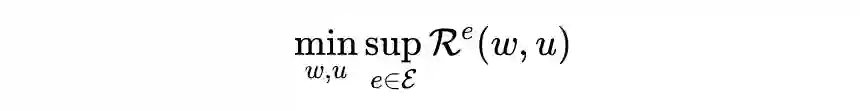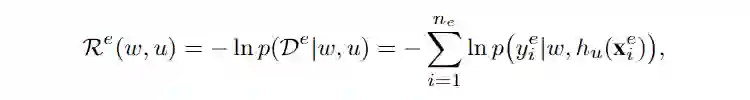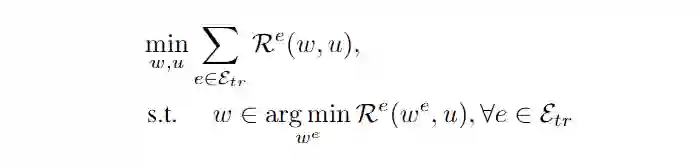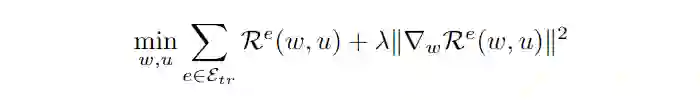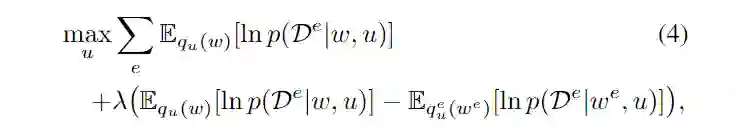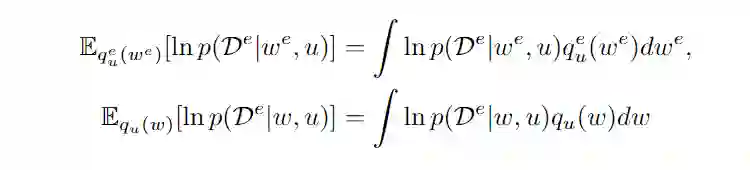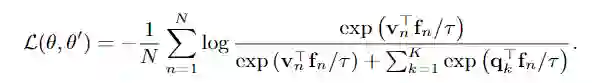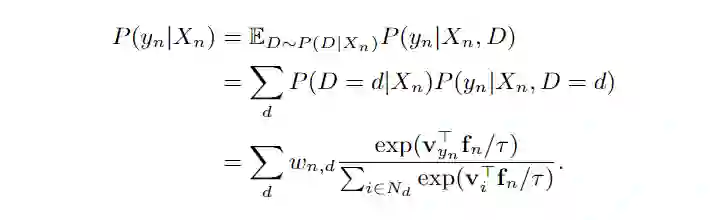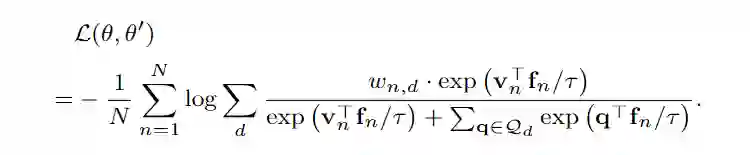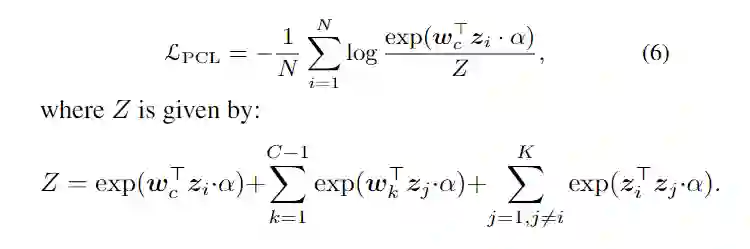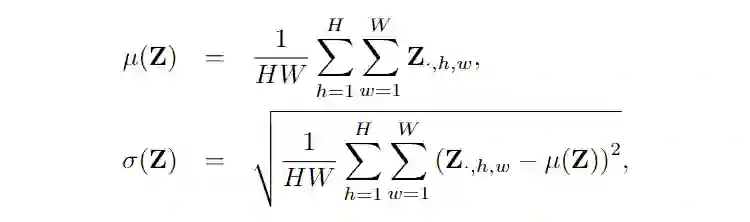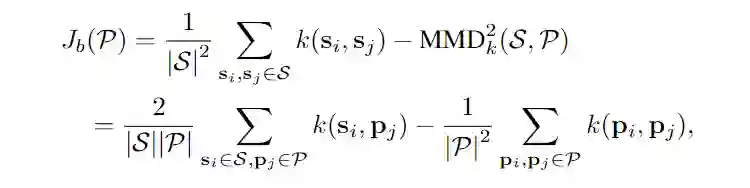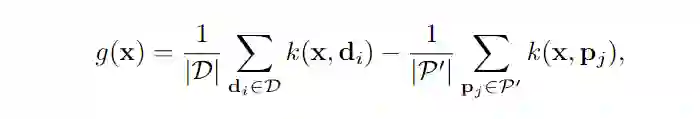![]()
©PaperWeekly 原创 · 作者 | 张一帆
单位 | 中科院自动化所博士生
研究方向 | 计算机视觉
Domain Adaptation(DA:域自适应),Domain Generalization(DG:域泛化)一直以来都是各大顶会的热门研究方向。DA 假设我们有有一个带标签的训练集(源域),这时候我们想让模型在另一个数据集上同样表现很好(目标域),利用目标域的无标签数据,提升模型在域间的适应能力是 DA 所强调的。以此为基础,DG 进一步弱化了假设,我们只有多个源域的数据,根本不知道目标域是什么,这个时候如何提升模型泛化性呢?核心在于如何利用多个源域带来的丰富信息。本文挑选了四篇 CVPR 2022 域泛化相关的文章来研究最新的进展。
![]()
![]()
![]()
Bayesian Invariant Risk Minimization
论文链接:
https://openaccess.thecvf.com/content/CVPR2022/papers/Lin_Bayesian_Invariant_Risk_Minimization_CVPR_2022_paper.pdf
1.1 Motivation
分布偏移下的泛化是机器学习的一个开放挑战。不变风险最小化(IRM)通过提取不变特征来解决这个问题。虽然 IRM 有着完备的理论体系,但是在深度模型上表现往往不是很好,本文认为这种失败主要是
深度模型容易过拟合
引起的,并理论验证了当模型过拟合时,IRM 退化为传统的 ERM。本文将 Bayesian inference 引入 IRM 提出了 Bayesian Invariant Risk Min-imization(BIRM)来一定程度上缓解这个问题并取得了不错的效果。
1.2 Background
这里简单介绍一下 OOD 问题与 IRM,所谓的 OOD 问题可以写为如下形式
![]()
即寻找最优的分类器,encoder 参数
使得模型在表现最差的域都有比较好的性能,i.e.,
。这里的
是域
中数据的负对数似然:
![]()
Invariant Risk Minimization(IRM)
. IRM 要解决如下问题:
![]()
即他要学习一个 encoder 参数
,这个 encoder 对所有的分类器参数
都同时是最优的。为了完成这个目标,encoder 需要抛弃掉 spurious feature。但是这个优化形式 bi-level 的,非常难解决,因此他又提出了一个近似的 target。
![]()
1.3 The Overfitting Pitfall
本文的理论分析基于两个假设:
1. Finite Sample Size:即每个域的数据量有限。
2. Sufficient Capacity:即模型有能力记住所有数据点,也就是所谓的overfitting。
,这里
是训练数据。
这里引入一个定义,Overfitting Region:。文章的第一个发现
Proposition 1
。
在上述假设条件下,IRM 在
上会退化为 ERM,除此之外,任何
上的元素都是 IRM 的一个解。
也就是说,无论模型是否使用了 spurious feature,只要他能够拟合所有训练数据,那么他就是 IRM 的一个解,这是非常恐怖的,因为这类模型在其他测试分布的表现可能会任意差。
