谷歌Jeff Dean长文展望:2021年之后,机器学习领域的五大潜力趋势
2021 年之后,机器学习将会对哪些领域产生前所未有的影响?
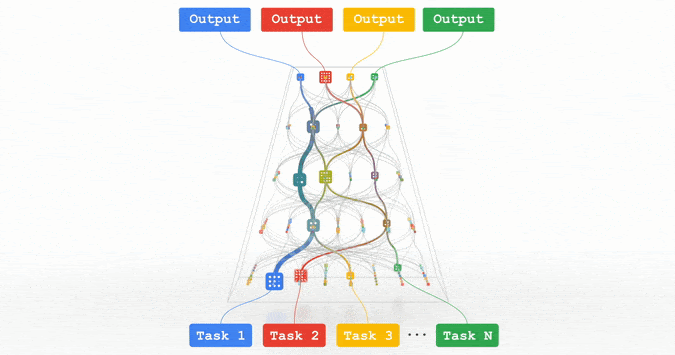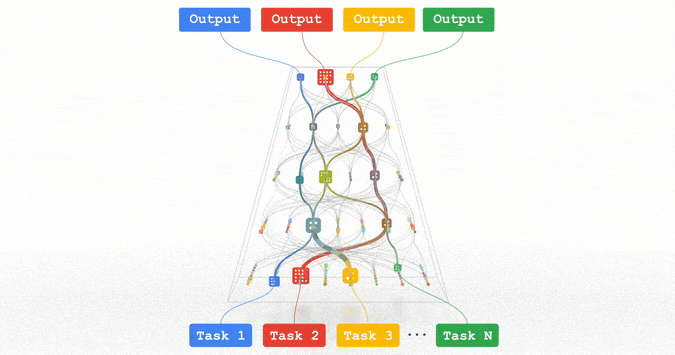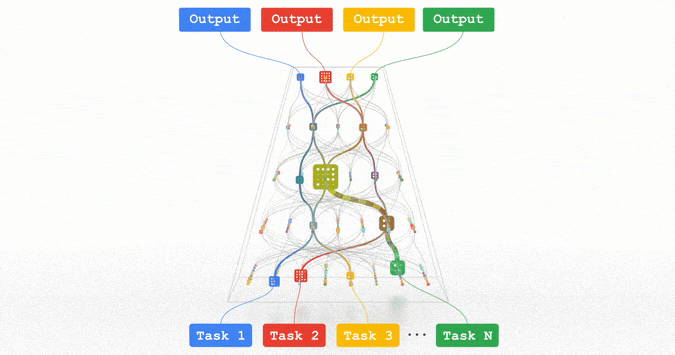