生成式模型入门:训练似然模型的技巧
机器之心编译
参与:李志伟、Geek AI
生成模型不止有 GAN,本教程讨论了数学上最直接的生成模型(易处理的密度估计模型)。 读罢本文,你将了解如何定量地比较似然模型。
散度最小化:生成模型的一般框架
生成模型(其实都是统计机器学习模型)旨在从一些(可能是条件的)概率分布 p(x) 中取样本数据,并学习对 p(x) 进行近似的模型 pθ(x)。建模过程使我们可以基于给定的原始数据外推观察到的信息。以下是可以通过生成模型实现的各种各样的操作:
从 p(x) 中抽取新样本
学习解释观测值 x 的分层潜变量 z
你可以对潜变量进行干预,从而检查干预分布 p_θ(x|do(z))。请注意,只有当你的条件分布对正确的因果关系 z→x 建模,并且我们假设可忽略性(ignorability)成立,这样做才有效。
在我们的模型分布下查询新数据点 x' 的似然,从而检测异常
由于我们可以将分类和回归问题解释为学习生成模型的过程,对条件分布进行建模具有更广泛的直接应用:
机器翻译 p(句子的英语翻译 | 法语句子)
字幕 p(字幕 | 图像)
像最小化均方误差 min{1/2(x−μ)^2} 这样的回归目标函数在数学上等价于具有对角协方差的高斯分布的最大对数似然估计:max{−1/2(x−μ)^2}
为了使 pθ(x) 接近 p(x),我们首先必须提出两个分布之间距离的概念。在统计学中,更常见的是设计一种较弱的「距离」概念,我们将其称为「散度」。与几何距离不同,散度并不是对称的 (D(p,q)≠D(q,p))。如果我们可以定义概率分布之间形式化的散度,我们就可以尝试通过优化来最小化它。
我们可以定义各种各样的散度 D(p_θ||p),并且通常选用适应于生成模型算法的散度。在这里,我们只列出其中很少的一部分:
最大平均差异(MMD)
Jensen-Shannon 散度(JSD)
Kullback-Leibler 散度(KLD)
反向 KLD
KernelizedStein 散度(KSD)
Bregman 散度
Hyvärinen 得分
Chi-Squared 散度
Alpha 散度
与几何距离不同,两个分布之间的散度不需要是对称的。通过在无限的数据上进行无数次的计算,所有这些散度都得出相同的答案,即 D(p_θ||p)=0 当且仅当 p_θ≡p。请注意,这些差异与感知评估指标(如 Inception 得分)不同,后者无法保证在高数据限制下收敛到相同的结果(但如果你关心图像的视觉质量,这些指标是有用的)。
然而,大多数实验只涉及数量有限的数据和计算,因此对度量的选择就十分重要,这实际上可以改变最终学习到的生成分布 p_θ(x) 的定性行为。例如,如果目标密度为 p 是多模态的且模型分布 q 的表达较弱,则最小化前向 KL D_KL(p || q) 将学习模式覆盖行为;而最小化反向 KL D_KL(q||p) 将导致模式丢弃行为。对于其原因更详细的解释,可以参阅下面的博文:https://blog.evjang.com/2016/08/variational-bayes.html。
在散度最小化的框架下考虑生成模型是很有用的,因为这让我们可以仔细思考:为了进行训练,我们对生成模型有何要求。它可能是隐式的密度模型(GAN),此时采样相对容易,而并不能计算对数概率;它也可能是基于能量的模型,此时无法进行采样,而(非标准化的)对数概率则易于计算。
这篇博文将涉及到使用最直接的指标(Kullback-Leibler 散度)训练和评估的模型。这些模型包括自回归模型,归一化流和变分自编码器(近似地)。优化 KLD 等价于优化对数概率,我们将在下一节中推导出原因!
平均对数概率和压缩
我们想对一些数据生成随机过程的概率分布 p(x) 建模。通常,我们假设从足够大的数据集中采样与从真实数据生成过程中采样的情况大致相同。例如,从 MNIST 数据集中抽取出一张图像,等价于从创建 MNIST 数据集的真实手写过程中抽取出一个样本。
给定一组从 p(x) 中采样得到的独立同分布的测试图像 x_1,...,x_N,以及通过 θ 参数化的似然模型 p_θ,我们希望最大化下面的目标函数:
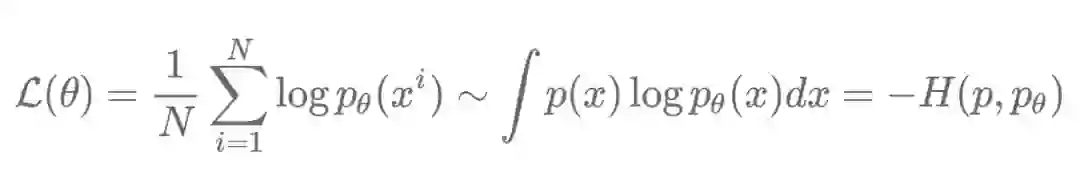
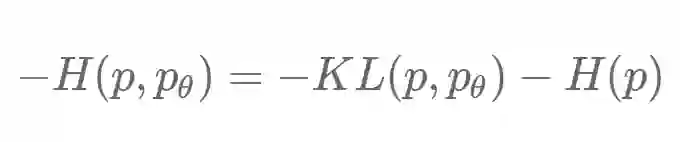
由于我们实际上无法对所有的 x_i 进行枚举,平均对数概率是对真实似然 p 和模型似然 p_θ 之间的负交叉熵的蒙特卡罗估计。简而言之,这意味着「最大化数据的平均似然」,或者相当于「最小化真实分布和模型分布之间的负交叉熵」。
通过一些代数运算,负交叉熵可以用 KL 散度(相对熵)和 p 的绝对熵重写:
香农(Shannon)的信源编码定理(1948)告诉我们,熵 H(p) 是你可以构造的任何编码的平均编码长度的下界,以无损地传递来自 p(x) 的样本。更大的熵意味着更大的「随机性」,这是无法压缩的。特别是,当我们使用自然对数 log_e 计算熵时,它采用「自然信息单位」(或简称 nat)。用 log_2 计算熵时,结果的单位是我们熟悉的「位」。H(p) 项与 θ 无关,因此最大化 L(θ) 实际上恰好等价于最小化 KL(p,p_θ)。这就是最大似然也被称为最小化 KL 散度的原因。
KL 散度 KL(p,p_θ) 或相对熵,是对来自 p(x) 的数据编码所需的「额外的 nat」的数量,该过程使用基于 p_θ(x) 的熵编码方案。因此,负交叉熵的蒙特卡罗估计 L(θ) 也用 nat 表示。
将二者放在一起,交叉熵只不过是使用基于 p_θ 的码本,传送来自 p 的样本所需的平均编码长度。无论(最优编码)如何,我们都会支付 H(p) nat 的「基本费用」,我们还会为 p_θ 与 p 的任何偏差支付额外的「精细的」KL(p,p_θ) nat。
我们可以用一种可解释性很强的方式比较两个不同模型的交叉熵:假设模型 θ_1 具有平均似然 L(θ_1),模型 θ_2 具有平均似然 L(θ_2)。减去 L(θ1)-L(θ2) 使得熵项 H(p) 抵消,最终得到 KL(p,p_(θ_1))-KL(p,p_(θ_2))。该数是「从 p_(θ_1) 转换到编码 p_(θ_2) 时需要支付的减少的惩罚值」。
表达能力,优化和泛化能力是一个良好的生成模型的三个重要特性,而似然则提供了可解释的度量,用来在我们的模型中调试这些属性。如果生成模型不能记忆训练集,则表明在优化过程(会卡住)或表达能力(欠拟合)的方面存在困难。
Cifar10 图像数据集包含 50,000 个训练样本,因此我们知道能完美地记忆数据的模型将为训练数据集中的每个图像分配恰好 1/50000 的概率质量,从而得到 log_2(1/50000) 的负交叉熵,或者说为每个图像分配 15.6 位(这与每个图像有多少像素无关!)。当然,我们通常不希望我们的生成模型过拟合这种极端情况,但在调试生成模型时,记住这个上限,作为一种检合理性检查是很有用的。
比较训练和测试似然之间的差异可以告诉我们,网络是在生硬地记忆训练集还是学习泛化到测试集的东西,或者在模型无法捕获的数据上是否存在语义上有意义的模式。
原文链接:https://blog.evjang.com/2019/07/likelihood-model-tips.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



