越来越重要,这一类需求称之为语义监督。然而,传统的基于块划分的图像/视频压缩框架主要在特定码率约束下优化数据的信号保真,已经不能满足日益增加的机器分析和语义监督的需求。近期的特征压缩的框架将深度神经网络的中间层或者最终层的特征通过量化,压缩和熵编码来将重点放在语义特征上。但是特征压缩有如下不足之处:(1)它一般面向具体的任务,换一个任务往往需要使用新的特征;(2)这种特征一般是人不可理解的,所以不能用于相关的语义监督;(3)如何从这种任务相关的特征中重构出原始的数据,依然有待研究。为了弥补以上不足,本文尝试提出一种人可以理解的语义压缩框架:跨模态压缩。
跨模态压缩将高语义冗余的数据(例如图像,视频等)压缩到一个语义紧凑的、通用的、人可理解的压缩域中(例如文本,语义图,素描图等)。它具有如下特点:(1)可以在满足一定语义保真的前提下实现超高的压缩率;(2)这种通用的紧凑表示可以用于多种分析任务,而不需要将原始数据重构出来;(3)这种紧凑的表示是人可理解的,所以可以直接用于语义监督;(4)在有必要的时候,可以结合生成模型从压缩域将原始的图像或视频重构出来。

图 1:不同类型的保真度量
跨模态压缩与传统的图像/视频压缩框架是基于块的混合编码框架,最终层特征压缩(Ultimate Feature Compression),中间层特征压缩(Intermedia Feature Compression)等之间的不同特点如表1所示。
表 1:跨模态压缩与其它几种压缩框架的比较
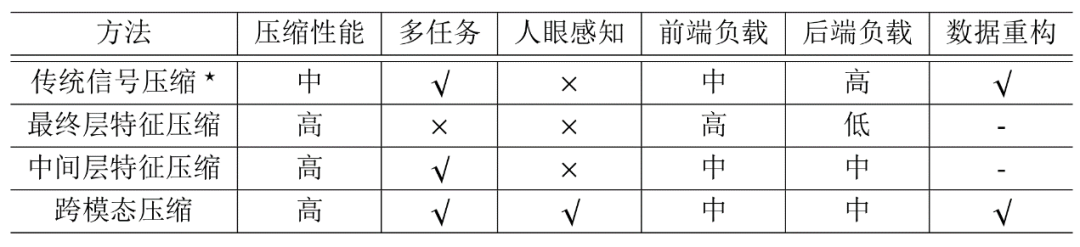
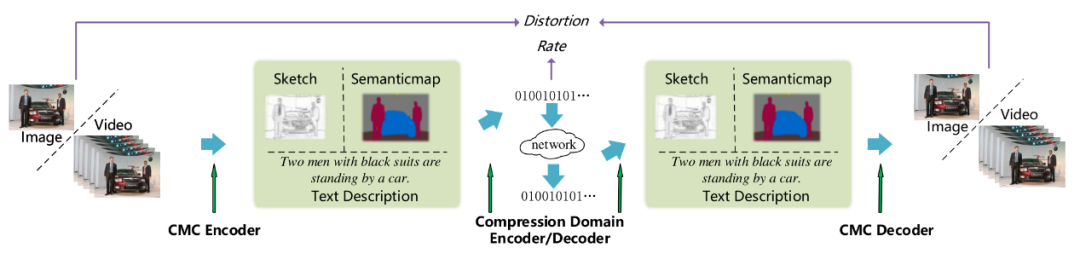
图 2:本文所提的跨模态压缩框架示意图
数据压缩的目标是在特定保真下降低数据传输和存储的代价,优化目标可以表示为:
其中
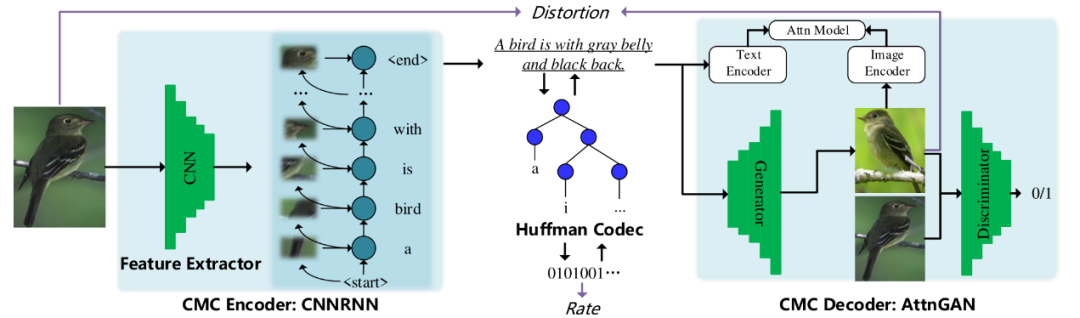
图 3:图像-文本-图像的跨模态压缩框架
本节介绍跨模态压缩的一种具体实现:图像-文本-图像的跨模态压缩框架,如图3所示。借助于图像到文本翻译在近期的进展,理解一幅图像并用合乎语法的文本描述出来已经可以实现。同时,近期在文本到图像的翻译上的相关工作,也使得从文本中合成语义一致的图像逐渐成为可能。在跨模态压缩的实现中,通过定义压缩域
跨模态编码器用于将图像/视频数据压缩到一个紧凑的表示域,在图像-文本-图像跨模态压缩中这个压缩域是指文本域。本文使用一个基于卷积神经网络,循环神经网络和注意力机制的方法[6]来实现跨模态编码器。压缩域的表示被认为是语义紧凑的,特别是相比于原始的数据域来说。将数据从原始数据域压缩到语义紧凑的压缩域,已经除去了大部分的语义冗余。但是,在压缩域中,依然存在大量的统计冗余。根据香农信息论[4],如果一个字符出现的概率是
