深度思考 | 从BERT看大规模数据的无监督利用

作者丨金立达,吴承霖
机构丨笨鸟社交 AI Lab
学校丨英国帝国理工学院
研究方向丨自然语言处理、知识图谱
在击败 11 个 NLP 任务的 State-of-the-art 结果之后,BERT 成为了 NLP 界新的里程碑, 同时打开了新的思路: 在未标注的数据上深入挖掘,可以极大地改善各种任务的效果。数据标注是昂贵的,而大量的未标注数据却很容易获得。
在分类中,标签表示训练示例所属的类; 在回归中,标签是对应于该示例的实值响应。 大多数成功的技术,例如深度学习,需要为大型训练数据集提供 ground truth 标签;然而,在许多任务中,由于数据标注过程的高成本,很难获得强有力的监督信息。 因此,希望机器学习技术能够在弱监督下工作。
这不可避免地导致我们重新考虑弱监督学习的发展方向。 弱监督学习的主要目标是仅使用有限量的标注数据,和大量的未标注数据,来提升各项任务的效果。
弱监督最大的难点在于如何用少量的标注数据,和为标注数据来有效地捕捉数据的流形。目前的一些解决方案在面对复杂的数据时,比较难准确地还原数据的流形。但是 BERT 通过大量的预训练,在这方面有着先天的优势。
因而,BERT 凭借对数据分布的捕获是否足以超越传统半监督的效果?又或者,BERT 能否有与半监督方法有效地结合,从而结合两者优势?
弱监督
通常,有三种类型的弱监督。第一种是不完全监督,即只有一个(通常很小的)训练数据子集用标签给出,而其他数据保持未标注。 这种情况发生在各种任务中。 例如,在图像分类中,ground truth 标签由人类注释者给出;很容易从互联网上获取大量图像,而由于人工成本,只能注释一小部分图像。
第二种类型是不精确监督,即仅给出粗粒度标签。 再次考虑图像分类任务。 期望使图像中的每个对象都注释;但是,通常我们只有图像级标签而不是对象级标签。
第三种类型是不准确监督,即给定的标签并不总是真实的。 出现这种情况,例如当图像注释器粗心或疲倦时,或者某些图像难以分类。
对于不完全监督,在这种情况下,我们只给予少量的训练数据,并且很难根据这样的小注释来训练良好的学习 然而,好的一面是我们有足够的未标注数据。 这种情况在实际应用中经常发生,因为注释的成本总是很高。
通过使用弱监督方法,我们尝试以最有效的方式利用这些未标注的数据。有两种主要方法可以解决这个问题,即主动学习和半监督学习。两者的明确区别在于前者需要额外的人为输入,而后者不需要人为干预。
主动学习(Active Learning)
主动学习假设可以向人类从查询未标注数据的 ground truth。目标是最小化查询的数量,从而最大限度地减少人工标签的工作量。换句话说,此方法的输出是:从所有未标注的数据中,找到最有效的数据点,最值得标注的数据点然后询问 ground truth。
例如,可能有一个距离决策边界很远的数据点,具有很高的正类可信度,标注这一点不会提供太多信息或改进分类模型。但是,如果非常接近分离阈值的最小置信点被重新标注,则这将为模型提供最多的信息增益。
更具体地说,有两种广泛使用的数据点选择标准,即信息性和代表性。信息性衡量未标注实例有助于减少统计模型的不确定性,而代表性衡量实例有助于表示输入模式结构的程度。
关于信息性,有两种主要方法,即不确定性抽样(Uncertainty sampling)和投票机制(query-by-committee)。 前者培训单个分类器,然后查询分类器 confidence 最低的未标注数据。 后者生成多个分类器,然后查询分类器最不相同的未标注数据。
关于代表性,我们的目标是通常通过聚类方法来利用未标注数据的聚类结构。
半监督学习(Semi-Supervised Learning)
另一方面,半监督学习则试图在不询问人类专家的情况下利用未标注的数据。 起初这可能看起来反直觉,因为未标注的数据不能像标注数据一样,直接体现额外的信息。
然而,未标注的数据点却存在隐含的信息,例如,数据分布。新数据集的不断增加以及获得标签信息的困难使得半监督学习成为现代数据分析中具有重要实际意义的问题之一。
半监督学习的最主要假设:数据分布中有可以挖掘的的信息。
图 1 提供了直观的解释。如果我们必须根据唯一的正负点进行预测,我们可以做的只是随机猜测,因为测试数据点正好位于两个标注数据点之间的中间位置;如果我们被允许观察一些未标注的数据点,如图中的灰色数据点,我们可以高可信度地预测测试数据点为正数。虽然未标注的数据点没有明确地具有标签信息,但它们隐含地传达了一些有助于预测建模的数据分布信息。
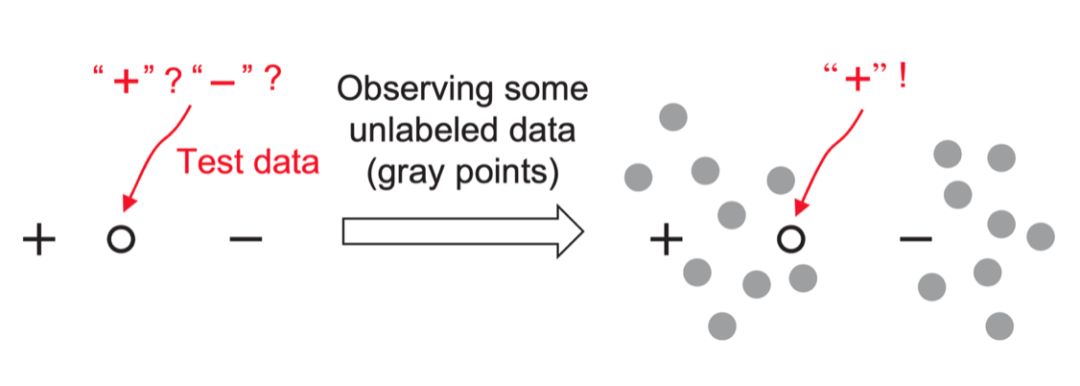
▲ Figure 1 为标注数据分布对分类的帮助 [12]
所有半监督算法都有两个主要假设,即流形假设和聚类假设。前者假设数据位于流形上,因此,附近的实例具有类似的预测。 而后者假设数据具有固有的集群结构,因此落入同一集群的实例具有相同的类标签。
简而言之,类似的数据点应该具有相似的输出,我们假设存在数据间点间关系,这些关系可以通过未标注的数据显示出来。
Self-Training
下面我们详细看一下各类的半监督方法。说到半监督学习,我们不得不提到自我训练方案(Self-training)。
Self-training 通过自己的预测结果中信心最高的样本来进行 Bootstrapping。也就是说,原始分类器首先对测试集进行一轮预测,并将最自信的预测添加到训练集中。选择最自信的预测通常基于预定义的阈值,然后使用新的扩大训练集作为输入重复训练过程,并将整个过程迭代到某个终止条件。
我们可以参考图 2 来对比 Self-training 和常规的 Expectation Maximisation (EM) 方法。
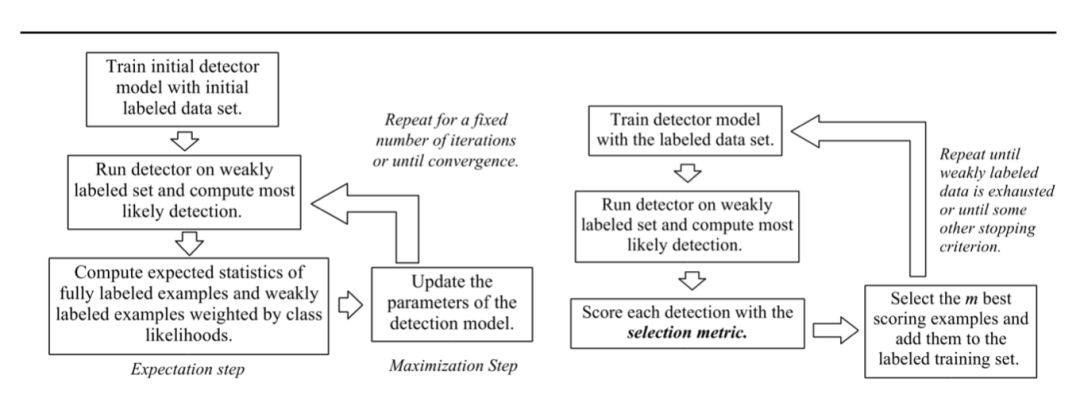
▲ Figure 2 Self-training 流程 [12]
该方法是作为现有训练流程的 Wrapper 实现的。然而,这种方法的缺点是它是启发式的,这意味着它们可能会加剧错误。例如,第一个模型错误地预测样本具有高可信度,可能是由于标签噪声等,这在现实世界的任务中非常常见。这将影响所有后续迭代,并且不会有自校正机制,因此错误将无论如何传播。
除了自我训练,半监督学习的许多其他版本和类别得到发展,一些有着非常悠久的历史。 还有四种其他主要类别的半监督学习方法,即生成方法(Generative Methods),基于图的方法(Graph-based Methods),低密度分离方法(Low-density Separation)和基于分歧的方法(Disagreement-based Methods)。我们将选取其中几种方法进行深入研究,以及不同方法的发展。
下面可以看到几种不同方法的发展历程:

▲ Figure 3 生成方法的发展历程

▲ Figure 4 图方法的发展历程
▲ Figure 5 Low-density Separation 的发展历程

▲ Figure 6 Disagreement Methods 的发展历程

▲ Figure 7 综合方法的发展历程
Generative Methods
生成方法假设标注和未标注数据都是从相同的固有模型生成的。 因此,未标注实例的标签可以被视为模型参数的缺失值并且通过诸如期望最大化(Expectation-Maximisation)算法的方法来估计。
Mixture of Experts
早在 1996 年,就已经在半监督学习领域进行了研究。学习基于总数据可能性的最大化,即基于标注和未标注数据子集。两种不同的EM学习算法,不同之处在于应用于未标注数据的EM形式。 基于特征和标签的联合概率模型的分类器是“专家的混合”结构,其等同于径向基函数(RBF)分类器,但是与 RBF 不同,其适合于基于可能性的训练。
Hybrid Discriminative/Generative
现有的半监督学习方法可分为生成模型或判别模型。而这个方法侧重于概率半监督分类器设计,并提出了一种利用生成和判别方法的混合方法。在原有的生成模型(标注样本上训练得到)新引入偏差校正模型。基于最大熵原理,结合生成和偏差校正模型构建混合模型。该方法结合了判别和生成方法的优点。
Graph Based Methods
在图 8 中,我么可以一眼看出问号代表的样本,有很大的可能性为正样本。这充分体现出未标注数据的分布对于分类效果提升的帮助。
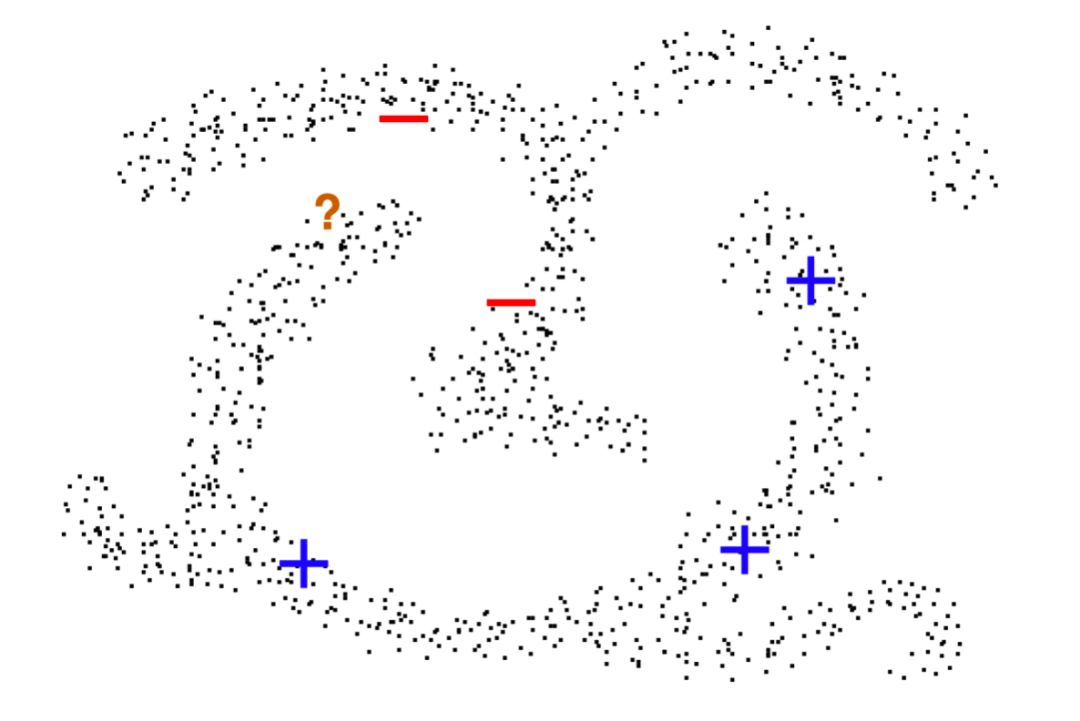
▲ Figure 8 数据分布对分类的影响 [5]
我们可以把分类任务定义为图结构,构建连接相似数据点的图,隐藏/观察到的标签为图节点上的随机变量(图便成为 MRF)。类似的数据点具有相似的标签,信息从标注的数据点“传播”。如图 9 所示:

▲ Figure 9 根据相似度建立图 [7]
各个样本为图的节点,链接相似的样本。目标则是最小化整体能量,能量的定义如下图所示:
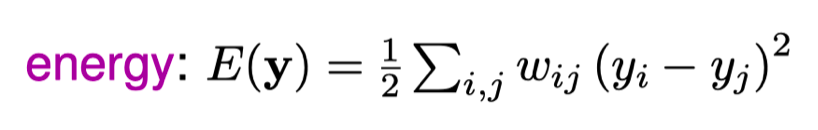
给出的信息是 n×n 相似度矩阵。应该已经有一些方法来确定所有样本之间的相似性 - 并且已经在这个阶段给出。有许多不同的方法可以确定相似性,每种方法都有自己的优点和缺点。
从图 10 我们可以形象的看出优化能量的过程,红色边为高能量,最终目的则是要减少高能量的边。

▲ Figure 10 不同状态的能量 [7]
过程可以定义为离散马尔可夫随机场(Discrete Markov Random Fields)如图 11:

▲ Figure 11 离散马尔科夫随机场 [7]
Learning using Graph Mincuts
图方法中比较早的研究,此研究相对于较早方法关键的突破在于可以在指数复杂度优化问题上实现多项式运算时间。这里用的相似度为 Nearest Neighbour(NN),并优化最近邻的一致性。潜在的随机场为我们的方法提供了一个连贯的概率语义,但是本此方法仅使用场的均值,其特征在于谐波函数和谱图理论。
半监督学习问题的关键是先验假设的一致性,这意味着:(1)附近的点可能具有相同的标签; (2)同一结构上的点(通常称为簇或歧管)可能具有相同的标签。值得注意的是第一点是 Local,而第二点是 Global。传统监督学习算法,例如 k-NN,通常仅取决于局部一致性的第一假设。
预训练预训练与多任务学习
通过以上对半监督学习中不同方法的分析,我们可以看到,半监督的核心问题是数据流形构成不准确,在样本数量少的时候更是如此。如果我们可以准确地定义数据的分布,我们更有可能对未出现过的数据做出更好的预测。
BERT 通过大量的预训练,空间相对稳定,可以把流形更加清楚地构造出来。在半监督任务中可以加入 BERT 提供的流形先验,做整体的约束。我们可以用下图来直观地表示效果:

▲ Figure 12 BERT 理论上对数据流形的增强效果 [14]
近日微软发布的 MT-DNN,在 GLUE 的 11 项 NLP 任务中有 9 项超越了 BERT!MT-DNN 在 BERT 预训练的基础上,加入了多任务学习(Multi-task Learning)的方法,不像 BERT 只采用了未标注数据来做预训练,MT-DNN 还利用了其他相关任务的监督数据,与 BERT 预训练进行互补,并且减轻对特定任务的过拟合。
实验
为了对比 BERT 在半监督中的效果,我们做了一些实验来对比:传统的监督 Naïve Bayes 分类器,半监督 Naïve Bayes 分类器,BERT 和半监督 BERT。
这里用到的半监督方法是 Self-training/Label Propagation。我们使用相同的数据集 – 20 Newsgroups Dataset,并使用相同数量的训练和测试集 1,200 和 10,000。实验结果如图 13 所示:

▲ Figure 13 20 Newsgroup 分类结果
可以看到加入了 BERT 之后效果非常明显,BERT-base 已经在原有的半监督方法的基础上面提升了接近 10%,说明 BERT 本身可以更加好地捕获数据流形。此外,加入了半监督方法的 BERT 在原有的基础上有更好的效果,半监督跟预训练的方法还有结合互补的潜力。
总结
在深入了解弱监管的历史和发展之后,我们可以看到这一研究领域的局限性和改进潜力。数据标签成本总是很昂贵,因为需要领域专业知识并且过程非常耗时,尤其是在 NLP 中,文本理解因人而异。但是,我们周围存在大量(几乎无限量)未标注的数据,并且可以很容易地提取。
因此,我们始终将持续利用这种丰富资源视为最终目标,并试图改善目前的监督学习表现。从 ULMFiT 等语言模型到最近的 BERT,迁移学习是另一种利用未标注数据的方法。通过捕获语言的结构,本质上是另一种标签形式。在这里,我们建议未来发展的另一个方向 - 将迁移学习与半监督学习相结合,通过利用未标注的数据进一步提高效果。
参考文献
[1] Blum, A. and Chawla, S. (2001). Learning from Labeled and Unlabeled Data using Graph Mincuts.
[2] Chapelle, O. and Zien, A. (2005). Semi-Supervised Classiflcation by Low Density Separation.
[3] Fujino, A., Ueda, N. and Saito, K. (2006). A Hybrid Generative/Discriminative Classifier Design for Semi-supervised Learing. Transactions of the Japanese Society for Artificial Intelligence, 21, pp.301-309.
[4] Gui, J., Hu, R., Zhao, Z. and Jia, W. (2013). Semi-supervised learning with local and global consistency. International Journal of Computer Mathematics, 91(11), pp.2389-2402.
[5] Jo, H. (2019). ∆-training: Simple Semi-Supervised Text Classification using Pretrained Word Embeddings.
[6] Kipf, T. (2017). Semi-Supervised Classification with Graph Convolutional Networks.
[7] Li, Q. (2018). Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning.
[8] Liu, X., He, P., Chen, W. and Gao, J. (2019). Multi-Task Deep Neural Networks for Natural Language Understanding.
[9] Miyato, T., Maeda, S., Ishii, S. and Koyama, M. (2018). Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, pp.1-1.
[10] NIGAM, K. (2001). Text Classification from Labeled and Unlabeled Documents using EM.
[11] Triguero, I., García, S. and Herrera, F. (2013). Self-labeled techniques for semi-supervised learning: taxonomy, software and empirical study. Knowledge and Information Systems, 42(2), pp.245-284.
[12] Zhou, Z. (2017). A brief introduction to weakly supervised learning. National Science Review, 5(1), pp.44-53.
[13] Zhu, X. (2003). Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions.
[14] Zhuanlan.zhihu.com. (2019). [online] Available at: https://zhuanlan.zhihu.com/p/23340343 [Accessed 18 Feb. 2019].

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐