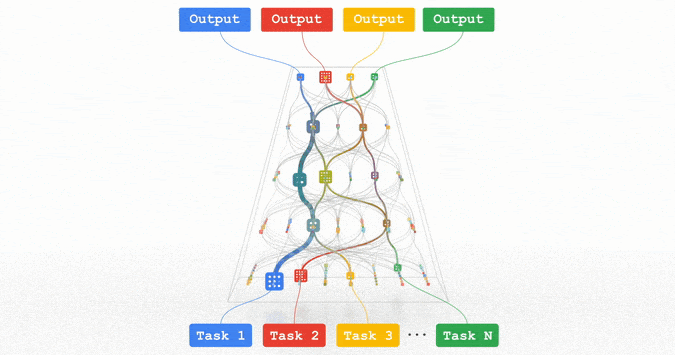
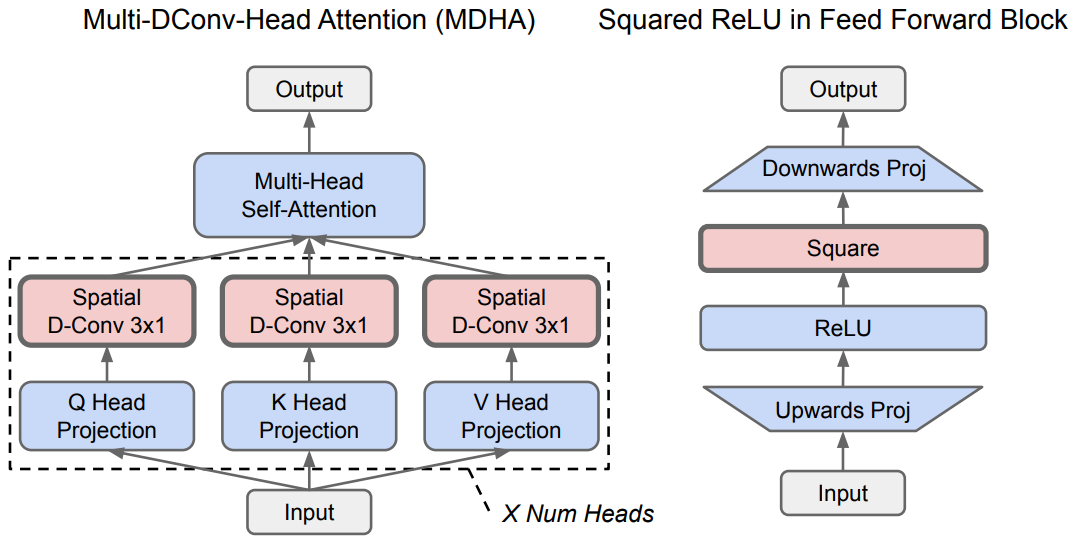
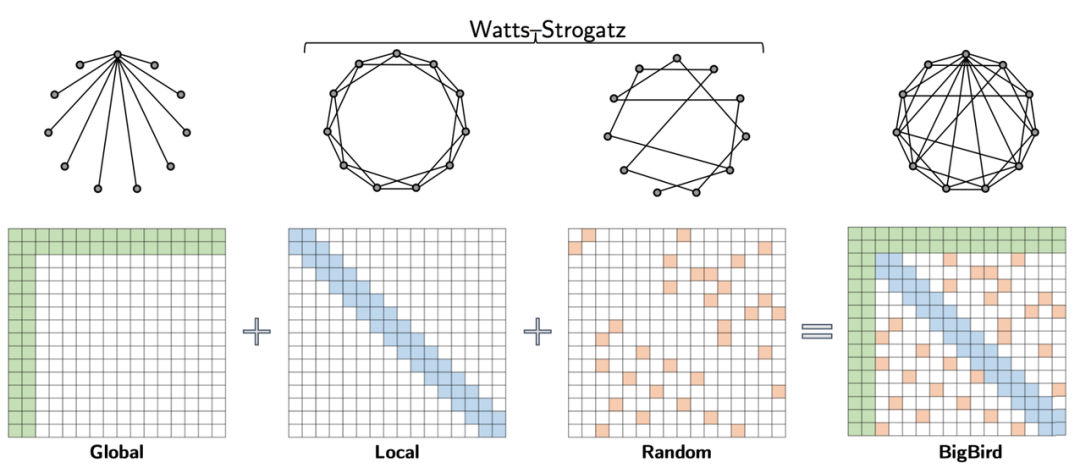
趋势 1:能力、通用性更强的机器学习模型
