EMNLP 2020 | 且回忆且学习:在更少的遗忘下精调深层预训练语言模型
论文名称:Recall and Learn: Fine-tuning Deep Pretrained Language Models with Less Forgetting 论文作者:陈三元,侯宇泰,崔一鸣,车万翔,刘挺,余翔湛 原创作者:陈三元 论文链接:https://arxiv.org/abs/2004.12651 转载须标注出处:哈工大SCIR
1. 简介
2. 背景
2.1 顺序迁移学习
2.2 多任务学习
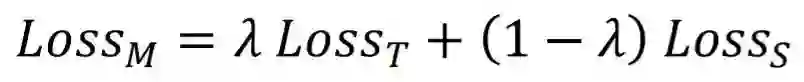
-
我们在适应阶段无法访问预训练数据来计算 。 -
适应阶段的优化目标是 ,而多任务学习旨在优化 ,即 和 的加权和。
3. 方法
3.1 预训练模拟机制
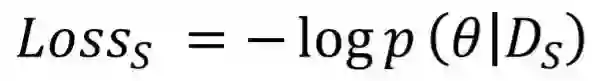
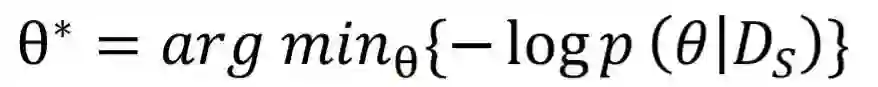
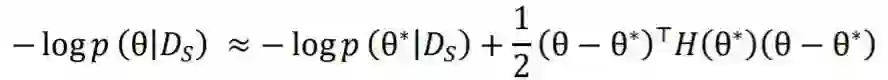
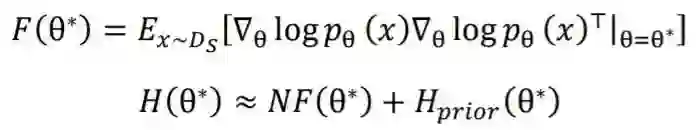
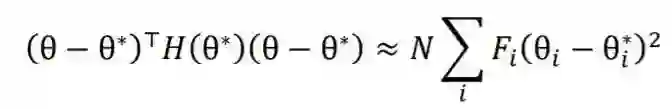
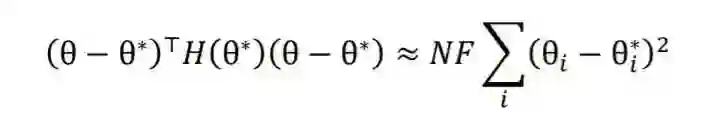
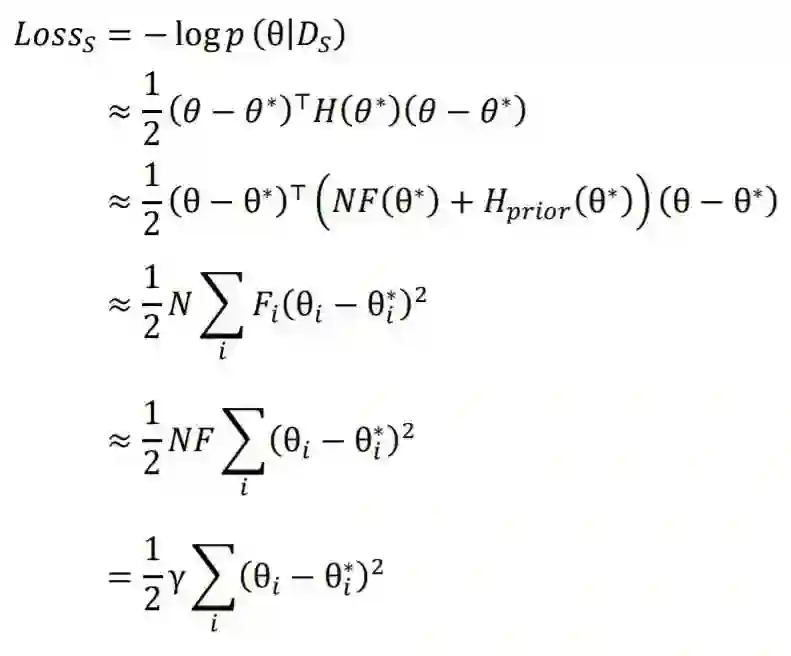
3.2 目标迁移机制
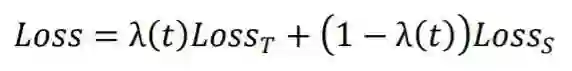
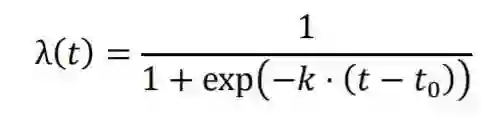
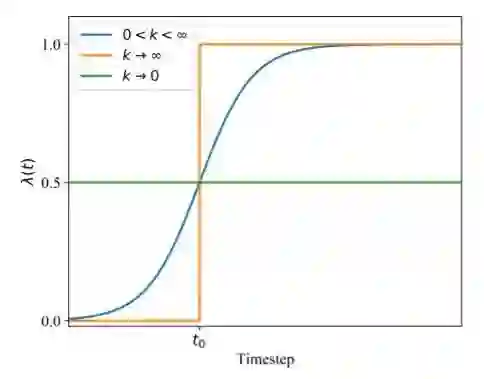
图1 目标迁移机制:我们用退火函数 代替多任务学习优化目标中的系数 。精调和多任务学习可以视为我们的方法的特例( 和 )。
3.3 优化器

4. 实验结果
表1 GLUE 数据集的开发集上的最先进的单任务单模型结果。
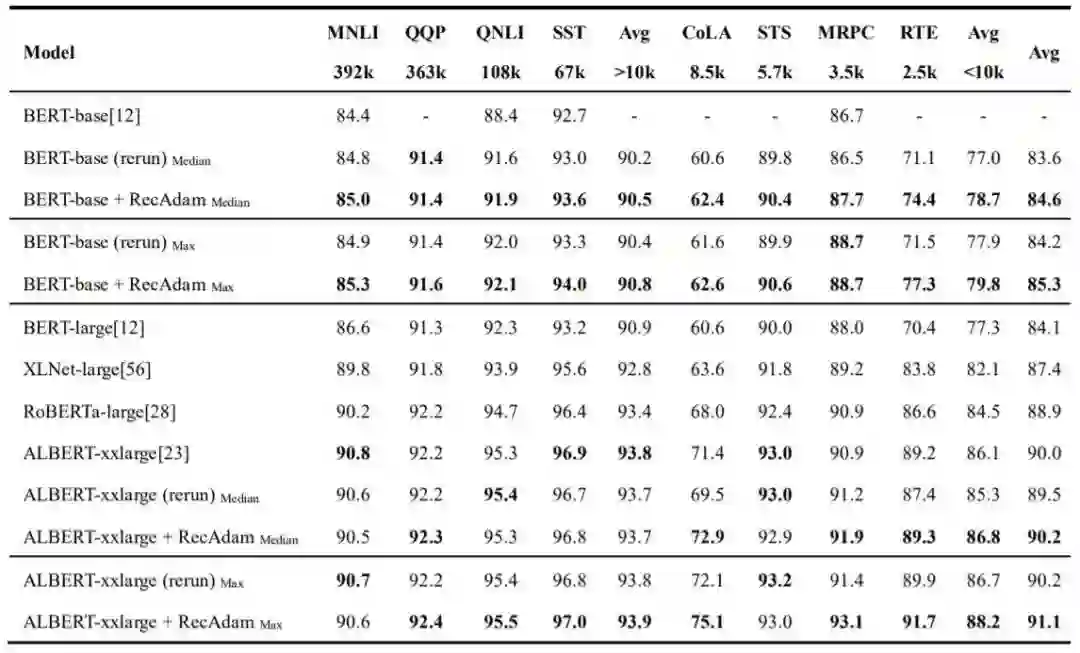
表2 GLUE 数据集的测试集上的单任务单模型结果,由 GLUE 服务器进行评分。我们提交 了在每个开发集上得到的最佳模型的结果。

4.1 基于BERT-base的结果
4.2 基于ALBERT-xxlarge的结果
4.3 初始化分析
表3 不同的模型初始化策略的比较:预训练初始化策略和随机初始化策略

4.4 遗忘分析
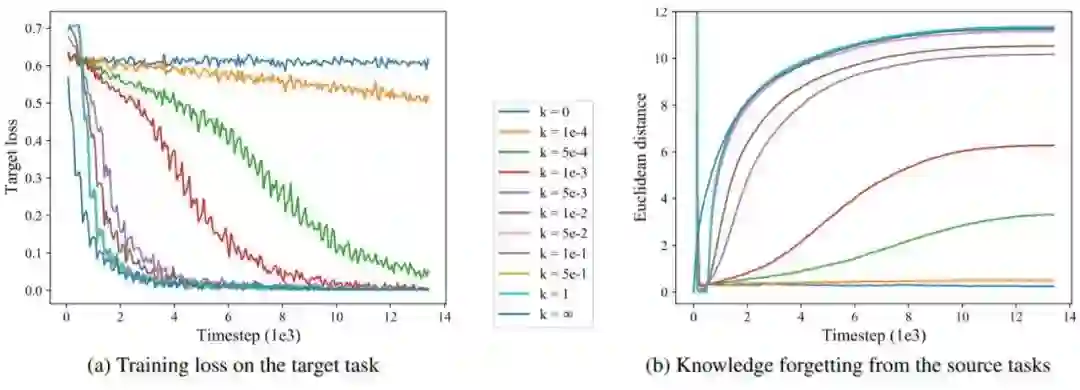
图2 在CoLA数据集上使用有着不同的 值的RecAdam方法精调BERT-base的学习曲线。
5. 结论
在本文中,我们通过桥接两种迁移学习范例:顺序迁移学习和多任务学习,有效缓解了适应深层预训练语言模型时的灾难性遗忘问题。为了解决联合训练预训练任务时缺少预训练数据的问题,我们提出了一种预训练模拟机制在没有数据时学习预训练任务。接着,我们提出了目标迁移机制,以更好地平衡预训练的回忆和目标任务的学习。实验证明了我们的方法在迁移深层预训练语言模型方面的优势。我们还通过将提出的机制集成到Adam优化器中提供了开源的RecAdam优化器,以促进自然语言处理社区更好地使用深层预训练语言模型。
6. 参考文献
