
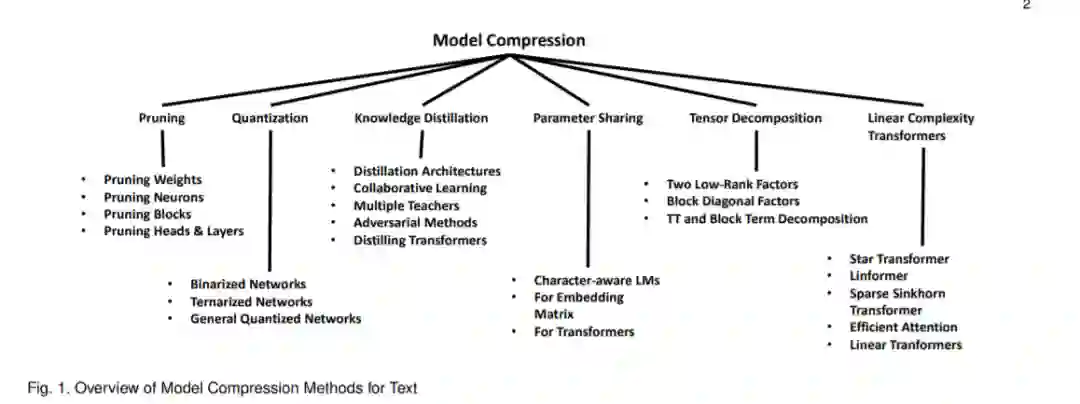
近年来,自然语言处理(NLP)和信息检索(IR)领域取得了巨大的进展,这要归功于深度学习模型,如回归神经网络(RNNs)、门控回归单元(GRUs)和长短时记忆(LSTMs)网络,以及基于Transformer (Vaswani et al., 2017)的双向编码器表示模型(BERT) (Devlin et al., 2018)。但这些模型都是巨大的。另一方面,现实世界的应用程序要求较小的模型尺寸、低响应时间和低计算功率。在这个综述中,我们讨论了六种不同类型的方法(剪枝、量化、知识蒸馏、参数共享、张量分解和基于线性变压器的方法)来压缩这些模型,使它们能够在实际的工业NLP项目中部署。考虑到构建具有高效和小型模型的应用程序的迫切需要,以及最近在该领域发表的大量工作,我们相信,本论文调研组织了“NLP深度学习”社区在过去几年里所做的大量工作,并将其作为一个连贯的故事呈现出来。
https://www.zhuanzhi.ai/paper/3fba50f6f54fa8722b1c7fd56ec0bcfb
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