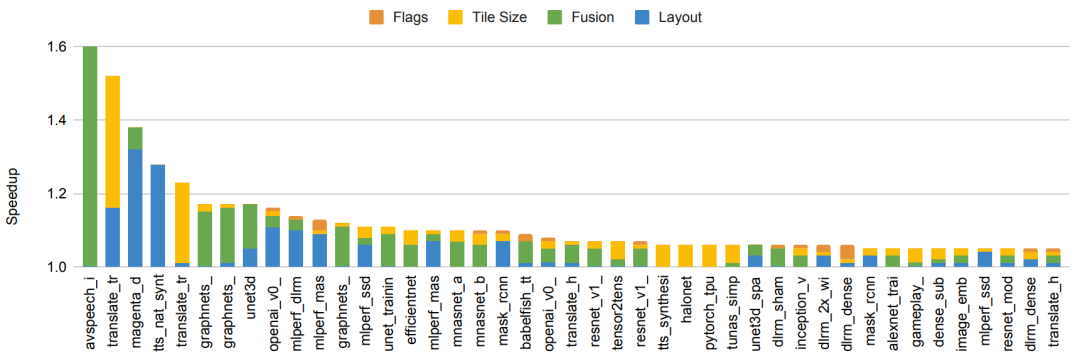
趋势 2:机器学习持续的效率提升
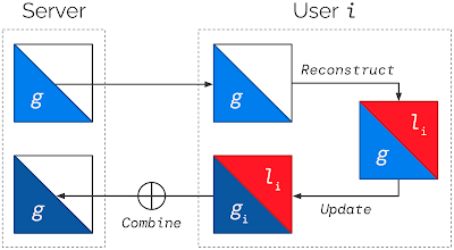
趋势 3:机器学习变得更个性化,对社区也更有益
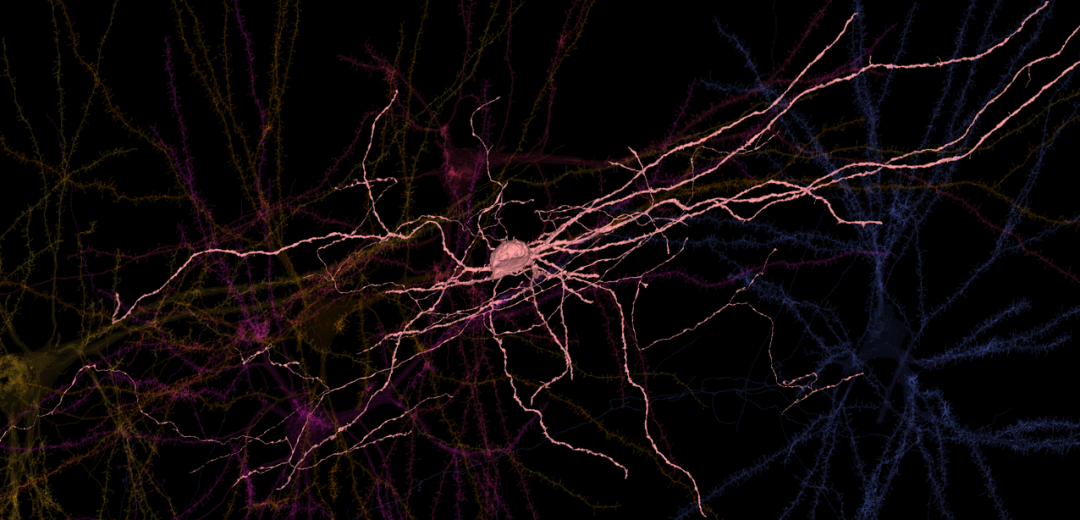