跨模态解码器用于从压缩域表示重构数据。在所设计的图像-文本-图像跨模态压缩框架中,跨模态解码器需要从文本表示中重构图像。基于近几年图像到文本翻译的进展,此处使用基于注意力机制的文本到图像的翻译模型AttnGAN[8]来实现跨模态解码器。
实验在文本到图像翻译的常用数据集MS COCO[11]和CUB-200[10]上进行。同时使用了四种不同层次的评价指标来评估模型的性能。使用感知得分(Inception Score, IS)评估生成图像在特征空间中的分布以及其边缘分布的距离来评估生成图像的真实性和多样性,其次是Fréchet起始距离(Fréchet Inception Distance, FID)通过评估生成图像和真实图像在特征分布上的距离,来评估生成图像和真实图像的相似度。同时,为了评估样本级别的相似性,本文还提出使用样例感知距离(Instance Perceptual Distance)来度量合成样本和真实样本在特征空间的距离,从而评估两者在样本级别的相似性。除了以上三个,实验中还报告了传统图像/视频压缩中信号层面的误差。
因为IS和FID都是在集合上定义的评价指标,都不能对样本级别的真实性做度量,所以本文在这里提出了IPD。IPD被定义为:
其中
本文在MS COCO数据集和CUB-200数据集上的实验结果如图4所示。从图中结果可以看出,本文所提的图像-文本-图像跨模态压缩可以在CUB-200数据集上在实例层面重构输入图像,同时取得超高的压缩率,在MS COCO数据集上在实例层面部分重构输入图像,同时取得超高的压缩率。

图 4:图像-文本-图像的跨模态压缩框架在CUB200数据集(左)和MS COCO数据集(右)上的主观结果以及压缩倍数
为了定量评估本文所提出的框架的性能,本文将所提的图像-文本-图像跨模态压缩框架与目前使用的JPEG[1]和JPEG 2000[2]图像压缩标准进行了对比。通过设置不同的压缩质量,将测试集所有的图像用不同的压缩参数进行压缩并统计在整个测试集上的平均码率和平均畸变(畸变由前文所述的四种评价指标度量),可以得到一条码率-失真曲线(R-D curve),就像传统视频压缩中的性能曲线一样。实验结果如图5所示,在四个质量评价指标中,IS和FID是在集合层面的评价指标,IPD是样本/实例层面的评价指标,PSNR是像素级失真的评价指标。从图中的结果可以得出,本文所提的图像-文本-图像跨模态压缩框架在集合层面和实例层面可以取得和JPEG2000相当的性能,同时取得超高的压缩率。另一方面,在像素保真层面,本文所提方法暂时优势不大,最主要的原因是本文的生成模型没有考虑像素级的优化。
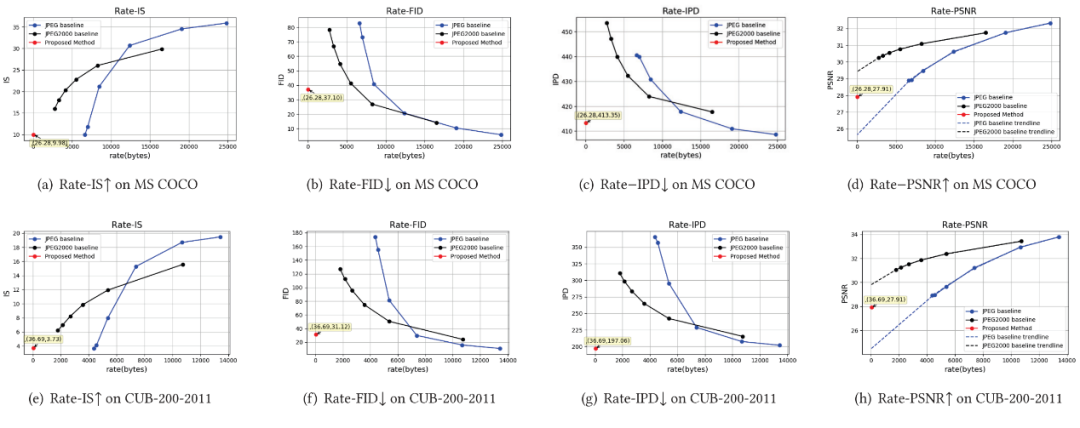
图 5:图像-文本-图像的跨模态压缩框架与JPEG和JPEG2000的比较结果
本文提出了跨模态压缩(Cross Modal Compression, CMC)的概念和框架,它是一种跨模态图像-文本的语义压缩框架。与前面的传统信号压缩,特征压缩等框架比较,跨模态压缩具有压缩域可理解,支持多任务分析,超高压缩率等特点。同时,本文还提出一个面向图像压缩的跨模态压缩一种具体实现:图像-文本-图像的跨模态压缩框架。相关的定性实验和定量实验说明所提的图像-文本-图像跨模态压缩框架在相关数据集上可以在集合和实例层面超过JPEG,并取得和JPEG2000相当的性能。相关实验证明了跨模态压缩框架在某些只要求集合和实例层面语义保真,但是要求超高压缩率的应用场合的应用前景,例如在极低带宽下的图像/视频的传输。
尽管取得了一定的进展,跨模态压缩依然是一个初步的概念和方法,依然有很多不够完善的方面。在未来的工作中,将对跨模态压缩在端到端优化,可伸缩的压缩,基于语义的度量指标,泛化性更强的跨模态压缩框架等方面做继续的完善和改进。
[1] Wallace G K. Overview of the JPEG still image compression standard[C]//Image Processing Algorithms and Techniques. International Society for Optics and Photonics, 1990, 1244: 220-233.
[2] Marcellin M W, Gormish M J, Bilgin A, et al. An overview of JPEG-2000[C]//Proceedings DCC 2000. Data Compression Conference. IEEE, 2000: 523-541.
[3] Vinyals O, Toshev A, Bengio S, et al. Show and tell: A neural image caption generator[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3156-3164.
[4] Shannon C E. A mathematical theory of communication[J]. ACM SIGMOBILE mobile computing and communications review, 2001, 5(1): 3-55.
[5] Huffman D A. A method for the construction of minimum-redundancy codes[J]. Proceedings of the IRE, 1952, 40(9): 1098-1101.



