全面讨论泛化 (generalization) 和正则化 (regularization) — Part 1

1. 定义:正则化(regularization)是所有用来降低算法泛化误差(generalization error)的方法的总称。
2. 正则化的手段多种多样,是以提升 bias 为代价降低 variance。
3. 现实中效果最好的深度学习模型,往往是【复杂的模型(大且深)】+【有效的正则化】。
1. Norm penalty:常用 L1/L2 regularization,理论机制不同,按特征方向重要性,L1 以阈值“削砍”参数分量,L2 “缩水”参数分量;深度学习中的实现方式有【weight decay】和【硬约束(重投影)】两种,各有不足。
2. L2-regularization 的特殊作用:解决【欠定问题】,调整协方差矩阵(covariance matrix)使其可逆。
3. Dropout layer 与 batchnorm layer:dropout 本质是一种 ensemble method;dropout 与 batchnorm 用于 regression 时有弊端;同时使用时理论上有冲突。
4. 深度学习的 Early stopping:减少 overfit 之后无意义的训练。

引子(可以速读或略过哦)

Norm Penalty,及其深度学习中的实现方式
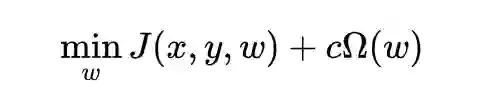
2.1 从理论角度看L2-regularization的机制
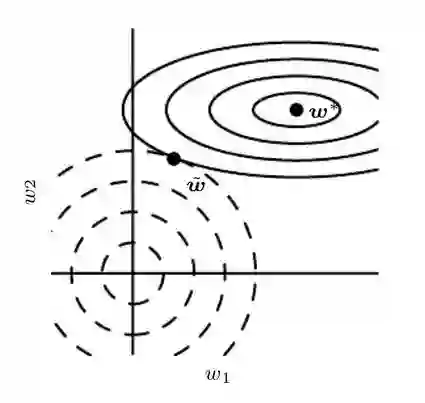
2.3 实现方式:weight decay与reprojection
2. 给每层 NNlayer 不同的 decay?研究发现,在神经网络中,有时候每一层 layer 使用不同的 weight decay 常数会得到更好的效果。但是可能的组合太多了,很难找到最正确的配置。

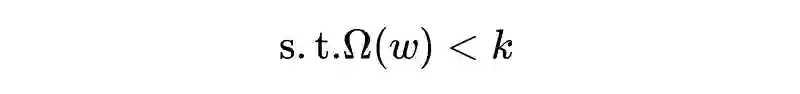
对每一层神经网络的参数矩阵,约束其列向量的 norm,而不是整个矩阵的 norm。这样可以有效防止某一个神经元的 weight 过大。分析发现,这其实等价于对每个神经元的 weight,用不同的常数来做 weight decay。
2. 重投影稳定性更高,可以使用较大的 learning rate。Hinton 的研究提出使用硬约束+大 learning rate 来快速探索参数,并保持稳定性。
4. 选定常数后,weight decay 可以在更新参数的同时一步实现,但重投影则需要额外的步骤。

L2-regularization与【欠定问题】
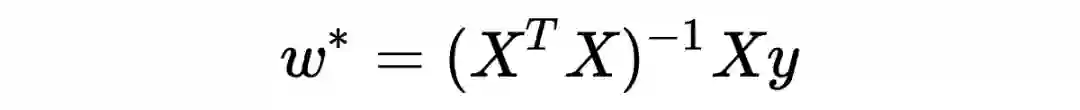
此时的解决方案之一就是采用ridge regression,优化问题变成了
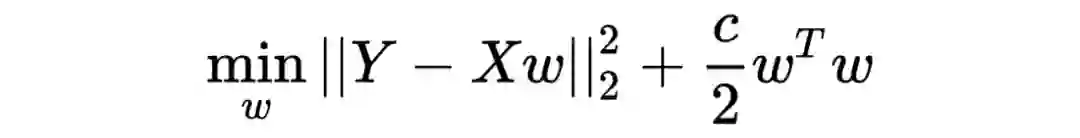
数学上与 L2-regularization 一模一样, 此时的解变成了
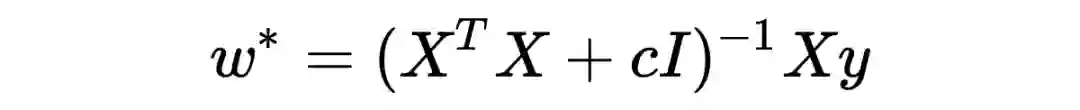
求逆的矩阵一个满秩的可逆矩阵,使欠定问题得以求解。从特征值的角度解释,协方差矩阵的特征值都是非负的,ridge regression 使所有特征值增加 c,保证所有特征值都为正,矩阵变得可逆。

Dropout layer
4.1 促进泛化的机理是什么呢
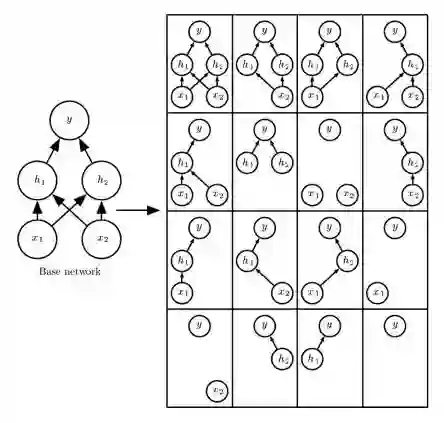
▲ Dropout layer:原模型用不同的遮盖方式,对应不同的子模型,训练的过程其实是在训练这些子模型的集合
4.2 什么情况下dropout没有用,甚至使结果变差?
4.3 与batchnorm一起使用时的问题:variance shift
实际上,我们经常发现 dropout 和 batchnorm 一起使用,比如 DNN 中这样搭配
layers = [
nn.Linear(in_size, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Dropout(0.2),
......
然而,有研究提出,dropout 和 batchnorm 一起用时有可能会使效果变差,这是因为,当我们结束训练进入测试时,dropout 会改变一个神经元的方差(variance),而 batchnorm 由于归一化,在测试时,则会致力于保持训练时所累积的统计方差。这种 variance 上的冲突,被称为 variance shift,研究发现他会导致测试阶段不稳定。有兴趣的可以详细阅读这篇文章“Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift”。

Early stopping
预热时长 -n:先预训练 n 个 epochs,不测试模型,之后开始训练+测试+训练+测试.....
耐心 -p:当连续 p 个 epochs 都观测到测试结果变差,则放弃训练
最佳模型:训练过程中保存和更新迄今为止的最佳模型
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧