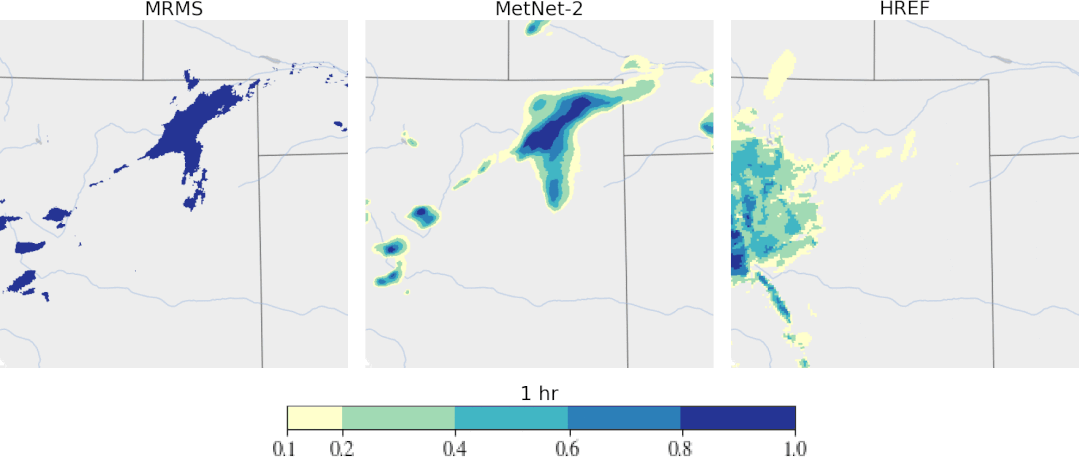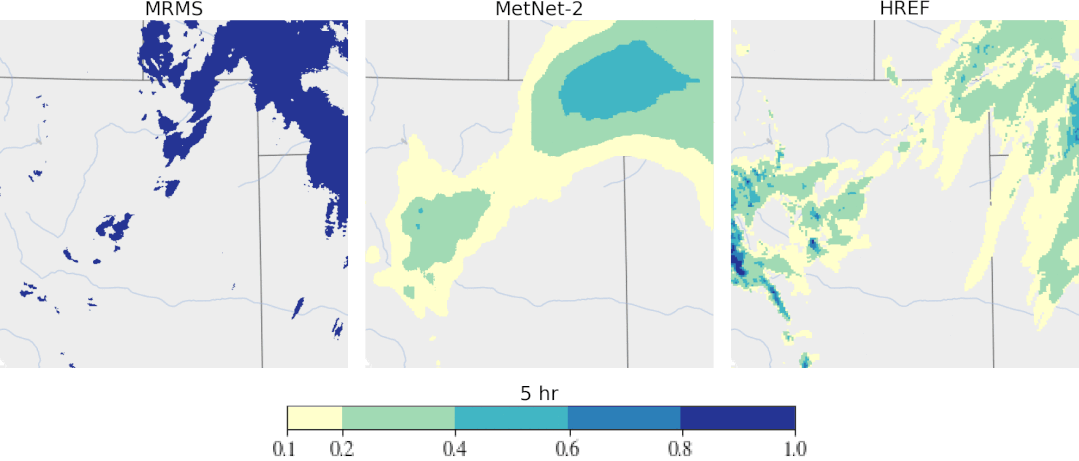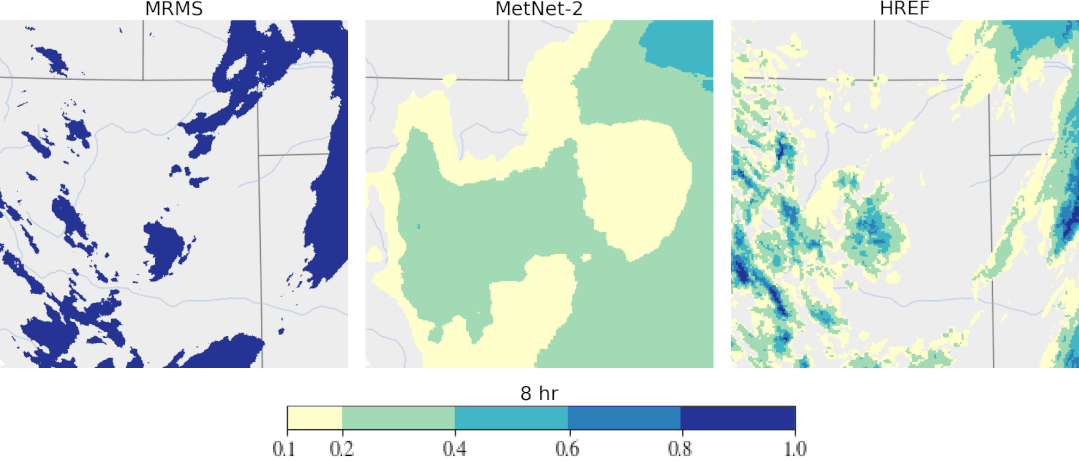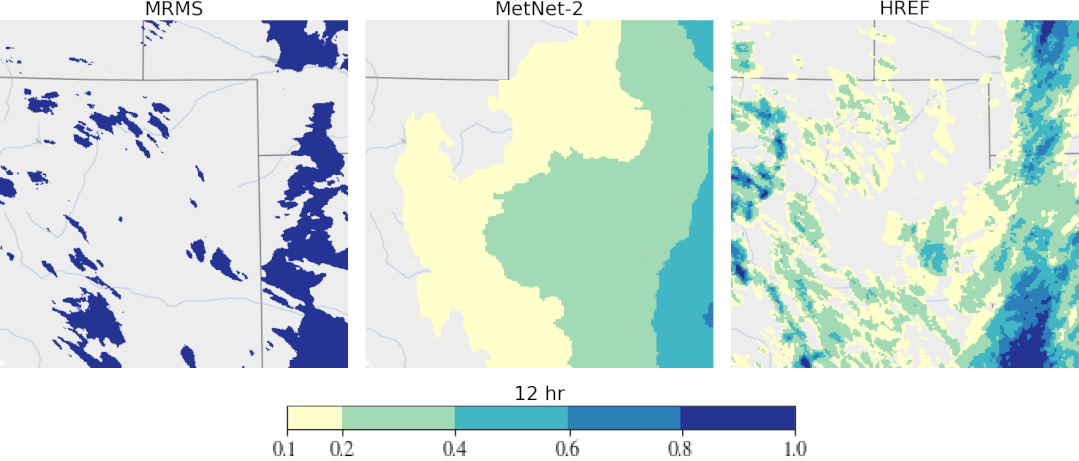
趋势 4:机器学习对科学、健康和可持续发展的影响越来越大
趋势 5:对机器学习更深入和更广泛的理解






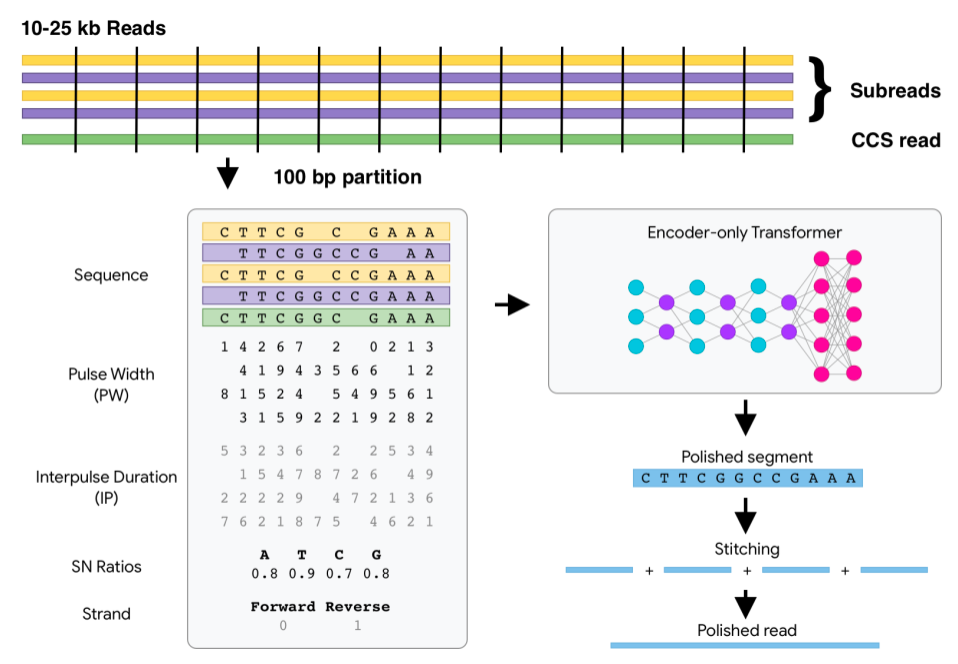

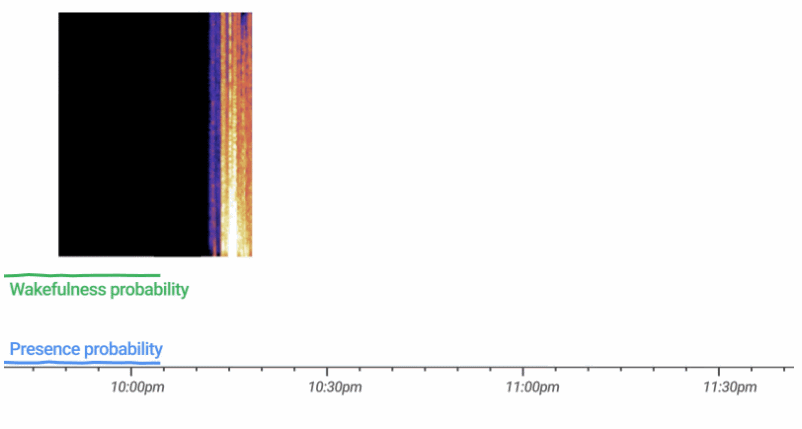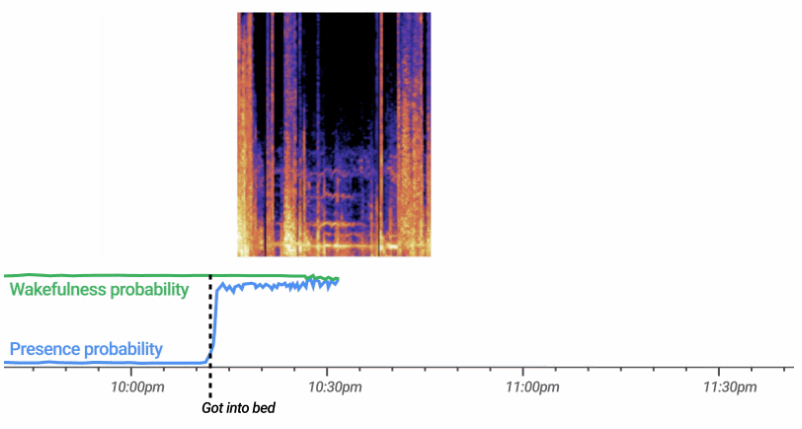