通过预训练提升语言理解

官方地址:https://blog.openai.com/language-unsupervised/
文章:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
代码:https://github.com/openai/finetune-transformer-lm
本文利用Transformer和非监督预训练结合的方法,提出了一种能用于各种NLP任务的预训练框架,实验结果表明该模型使12项NLP任务中的9项做到了state-of-art的结果。这说明非监督预训练对提升NLP任务的监督学习有很大帮助。
Background
传统的NLP问题往往受制于标注数据太少,但未标注的文本数据则非常多,因此非监督学习可以很好地利用这些未标注的文本数据。而对于有大量标注数据的NLP问题,非监督学习到的特征表示也可以极大地提高这些NLP问题的准确率,对此一个比较有力的证明就是预训练好的词向量对提升NLP任务有很大的帮助。但词向量的局限性在于,对于不同的NLP任务,我们所需要的词的特征表示可能是不一样的,而即便是几百维的词向量也难以包含这些信息用于所有的NLP任务。因此,我们需要用预训练的模型来提升NLP任务的性能。
Challenge
对于设计一个预训练模型,主要存在两方面的挑战,一个是预训练优化的任务目标,例如本文中的目标是传统的LanguageModel,即用上文信息预测下一个出现的词,而BERT中的目标是MaskedLanguage Model + next sentence prediction。另一个挑战是预训练模型如何迁移到下游任务的过程,最主要的方式是模型结构的调整,但也包含一些学习方式的改变、附属学习目标的设立等其他手段。
Model
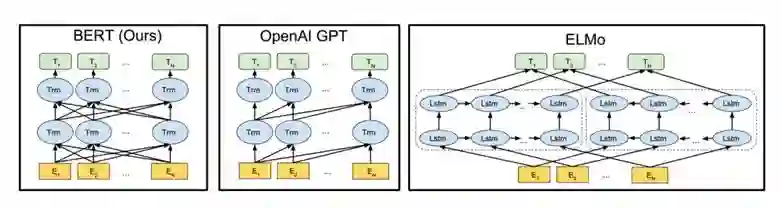
模型主要分为三个部分,分别是 Unsupervised pre-training、Supervised fine-tuning、Task-specific input transformations Experiment。整个模型结构如下图所示:
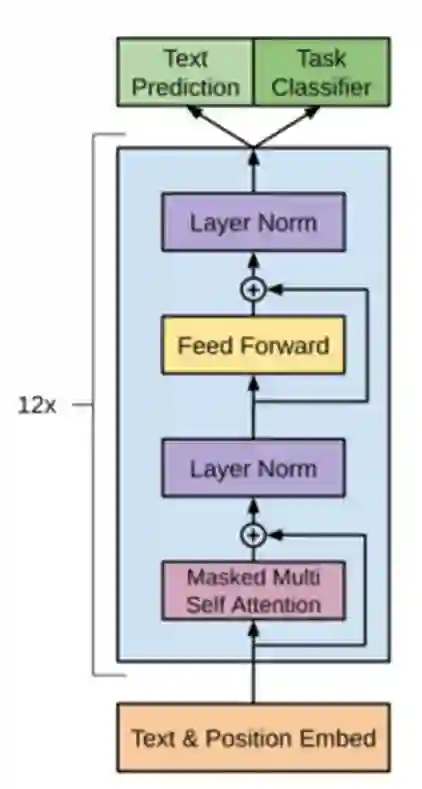
Unsupervised pre-training
整个预训练模型采用传统的语言模型的方式,所以其目标函数为:
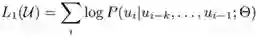
从上面的模型结构图中可以看到,预训练模型框架主要采用了多层 Transformer Decoder 的结构,具体来说就是:
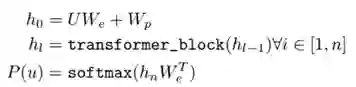
其中各个变量代表的意义为
• U: context vector of tokens
• We: token embedding matrix
• Wp: position embedding matrix
• H is bridge of the two components
由于采用的是传统的语言模型,因此有
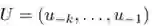
对比 BERT 和 ELMo 几个经典的NLP预训练模型,可以看到,BERT主要在本文的GPT模型上加上一些小改进:
Supervised fine-tuning
和视觉任务类似地,当在做监督学习fine-tuning时,只需把非监督预训练模型的最后一层换为一个新的未训练的softmax分类器即可

