超强半监督学习 MixMatch
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | hahakity
来源 | https://zhuanlan.zhihu.com/p/66281890
已获作者授权,请勿二次转载
人类的学习方法是半监督学习,他们能从大量的未标记数据和极少量的标记数据学习,迅速理解这个世界。半监督学习最近有没有什么大的突破呢?我的Twitter账号被这篇 《The Quiet Semi-Supervised Revolution》【1】博客刷屏了。这篇博客介绍了 DeepMind 的 MixMatch 【2】方法,此方法仅用少量的标记数据,就使半监督学习的预测精度逼近监督学习。深度学习领域的未来可能因此而刷新。
以前的半监督学习方案,一直以来表现其实都很差。你可能会想到 BERT 和 GPT,这两个超强的自然语言预训练模型。但这两个模型的微调只能算迁移学习,而非半监督学习。因为它们最开始训练的时候,使用了监督学习方法。比如通过语言模型,输入前言,预测后语;输入语境,完形填空;输入前言和后语,预测是否前言不搭后语。这几种方法,很难称作无监督学习。
下面这几种大家很容易想到的半监督学习方法,效果都不是很好。比如使用主成分分析PCA,提取数据中方差最大的特征,再在少量标记数据上,做监督学习;又比如使用自编码机 AutoEncoder,以重建输入图像的方式,获得数据潜在表示,对小数据监督学习;再比如使用生成对抗网络 GAN,以生成以假乱真图像的方式,获得数据潜在表示,对小数据做监督学习。半监督训练很久的精度,还比不上直接在小数据上做监督学习的精度!大家的猜测是,这些非监督方法学到的特征可能并不是分类器真正需要的特征。
什么才是半监督学习的正确打开方式呢?近期的一些半监督学习方法,通过在损失函数中添加与未标记数据相关的项,来鼓励模型举一反三,增加对陌生数据的泛化能力。
第一种方案是自洽正则化(Consistency Regularization)【3,4】。以前遇到标记数据太少,监督学习泛化能力差的时候,人们一般进行训练数据增广,比如对图像做随机平移,缩放,旋转,扭曲,剪切,改变亮度,饱和度,加噪声等。数据增广能产生无数的修改过的新图像,扩大训练数据集。自洽正则化的思路是,对未标记数据进行数据增广,产生的新数据输入分类器,预测结果应保持自洽。即同一个数据增广产生的样本,模型预测结果应保持一致。此规则被加入到损失函数中,有如下形式,

其中 x 是未标记数据,Augment(x) 表示对x做随机增广产生的新数据, 
MixMatch 集成了自洽正则化。数据增广使用了对图像的随机左右翻转和剪切(Crop)。
第二种方案称作 最小化熵(Entropy Minimization)【5】。许多半监督学习方法都基于一个共识,即分类器的分类边界不应该穿过边际分布的高密度区域。具体做法就是强迫分类器对未标记数据作出低熵预测。实现方法是在损失函数中简单的增加一项,最小化 
MixMatch 使用 "sharpening" 函数,最小化未标记数据的熵。这一部分后面会介绍。
第三种方案称作传统正则化(Traditional Regularization)。为了让模型泛化能力更好,一般的做法对模型参数做 L2 正则化,SGD下L2正则化等价于Weight Decay。MixMaxtch 使用了 Adam 优化器,而之前有篇文章发现 Adam 和 L2 正则化同时使用会有问题,因此 MixMatch 从谏如流使用了单独的Weight decay。
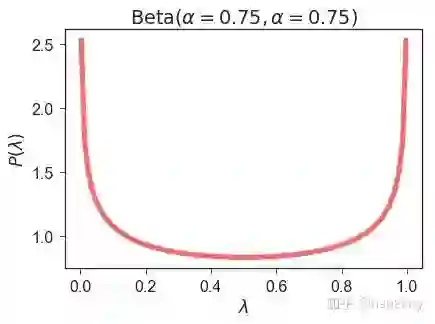
最近发明的一种数据增广方法叫 Mixup 【6】,从训练数据中任意抽样两个样本,构造混合样本和混合标签,作为新的增广数据,
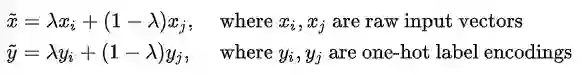
其中 
MixMatch 方案
MixMatch 偷学各派武功,取三家之长,补三家之短,最终成为天下第一高手 -- 最强半监督学习模型。这种 MixMatch 方法在小数据上做半监督学习的精度,远超其他同类模型。比如,在 CIFAR-10 数据集上,只用250个标签,他们就将误差减小了4倍(从38%降到11%)。在STL-10数据集上,将误差降低了两倍。 方法示意图如下,
 MixMatch 实现方法:对无标签数据,做数据增广,得到 K 个新的数据。因为数据增广引入噪声,将这 K 个新的数据,输入到同一个分类器,得到不同的预测分类概率。MinMax 利用算法(Sharpen),使多个概率分布的平均(Average)方差更小,预测结果更加自洽,系统熵更小。
MixMatch 实现方法:对无标签数据,做数据增广,得到 K 个新的数据。因为数据增广引入噪声,将这 K 个新的数据,输入到同一个分类器,得到不同的预测分类概率。MinMax 利用算法(Sharpen),使多个概率分布的平均(Average)方差更小,预测结果更加自洽,系统熵更小。
注:Google原文并未比较 MixMatch 和使用生成对抗网络GAN做半监督学习时的表现孰好孰坏。但从搜索到的资料来看,2016年 OpenAI 的 Improved GAN 【8】,使用4000张CIFAR10的标记数据,做半监督学习得到测试误差18.6。2017年,GAN做半监督学习的测试误差,在4000张CIFAR10标记数据上,将测试误差降低到14.41 【10】。2018年,GAN + 流形正则化,得到测试误差14.45。目前并没有看到来自GAN的更好结果。对比 MixMatch 使用 250 张标记图片,就可以将测试误差降低到 11.08,使用4000张标记图片,可以将测试误差降低到 6.24,应该算是大幅度超越使用GAN做半监督学习的效果。
具体步骤:
使用 MixMatch 算法,对一个 Batch 的标记数据
和一个 Batch 的未标记数据
做数据增广,分别得到一个 Batch 的增广数据
和 K 个Batch的
。



其中 T, K, 

算法描述:for 循环对一个Batch的标记图片和未标记图片做数据增广。对标记图片,只做一次增广,标签不变,记为 






2. 对增广后的标记数据
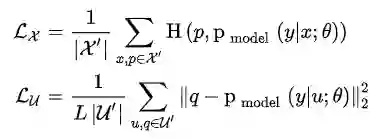
其中 




对未标记数据损失 



而 softmax 函数对于常数叠加不敏感,即如果将最后一个 Dense Layer 的所有输出类分数

因此,如果对未标记数据使用 Cross Entropy Loss, 由同一张图片增广得到的两张新图片,最后一个Dense Layer的输出被允许相差一个常数。使用 L2 Loss, 约束更加严格。
3. 最终的整体损失函数是两者的加权,

其中 

在上面的步骤描述中,还有另外两个超参数,温度 T 和
不是说未标记数据没标签吗?我们可以用分类器“猜测”一些标签。算法描述中的这一步,就是分类器对 K 次增广的无标签数据分类结果做平均,猜测的“伪”标签。对应示意图中 Average 分布。但这个平均预测分布比较平坦,就像在猫狗二分类中,分类器说,这张图片中 50% 几率是猫,50%几率是狗一样,对各类别分类概率预测比较平均。

MixMatch 使用了 Sharpen,来使得“伪”标签熵更低,即猫狗分类中,要么百分之九十多是猫,要么百分之九十多是狗。做法也是前人发明的,

其中, 




最后一个尚未解释的超参数
MixMatch 修改了 Mixup 算法。对于两个样本以及他们的标签 


其中,权重因子 
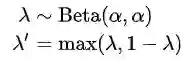
文章使用超参数 
原始的 Mixup 算法中,第一步不变,第二步 




细节:损失函数中使用了对未标记数据猜测的标签
半监督学习 MixMatch 训练结果
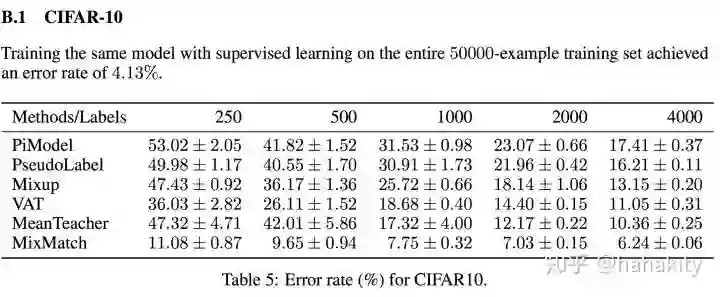
更直观的效果对比
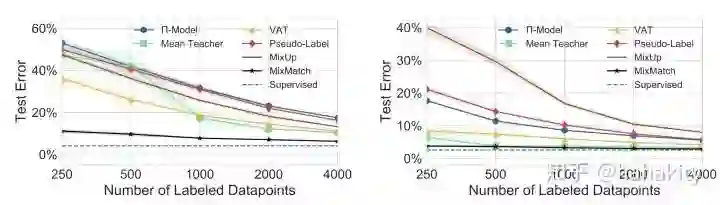
解剖各部分贡献 (Ablation Test )
结论:
半监督学习是深度学习里面最可能接近人类智能的方法。这个方向的进展,这篇文章的突破,都是领域的极大进展。因未在其他公众号看到这篇文章的介绍,特此作此解读。
另有一篇文章,Unsupervised Data Augmentation,貌似在4000张标记图片的CIFAR10上达到了 5.27 的测试误差,超过了 MixMatch 方法。如有时间,会进一步解读那篇文章。以观察两篇文章的方法是否可以一同使用。
参考文献:
【1】https://towardsdatascience.com/the-quiet-semi-supervised-revolution-edec1e9ad8c
【2】https://arxiv.org/pdf/1905.02249.pdf
【3】https://arxiv.org/abs/1610.02242 . ICLR, 2017.
【4】https://arxiv.org/pdf/1606.04586.pdf. NIPS, 2016.
【5】https://papers.nips.cc/paper/2740-semi-supervised-learning-by-entropy-minimization.pdf
【6】https://arxiv.org/pdf/1710.09412.pdf
【7】https://arxiv.org/pdf/1804.09170.pdf
【8】https://papers.nips.cc/paper/6125-improved-techniques-for-training-gans.pdf ,
OpenAI 2016, get 18.6 test error using 4000 labeled images in CIFAR10.
【9】https://arxiv.org/pdf/1805.08957.pdf, 2018, GAN + Manifold Regularization, get 14.45 test error using 4000 labeled images in CIFAR10.
【10】https://www.cs.cmu.edu/afs/cs/Web/People/wcohen/postscript/nips-2017-badgan.pdf , 2017, get 14.41 test error using 4000 labeled images in CIFAR10.
【11】[free online book]
http://www.acad.bg/ebook/ml/MITPress-%20SemiSupervised%20Learning.pdf
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~