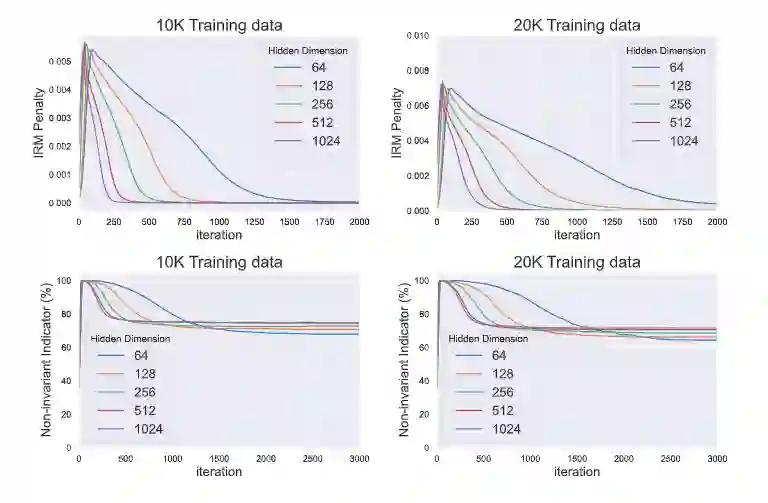
文章使用在 CMNIS T 上的一个小实验来验证他的理论结果,如下所示:
![]()
IRM 的惩罚项,即上面两张图的 penalty 被测量,但训练的时候不使用。随着 ERM 训练的进行,IRM 惩罚衰减到零,而非不变指标表明模型中存在大量的虚假特征。模型越大,训练数据越少,IRM 惩罚消失的速度越快。
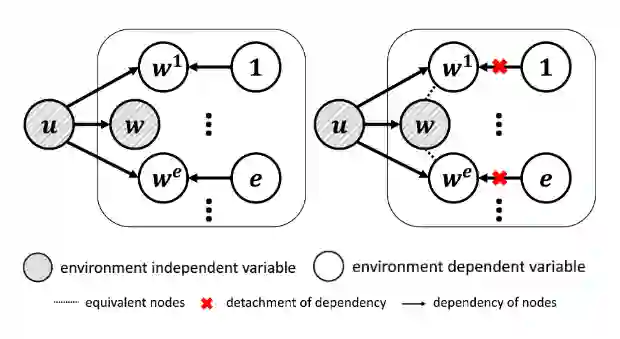
1.4 Bayesian Invariant Risk Minimization
Bayesian iinference 是一种缓解过拟合的著名方法,它被证明可以在模型错误描述的情况下实现最优样本复杂度。
![]()
问题定义如上图所示,如果我们给每个 domain 一个 classifier
,那么各个域的后验概率
是不同的,为了要每个 domain 的后验概率相同,本文使用了如下的 target:
![]()
![]()
IRM 的基本定义是基于
的单点估计,当数据不足时,这可能是高度不稳定的。相对于点估计,BIRM 是由后验分布直接引起的,不太容易过拟合。文章还提出了一些其他 trick 比如 ELBO,Variance Reduced Reparameterization 等来帮助算法估计后验概率以及更快的收敛。
1.5 Experiments
作者在几个半生成数据集上验证了他的算法,在它 involved 的数据集上都取得了不错的效果,但是实用性依然存疑,个人认为该算法与 IRM 可能一样,在比较大的 benchmark 上效果可能不会太好,实际上当数据集较大甚至中等大小的时候,像 PACS 数据,ERM 在多个域的损失也不会很轻易的降到 0。
![]()
Towards Unsupervised Domain Generalization
论文链接:
https://arxiv.org/abs/2107.06219
2.1 Motivation
目前的 DG 算法大多采用在大数据集上预训练的 backbone,然后开发算法在下游数据集上进行 finetune,最后在 unseen 的数据集上进行测试。但是预训练的数据集会引入认为的 bias,比如 imagenet 的图像大多来自于真实世界,因此其预训练的模型在下游任务上非真实数据(手绘图像,漫画图像)表现就会很差。本文考虑了一个新的 setting,即模型
先在多个源域上进行无监督的预训练
,然后进行传统 DG 的过程,抹去传统 pretrain 引入的 bias。
2.2 Method
本文的方法名称为 Domain-Aware Representation Learn-ING(DARLING),这个方法尝试使用自监督学习的技术来提升多域预训练的方法从而提升泛化性能。传统的自监督学习损失即:
![]()
这里的
是自监督中的 anchor 和 positive 特征,
和
是两个独立的 encoder,
是温度参数。但是这种方法没办法建模域信心,因为
在不同域实际上是不一样的。每个域
的条件分布可以写作:
![]()
这里
是域
所选的样本数目。最后,考虑域信息之后,我们的条件分布可以写作:
![]()
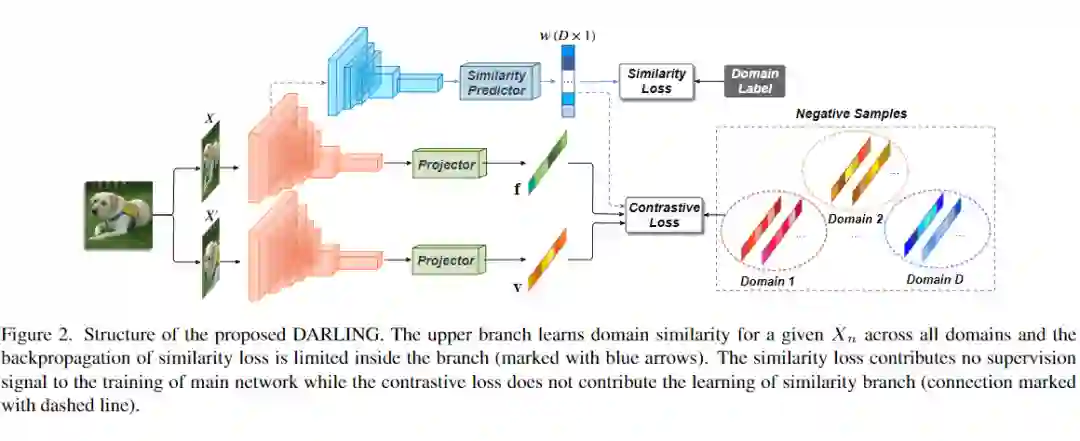
模型架构如下所示,这里的
是下面 similarity predictor 的输出。也就是说变成了各个 domain 对比学习损失的加权形式:
![]()
![]()
2.3 实验与结论
本文使用了四个数据集进行试验,分别是 DomainNet,PACS,CIFAR-10-C 以及 CIFAR-100-C,主要结论如下所示:
1. 使用 DARLING 进行预训练,所取得的泛化效果优于目前 SOTA 的自监督/以及传统预训练方法。
2. 类别数量以及数据量都会影响预训练的效果,而且往往呈现正相关。但是 DARLING 使用不到 imagenet 10% 的数据量就可以取得相近的效果。验证了 imagernet pretrain 并不是最优的。
3. 现有的 DG 方法通过结合 DARLING 预训练可以进一步提升性能。
![]()
PCL: Proxy-based Contrastive Learning for Domain Generalization
论文链接:
https://openaccess.thecvf.com/content/CVPR2022/papers/Yao_PCL_Proxy-Based_Contrastive_Learning_for_Domain_Generalization_CVPR_2022_paper.pdf
3.1 Motivation
本文也是与 contrastive learning 相关的一篇文章,一个简单的方法是将不同域的正样本对拉得更近,同时将其他负样本对推得更远。本文发现直接采用这种有监督的对比学习效果并不好,本文认为域之间存在的显著的分布差距,使得直接拉近正样本对的距离反而阻碍了模型的泛化。因此本文提出了一个新的基于原型(proxy)的对比学习方法。
3.2 Method: Proxy-based Contrastive Learning
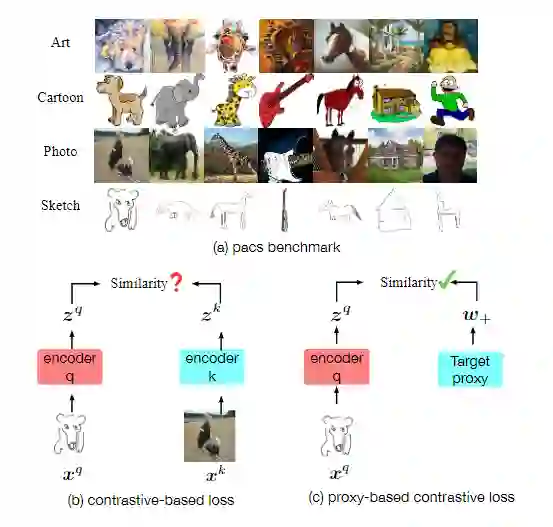
首先我们来看一下,基于原型的自监督学习方法与传统自监督学习方法有什么差别。如下图所示:
![]()
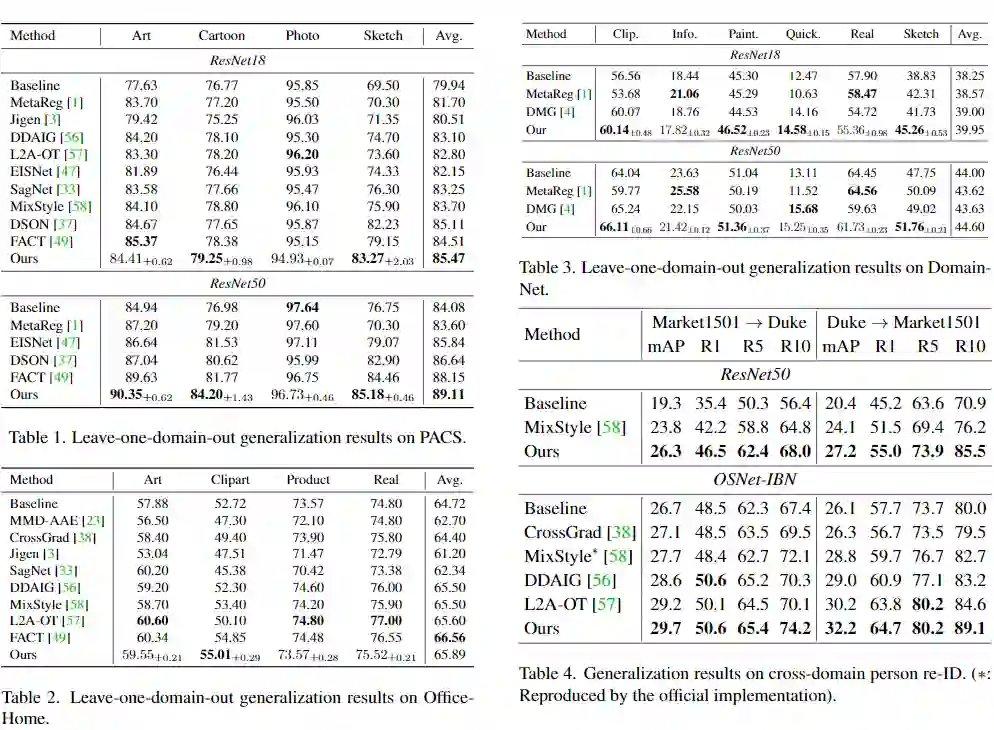
PACS 数据集是一个典型的领域泛化基准,它包含四个领域:艺术、漫画、照片和素描,每个领域有七个类别。DG 从多个源域(如艺术、照片、素描)训练模型,并在目标领域(如漫画)上进行测试。在训练阶段,目标数据集不能被访问。
传统的基于对比的损失
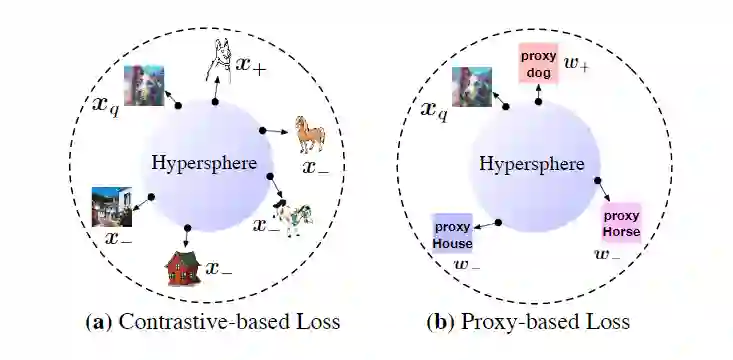
(例如,监督对比损失)利用其样本到样本的关系,其中来自同一类的不同域样本可以被视为正对。我们认为,优化一些难正样本对可能会恶化模型的泛化能力。本文称之为正对齐问题( positive alignment problem)。因为各个域之间的 gap 有可能会非常大,因此直接对齐不同域的正样本反而可能对模型有害。本文提出了基于原型的对比损失来解决这个问题。二者的具体区别如下所示:
![]()
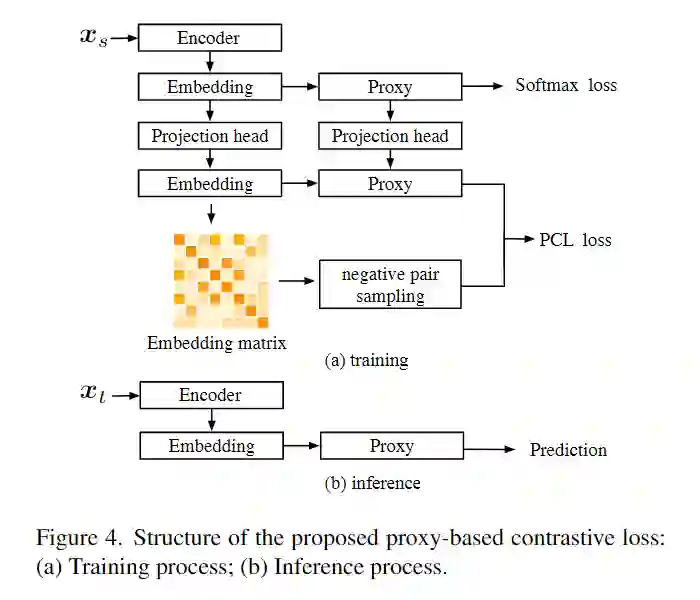
对传统 self-supervised learning 而言,优化的是样本到样本的距离,而本文的方法优化的是样本到原型,原型到原型之间的距离。本文整体的架构如下所示:
![]()
这里的 PCL loss 也即是基于原型的对比学习方法的核心,他的正样本即与他同类的 proxy,负样本是不同类的 proxy,与同一 mini-batch 的其他数据。
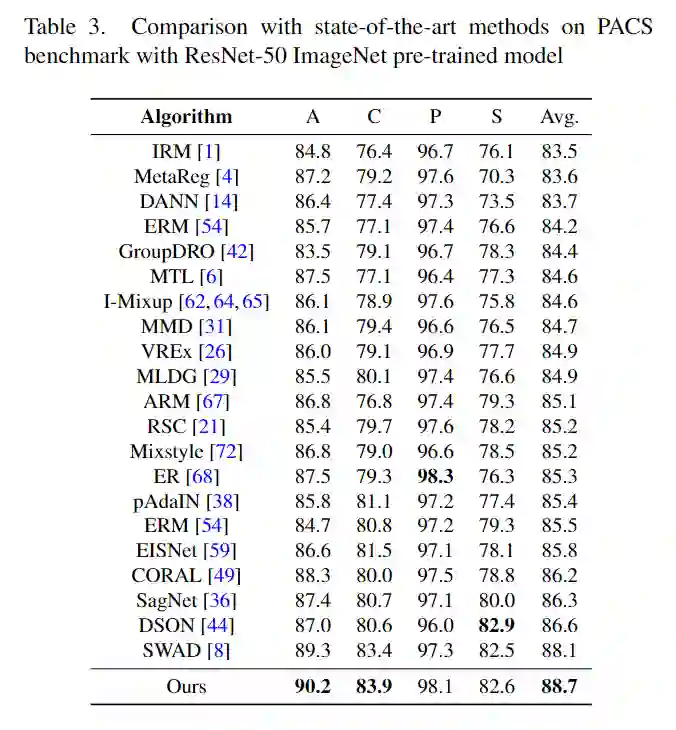
3.3 实验结果
在常见的几个 DG 数据集上都取得 SOTA 的性能。
![]()
本文更有趣的地方是在于他的假设,用 self-supervised learning 的方法做 DG 是很直观的,将不同 domain 同一类别的 feature 距离拉近,但是本文发现这种做法并不 work,并将方法做了小调整就取得了不错的性能。
Style Neophile
![]()
Style Neophile: Constantly Seeking Novel Styles for Domain Generalization
论文链接:
https://openaccess.thecvf.com/content/CVPR2022/papers/Kang_Style_Neophile_Constantly_Seeking_Novel_Styles_for_Domain_Generalization_CVPR_2022_paper.pdf
4.1 Motivation
目前大多数 DG 方法都提到要学一个 domain-invariant 的特征,这类方法通常假设每个域有不同的图像风格,然后 enforce 同一个类的图像在不同风格下的特征是尽可能相似的。而,这些方法被限制在一个有限的风格集合上(我们得到的域的数目是有限的),因为它们从一组固定的训练图像或通过插值训练数据获得增强的样式。本文提出了一种新的方法,能够产生更多风格的数据,这些风格甚至是完全没有在训练集出现过的。
4.2 Method
本文刻画所谓图像风格的方式即使用图像的均值和方差,对于图像的 feature map
,我们有
。
![]()
![]()
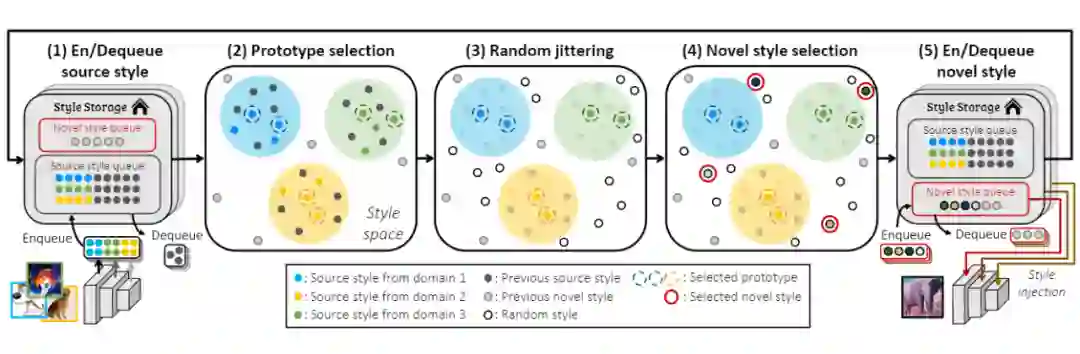
首先模型维护了两个 queues。一个存储训练图像的风格(source style queue SSQ),一个存储合成图像的风格(novel style queue)。
合成图像风格的生成:
1. Prototype selection. 在 SSQ 中选择
