浅聊对比学习(Contrastive Learning)第二弹:MINE+SimCLR+SimCLRV2

©作者 | 吴桐
研究方向 | 推荐系统
本文接上篇文章:
浅聊对比学习(Contrastive Learning)第一弹
这次主要是想记录下最近读的三篇对比学习的经典 paper:
SimCLR-A Simple Framework for Contrasting Learning of Visual Representations
https://arxiv.org/abs/2002.05709
https://arxiv.org/abs/2006.10029
https://arxiv.org/abs/1801.04062
题外话:SimCLR 和 SimCLRV2 看完后觉得 CV 的炼丹之路:路漫漫其修远兮。

SimCLR
在组内做paper reading的记录:
https://bytedance.feishu.cn/docx/doxcn0hAWqSip1niZE2ZCpyO4yb
顺带安利下公司的飞书文档,YYDS!
最近学到一个新词儿:「缝合怪」~
1.1 One Sentence Summary
-
loss 就是 softmax loss + temperature -
这里有个需要注意的点,他在学到的 f 后面加了一个 g,然后进行 loss 的计算和梯度的回传,最后真正在使用的时候用的只有 f,这里作者的猜想和实验确实很有意思,很值得借鉴。(虽然在 SimCLRV2 中这个结论有变的很不一样了哈哈哈,后面会讲到) -
框架图:模型训练的时候 f 和 g 同时训练,但是训练完后,就把 g 扔掉了,只保留 f,这里是我觉得这篇论文最有意思的点,一般的思路其实应该是直接用 f 的输出去计算对比学习的 loss~

-
代表 data augmentation 方式的集合:比如旋转,灰度,裁剪等等 -
batch_size = N,对每个 batch 内的每张图片,随机从 中选择两种 data augmentation,得到两张图片,这两张图片就是一个正样本对,总共可以生成 2N 个样本,每个样本有一个样本和自己是正样本对,剩下的 2N-2 都是负样本,这里是用了一个 softmax+temperature 的 loss。

1.3 实验
实验图太多就不贴了,想看 detail 的可以直接看我的 paper_reading 记录:
https://bytedance.feishu.cn/docx/doxcn0hAWqSip1niZE2ZCpyO4yb
只对个人认为有意思的点说下。
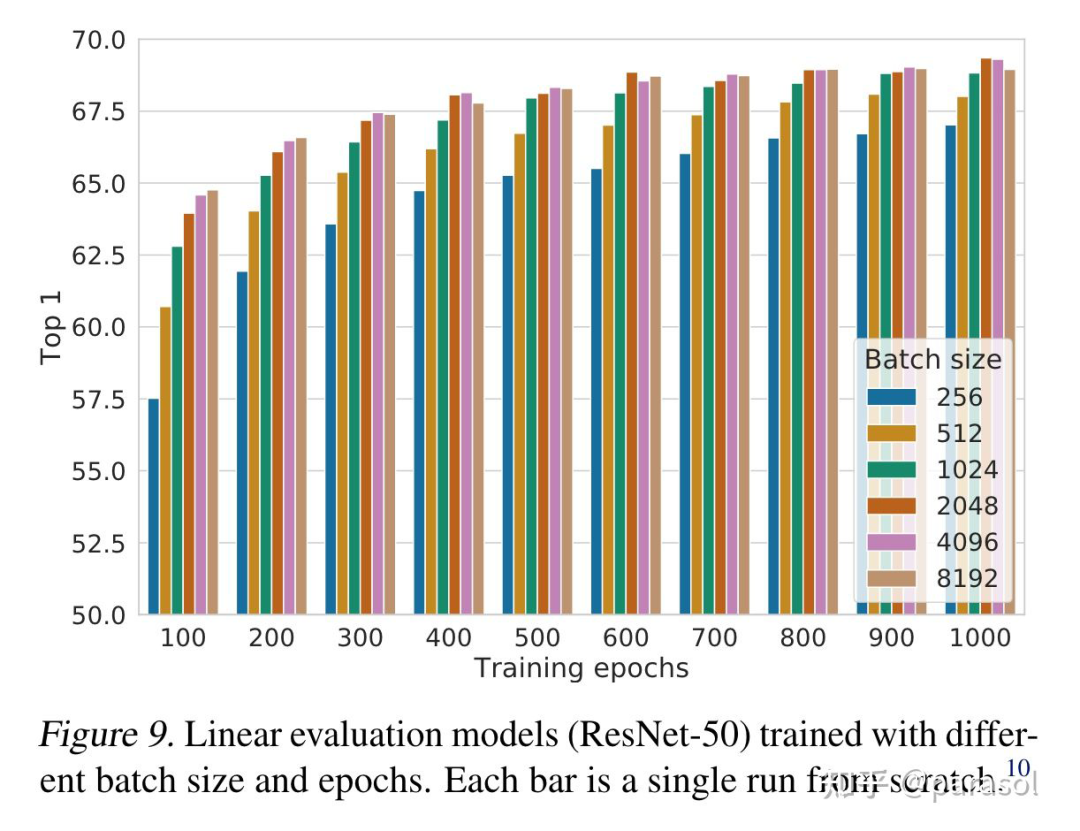
● 实验证明对比学习可以从更大的 batch size 和更长的训练时间上受益
作者自己在这里也说:效果的提升是来自于 batch_size 越大,训练时间越久,见过的负样本越多,所以效果越好,这里其实和 batch_softmax 也有异曲同工之妙,在推荐里其实也有类似的经验~
● 验证在对比学习 loss 计算之前加入一个非线性的映射层会提高效果
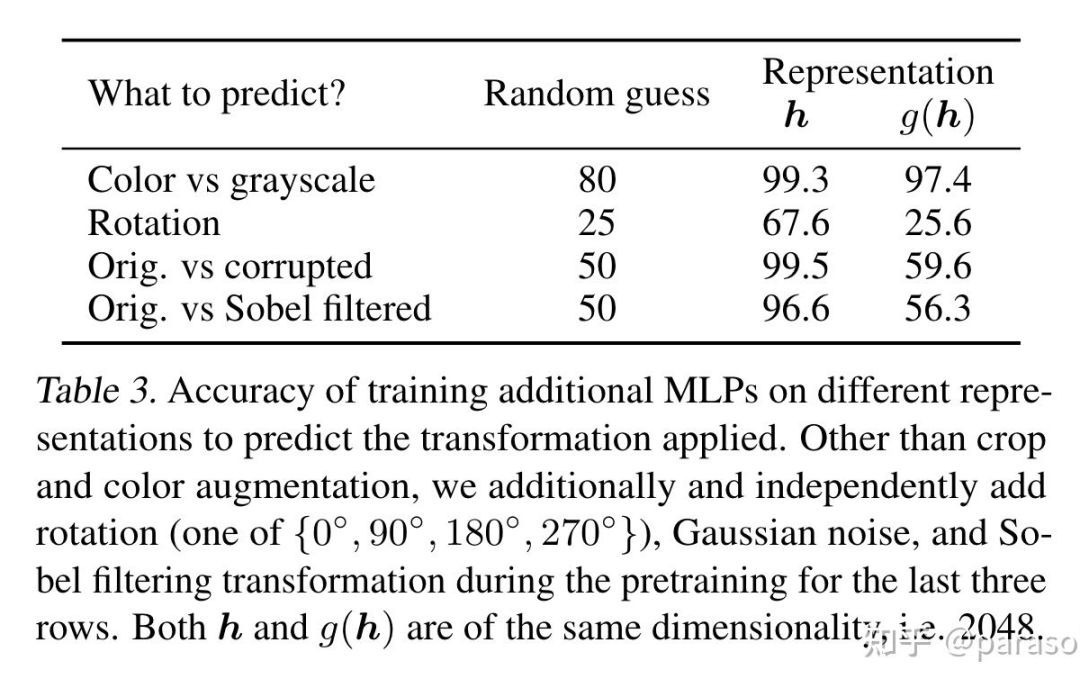
作者认为是 g 被训练的能够自动去掉 data transformation 的噪音,为了验证这个猜想,作者做了这个实验:用 h 和 g(h) 来区分做了哪种 data transformation,从下面第二张实验结果图看出,h 确实保留了 data transformation 的信息。
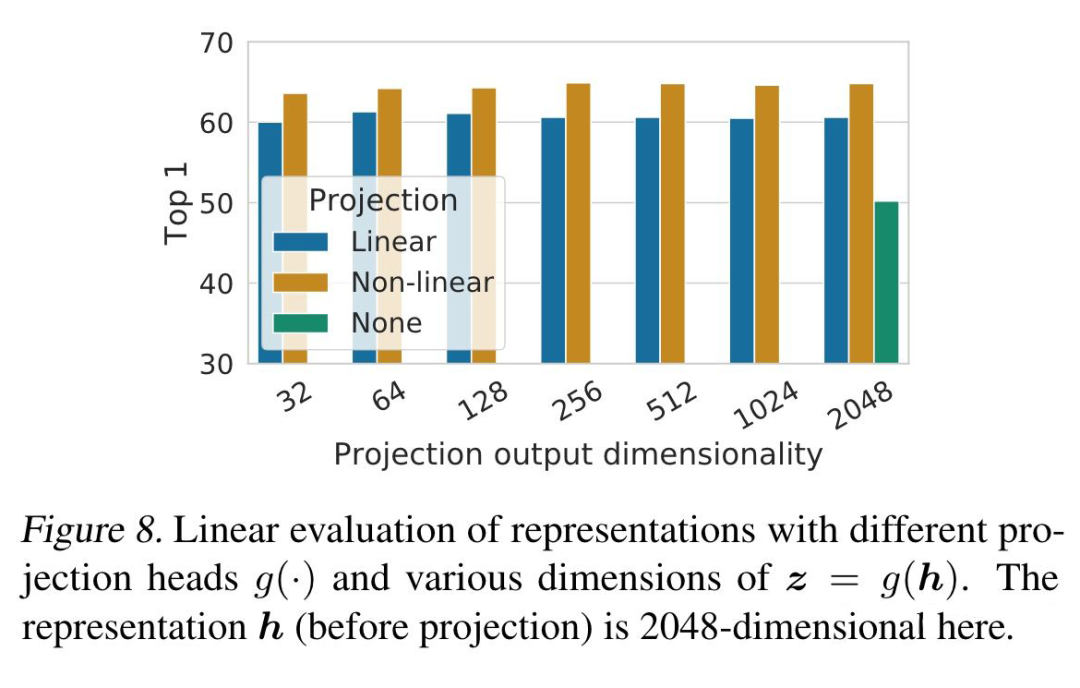
▲ Furthermore, even when nonlinear projection is used, the layer before the projection head, h, is still much better (>10%) than the layer after, z = g(h), which shows that the hidden layer before the projection head is a better representation than the layer after
实验证明「组合不同的 data augumentation」的重要性
实验证明对比学习需要比有监督学习需要更强的 data agumentation
实验证明无监督对比学习会在更大的模型上受益
实验证明了不同 loss 对效果的影响

SimCLRV2
在组内做 paper reading 的记录:
https://bytedance.feishu.cn/docx/doxcn9P6oMZzuwZOrYAhYc5AUUe
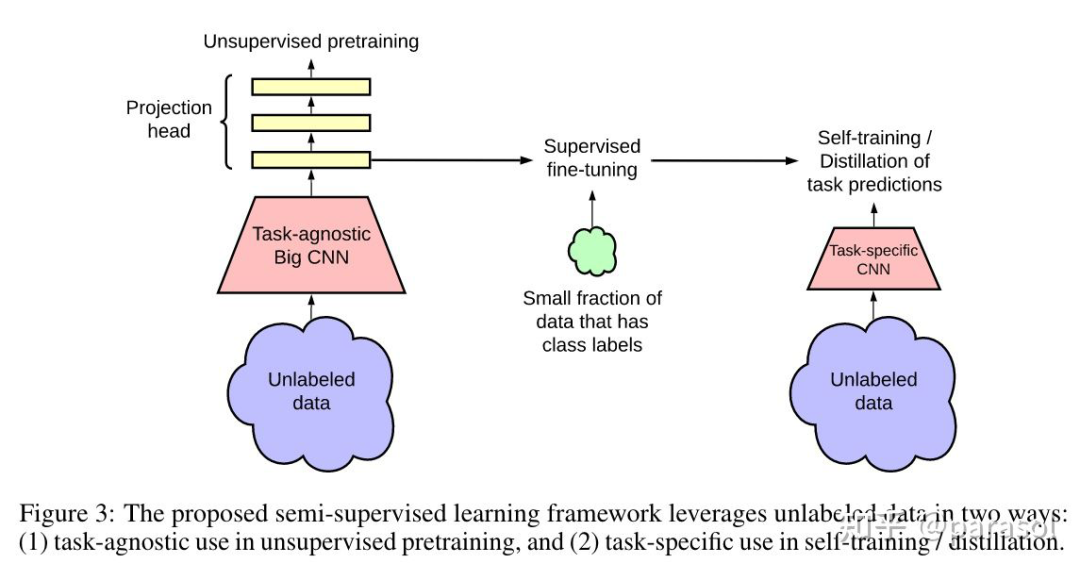
Pretraining:用了 SimCLR,然后用了更深的 projection head,同时不是直接把 projection head 丢了,而是用 projection head 的 1st layer,来做后面的 fine tune。。。(这也太 trick 了吧)
Fine-tune:用 SimCLR 训练出来的网络,接下游的 MLP,做 classification 任务,进行 fine-tune。
-
disitill:用训好的 teacher network 给无 label 的数据打上标签,作为 ground truth,送给 student network 训练。这个地方作者也尝试了加入有标签的(样本+标签),发现差距不大,所以就没有使用有监督样本的(样本+标签)。
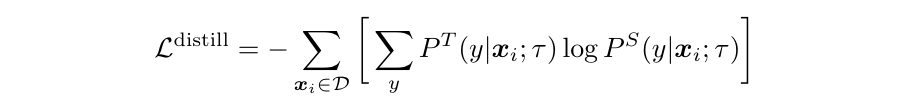
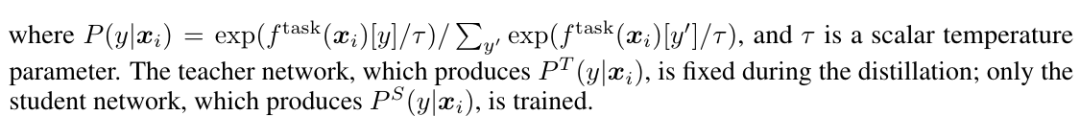
实验图就不全贴了,想看 detail 的可以直接看我的 paper_reading 记录:
https://bytedance.feishu.cn/docx/doxcn9P6oMZzuwZOrYAhYc5AUUe
只对个人认为有意思的点说下。
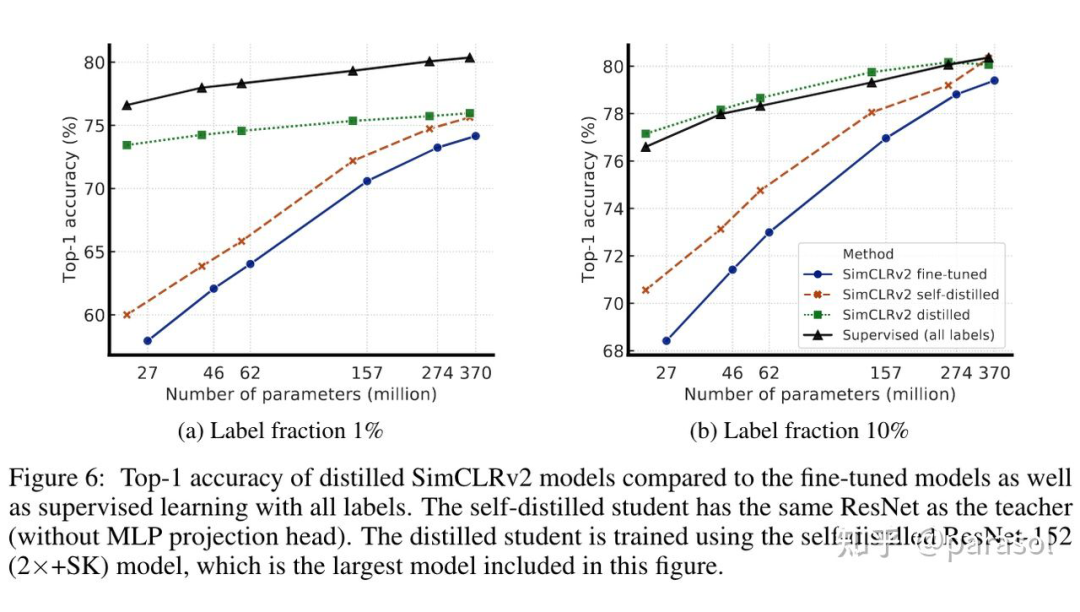
看一张放在论文首页的图吧(按照李沐大神的话说,放在首页的图一定是非常牛逼的图!),确实可以看出只用 1% 的数据+标签,就能获得到和有监督学习用 100% 数据+标签的效果;用 10% 的数据+标签就已经超过 SOTA 了,确实还是挺牛逼的。

● Distillation Using Unlabeled Data Improves Semi-Supervised Learning
这个实验很有意思的点是,无论是 self-distillation 还是 distill small model,效果都比 teacher model 效果好,这里的解释可以看这里:Link | arxiv,很有趣~主要在说:distill 能让 student 学到更多的视图,从而提升了效果~
● Bigger Models Are More Label-Efficient
● Bigger/Deeper Projection Heads Improve Representation Learning

MINE
在组内做 paper reading 的记录:
https://bytedance.feishu.cn/docx/doxcnMHzZBeWFV4HZV6NAU7W73o
-
给定一个 batch 内的数据 ,其中 就是我们的训练集,batch_size = b。 然后从训练集中随机 sample b 个 z,作为负样本。
-
计算 loss,并回传梯度。

实验图就不全贴了,想看 detail 的可以直接看我的 paper_reading 记录:
https://bytedance.feishu.cn/docx/doxcnMHzZBeWFV4HZV6NAU7W73o
只对个人认为有意思的点说下。




参考文献
[1] 极市平台:深度学习三大谜团:集成、知识蒸馏和自蒸馏
[2] Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607.
[3] Chen T, Kornblith S, Swersky K, et al. Big self-supervised models are strong semi-supervised learners[J]. Advances in neural information processing systems, 2020, 33: 22243-22255.
[4] Belghazi M I, Baratin A, Rajeshwar S, et al. Mutual information neural estimation[C]//International conference on machine learning. PMLR, 2018: 531-540.
[5] Allen-Zhu Z, Li Y. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning[J]. arXiv preprint arXiv:2012.09816, 2020.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