所以此时的loss即为
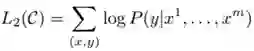
附属目标函数为
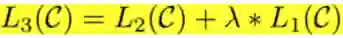
这个附属目标函数结合了预训练过程中的loss,这样做的好处为:(1)有利于提高模型的泛化能力(2)加快模型的收敛
Task-specific input transformations Experiment
在预训练模型迁移到不同NLP任务的过程中,由于任务输入输出的不同,模型也要做出相应的调整。本文所进行的实验任务主要分为四大类:分类任务、推理任务、语义相似性任务、QA类的任务(多选题任务),如下图所示,其中start、extract表示开始符和终止符。
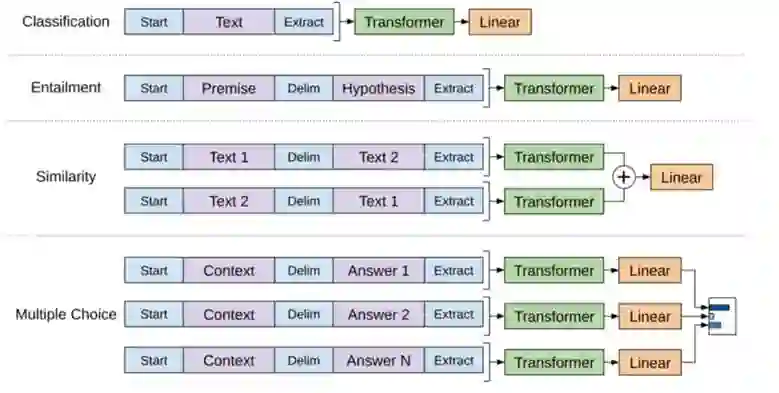
分类任务和预训练模型结构保持一致。
推理任务中间加了一个delimiter,将推理任务输入的premise和hypothesis分开,同时保持了其语序一致。
语义相似性任务和推理任务类似,但由于其语义没有前后的因果关系,为保持text1和text2地位相等,所以用了两个模型,最后用element-wise地相加把它们结合起来。
QA任务中context由document和question拼接而成,对每个answer分别进行配对,然后分别输入到模型中,最后用一个softmax layer进行归一化。
Experiment
本文进行的12项NLP任务分别为:
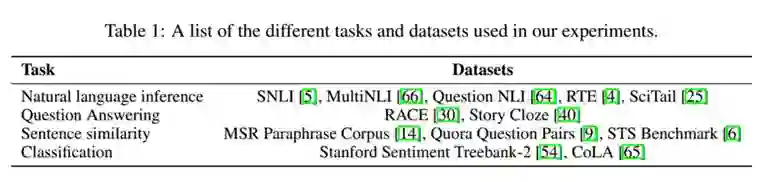
推理任务的实验结果:
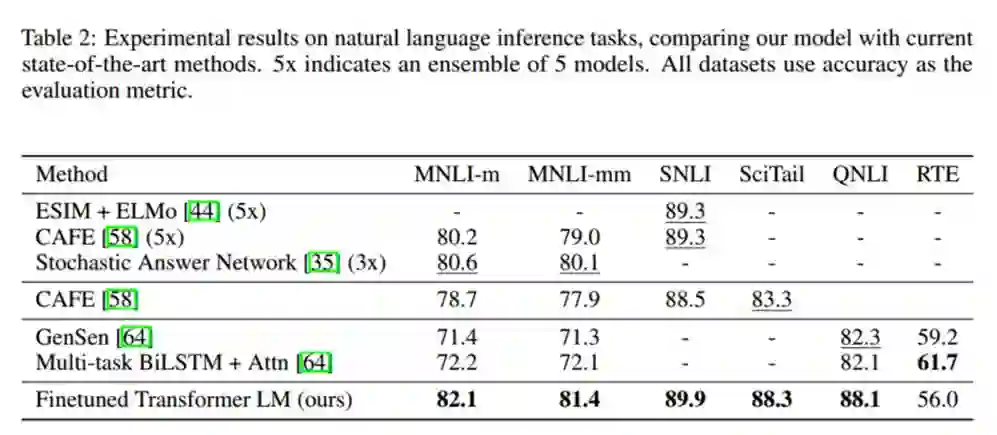
QA任务的实验结果:
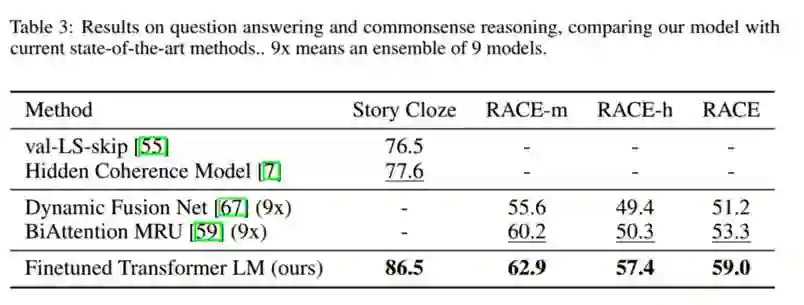
分类任务和语义相似性任务的实验结果:

12项实验中9项超过当前最好准确率,其中在 Stories Cloze Test上提高了8.9%,在RACE上提高了5.7%,都是比较显著的提高。
杨海宏,浙江大学直博生,研究方向:知识问答与推理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。