个原型,假设
分别是 SSQ 中的全部风格和我们选择的原型。为了选出最具代表性的
,这一步的得分函数定义如下:
![]()
这里的
是 MMD 所使用的核函数。
的选择要尽可能使得这个得分最高。由于 radial ba-sis function(RBF)kernel 是单调且具有次模性质的,因此这个优化的实现,实际上是贪婪地选择使得分最大的原型来完成的。
2. Random jittering for style candidates. 所选原型添加高斯噪声
,这里 λ 为标量超参数;高斯分布的标准差与 σ(S) 成比例。
3. Novel style selection。为了保证生成风格的多样性,本文选择了一些新颖的样式,这些样式不能被观察到的样式的近似分布很好地代表。这里用
表示可观测风格,
是之前生成的风格队列。为了定量的评估生成特征的多样性,本文采用了如下 metric:
![]()
其中,第一项衡量与生成风格的相似性,第二项衡量生成风格与观察到的风格的相似性。将该函数最大化的新风格将很好地代表新风格,同时有别于观察到的风格。同时本文还添加了 log-determinant regu-larizer,在优化过程中 log-determinant regu-larizer 鼓励了所选风格的多样性,并具有次模函数的性质。
最后就是训练方法的改进了,有了这些新生成的数据,我们当然可以直接执行 DG 的方法,毕竟上述的过程实际上就是一个数据增强。本文在此基础上给出了额外的约束条件,不过总的核心思想就是即使 style 发生了改变,模型的预测结果也应该尽可能相似。
该方法在多个 DG 数据集上取得了不错的效果,但是由于方法复杂性较高,会比较难 follow。
![]()
本文挑选了四篇 CVPR 与 DG 相关的文章,他们分别从因果不变性,预训练方式,自监督学习 +DG 以及数据增强四个方面提出了新的方法,克服了以往的缺陷。但就目前而言,仍然没有一个里程碑式的方法可以在绝大多数 OOD 的 benchmark 上展现出压倒性效果,更好更快更强的方法仍然是目前所缺少的。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()