Jeff Dean署名《深度学习稀疏专家模型》综述论文
机器之心报道
30年时间,稀疏专家模型已逐渐成为一种很有前途的解决方案。


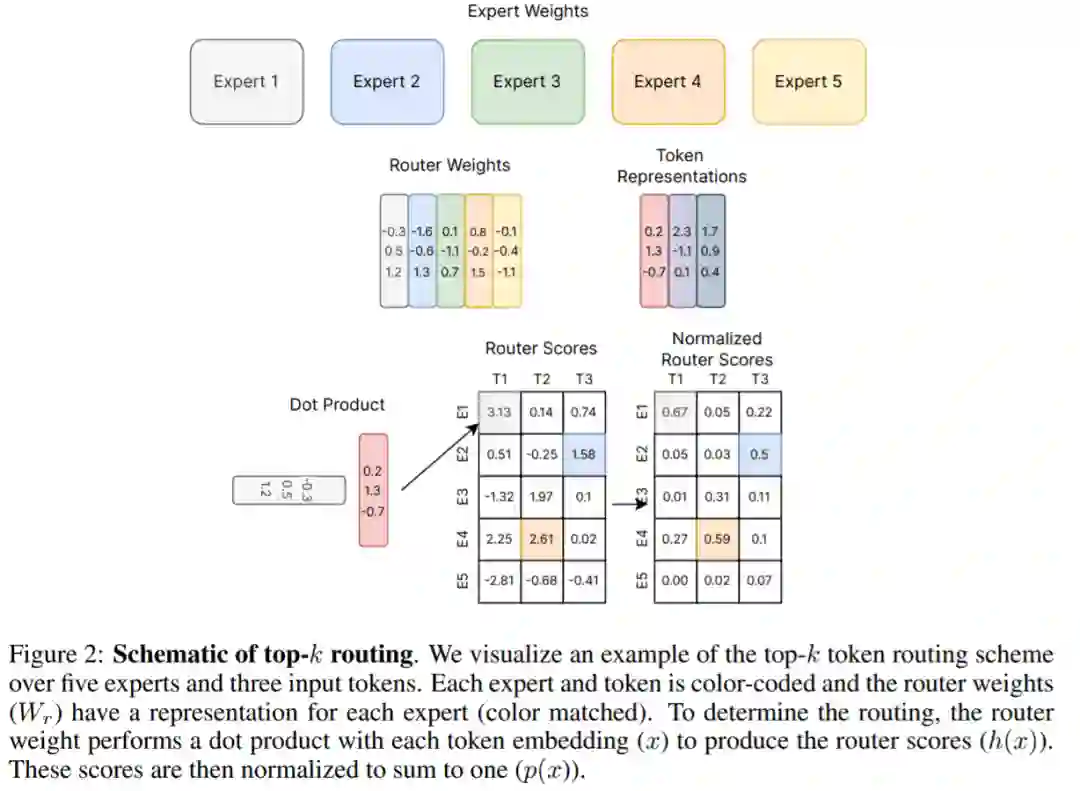
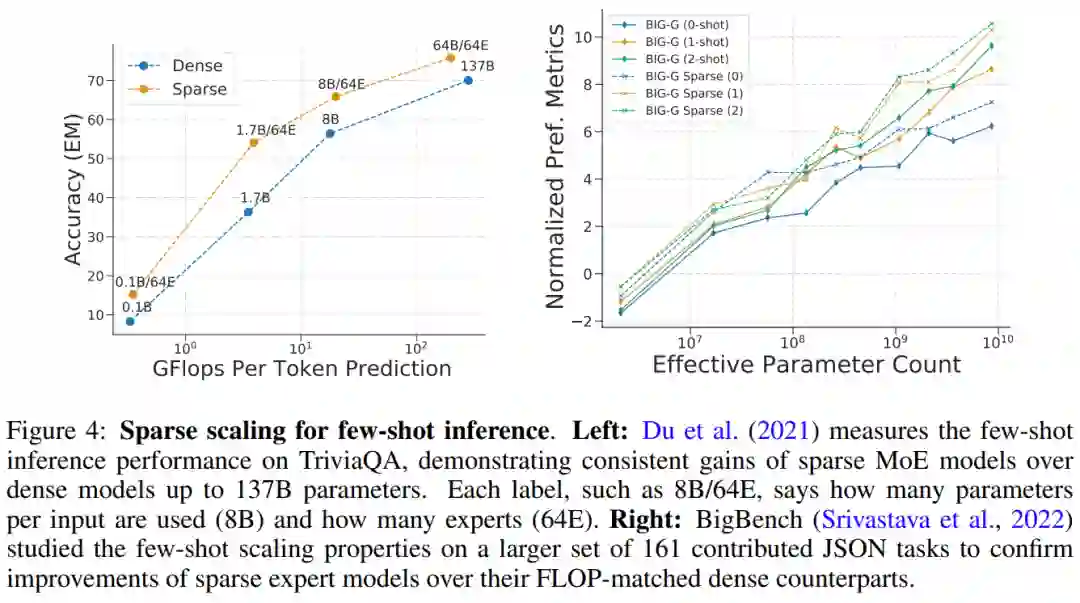
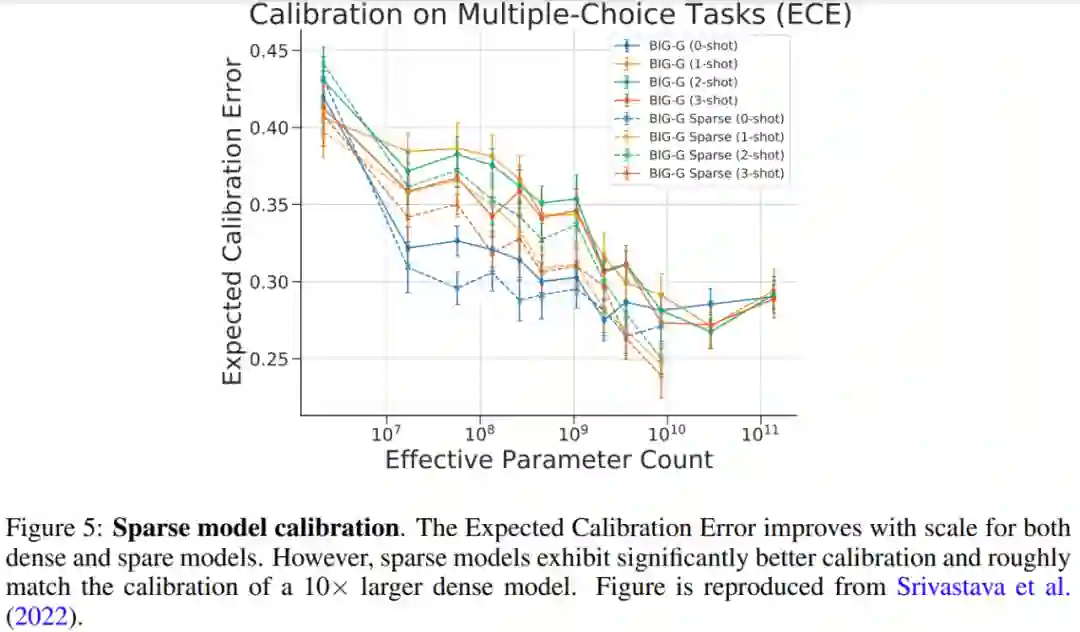

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DLSDM” 就可以获取《Jeff Dean署名《深度学习稀疏专家模型》综述论文》专知下载链接



登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文