[1] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. 2018. Memory aware synapses: Learning what (not) to forget. In Proceedings of the European Conference on Computer Vision, pages 139–154.
[2] Gaurav Arora, Afshin Rahimi, and Timothy Baldwin. 2019. Does an lstm forget more than a cnn? an empirical study of catastrophic forgetting in nlp. In Proceedings of the Australasian Language Technology Association, pages 77–86.
[3] Roy Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second PASCAL recognising textual entailment challenge.
[4] Luisa Bentivogli, Ido Dagan, Hoa Trang Dang, Danilo Giampiccolo, and Bernardo Magnini. 2009. The fifth PASCAL recognizing textual entailment challenge. In Proceedings of TAC.
[5] Samuel Bowman, Luke Vilnis, Oriol Vinyals, Andrew Dai, Rafal Jozefowicz, and Samy Bengio. 2016. Generating sentences from a continuous space. In Proceedings of The SIGNLL Conference on Computational Natural Language Learning, pages 10–21.
[6] Rich Caruana. 1997. Multitask learning. Machine learning, 28(1):41–75.
[7] Daniel Cer, Mona Diab, Eneko Agirre, Inigo LopezGazpio, and Lucia Specia. 2017. Semeval-2017 task 1: Semantic textual similarity multilingual and cross-lingual focused evaluation. In Proceedings of the International Workshop on Semantic Evaluation, pages 1–14. Association for Computational Linguistics.
[8] Xinyang Chen, Sinan Wang, Bo Fu, Mingsheng Long, and Jianmin Wang. 2019. Catastrophic forgetting meets negative transfer: Batch spectral shrinkage for safe transfer learning. In Proceedings of the Advances in Neural Information Processing Systems, pages 1906–1916.
[9] Alexandra Chronopoulou, Christos Baziotis, and Alexandros Potamianos. 2019. An embarrassingly simple approach for transfer learning from pretrained language models. In Proceedings of NAACL, pages 2089–2095. [10] Ido Dagan, Oren Glickman, and Bernardo Magnini. 2006. The PASCAL recognizing textual entailment challenge. In Machine learning challenges. evaluating predictive uncertainty, visual object classification, and recognizing textual entailment, pages 177– 190. Springer.
[11] Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Ales Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. 2019. Continual learning: A comparative study on how to defy forgetting in classification tasks. arXiv preprint arXiv:1909.08383.
[12] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics, pages 4171–4186. Association for Computational Linguistics.
[13] William B Dolan and Chris Brockett. 2005. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the International Workshop on Paraphrasing.
[14] Robert M. French. 1999. Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences, 3(4):128 – 135.
[15] Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 2007. The third PASCAL recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing, pages 1–9. Association for Computational Linguistics.
[16] Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. 2013. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:1312.6211.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏