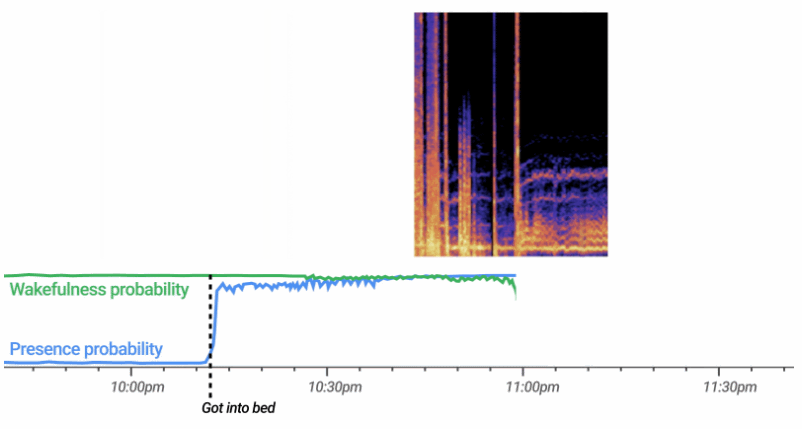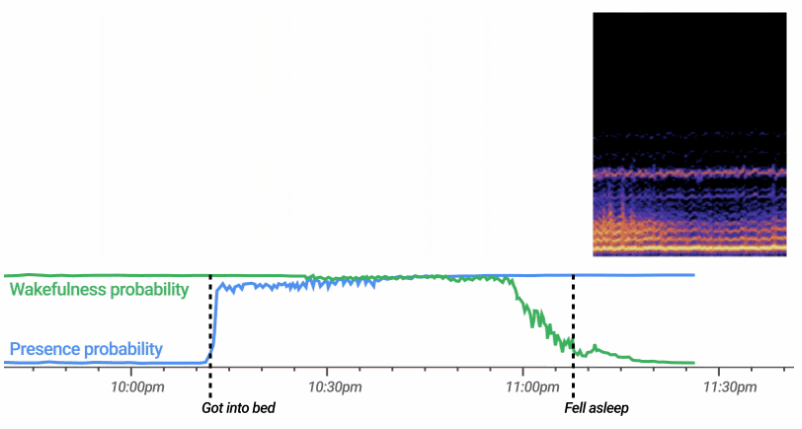
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“机器学习” 就可以获取《机器学习专知资料大全》专知下载链接



登录查看更多




相关VIP内容
相关资讯