【速览】ACM MM 2021 | 聚焦于人物:从现代历史电影中学习为老照片着色
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
聚焦于人物:从现代历史电影中学习为老照片着色
通讯作者:邹冬青
◆ ◆ ◆ ◆
目前,现有的着色方法在老照片人物服饰着色问题上无法取得令人满意的效果,主要有以下原因:
1、传统的着色方法[1,2,3,4]提出了具有输入文本语义和语言描述的方法。尽管这些方法包含了参考图片的语义分割信息,但它们忽略了背景和人物的边界,并且也不考虑人像中各个部分的解析;
2、随着深度学习的进步,许多研究使用CNN或GAN来提取灰度图片的信息以用于着色。这些方法往往实现了自然颜色匹配。但忽略了颜色分布的客观事实。
3、目前大多数的着色图片数据集缺少真实历史灰度图片的内容和信息,特别是关于老照片人物的服装颜色信息。
为了解决这些缺点,基于细粒度语义解析和先验知识,本文创新地提出了HistoryNet框架和MHMD数据集。HistoryNet包含三部分:分类网络、细粒度语义解析网络和着色网络。MHMD数据集包含1353166张图片,并根据年代、民族和服装类型可划分为42类。我们使用HistoryNet在MHMD上经过训练,最终可以达到一个理想的着色效果。
HistoryNet的网络结构示意图如图2-1所示。
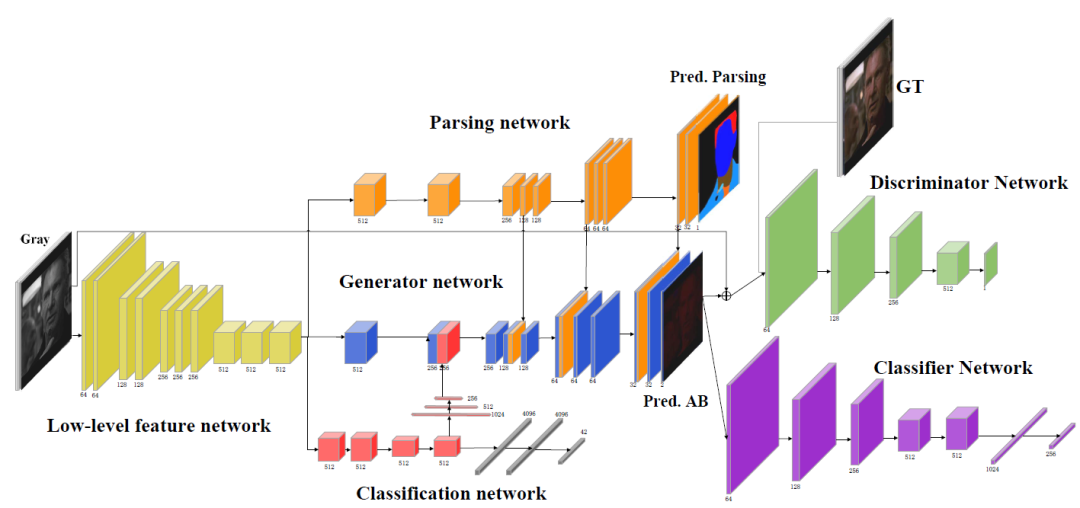
图 2-1 HistoryNet网络示意图
HistoryNet网络结构主要包含低水平的特征提取网络、分类网络、生成器网络、细粒度语义解析网络、鉴别器网络和分类器网络。
生成器网络旨在实现真实的着色效果,它的损失函数定义为:
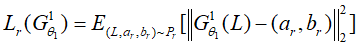
细粒度语义解析网络利用获得的人物图片进行细粒度语义解析,它可以将人物的各部分如脸、帽子、手、衣服等分离,使着色边界清晰准确,它的损失函数定义为:
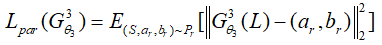
分类网络旨在获得照片的高水平特征和着色的种类标签。分类网络一部分包含代表例如年代、民族、服饰类型等标签的向量,以此提高生成器网络着色的准确性;另一部分得到分类器网络对应的向量来计算损失函数,实现图片的正确着色,该损失函数定义如下:
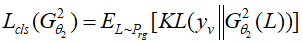
鉴别器网络旨在保持训练过程稳定并获得更好的着色照片。使用Kan-torovich-Rubinste对偶[5,6]并添加梯度惩罚项来约束鉴别器相对于其输入的范数。
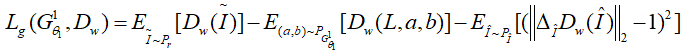
分类器网络旨在避免人物老照片中由于年代、民族、服饰类型多样性造成的着色失真。分类器利用InfoGAN[13]充分利用图像信息可以实现更好的效果。分类器的损失函数定义如下:
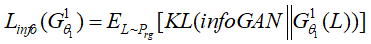
上述所有结构构成HistoryNet,总体的损失函数定义如下:
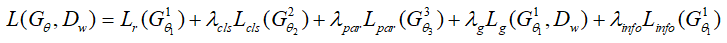
在训练过程中,超参数取值如下:
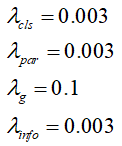
为了获得更好的着色效果,本文创新地提出了一个新的数据集——现代历史电影数据集(Modern Historical Movies Dataset: MHMD)。该数据集来源于147部现代历史电影和电视剧,并经过预处理后,得到最终的数据集。MHMD根据年代、民族和服饰类型可以划分为42类,总计1,353,166张图片。标签的详细分类有助于网络结构获得准确的信息。图片标签的结构如下:
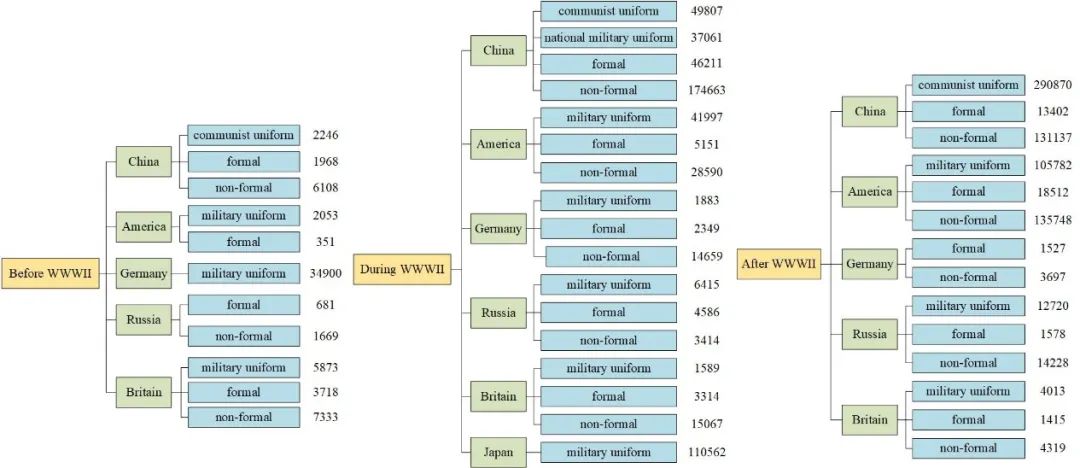
图 4-1 数据集标签结构分布图
本文在现代历史电影数据集上对提出的算法进行了测试与验证。为了证明提出方法的效果优良,我们进行了定量对比实验、消融实验和定性对比实验。
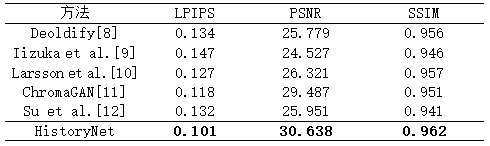
通过三个指标:LPIPS[7],PSNR和SSIM,将HistoryNet与其他着色方法Deoldify[8],Iizuka et al.[9],Larsson et al.[10],ChromaGAN[11],Su et al.[12]进行了定量对比,实验结果如表5-1所示。
表 5-1 定量对比实验结果
我们随机选取一些图片用HistoryNet与其他着色方法进行对比,如图5-1所示,相比于其他方法,HistoryNet的着色效果与原图更为接近。

图 5-1 对比实验效果展示
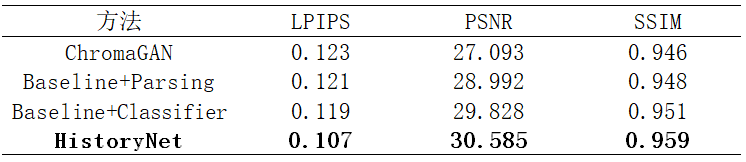
我们以ChromaGAN为基准进行消融实验,实验结果如表5-2所示。
表 5-2 消融实验
我们分别使用Human Parsing[14]和Deeplab-v3[7]进行语义分割。Deeplab-v3[7]只对人物和背景进行了区分,但不能对人物的脸和手等各个部分进行具体分割。因此,我们采用实例级人像解析[14]进行语义分割,重点识别手臂、头发等各个语义部分。Human Parsing[14]和Deeplab-v3[7]的分割效果如图5-2所示。

图 5-2 Human Parsing与Deeplab-v3对比
我们所设计的MHMD适用于历史图像的上色,特别是军装和历史图像。此外,我们的方法也可以用于去除历史图片的背景噪声,并使泛黄的背景颜色恢复为正常颜色。如图5-3所示。

图 5-3 老照片颜色修正
我们还为一些遗留的黑白图像着色。如图5-4所示,我们的着色方法对于黑白照片具有很好的着色效果。

图 5-4 黑白历史图像着色
在本文中,我们提出了一个新的HistoryNet网络结构,它包含语义解析、分类和着色子网络。语义解析子网络可以提高着色边界的准确性。分类子网络可以帮助选择正确的颜色。此外,我们还提出了一个名为MHMD的数据集,该数据集来源于真实的灰色历史图像。据我们所知,所提出的MHMD数据集是目前历史图像着色领域最大的数据集。通过相关的定性和定量实验比较,我们的方法在LPIPS、PSNR、SSIM等方面都优于目前最先进的着色网络。希望我们的工作可以激励更多的研究人员在历史图像/视频着色技术方面做出贡献。
[1] Hyojin Bahng, Seungjoo Yoo, Wonwoong Cho, David Keetae Park, Ziming Wu,Xiaojuan Ma, and Jaegul Choo. 2018. Coloring with words: Guiding imagecolorization through text-based palette generation. In Proceedings of the europeanconference on computer vision (eccv).431–447.
[2] Jianbo Chen, Yelong Shen, Jianfeng Gao, Jingjing Liu, and Xiaodong Liu. 2018.Language-based image editing with recurrent attentive models.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 8721–8729.
[3] Chenxi Liu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, and Alan Yuille. 2017. Rcurrent multimodal interaction for referring image segmentation. In Proceedings of the IEEE International Conference on Computer Vision. 1271–1280.
[4] Varun Manjunatha, Mohit Iyyer, Jordan Boyd-Graber, and Larry Davis. 2018. Learning to color from language. arXiv preprint arXiv:1804.06026 (2018).
[5] Leonid Kantorovitch. 1958. On the translocation of masses. Management Science 5,1(1958),1–4.





