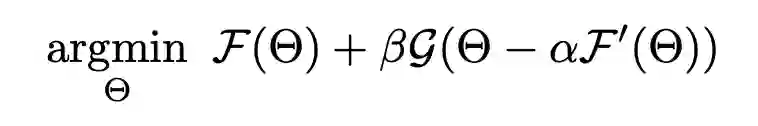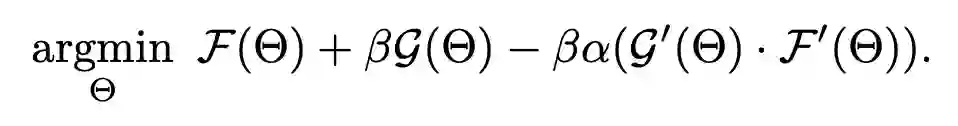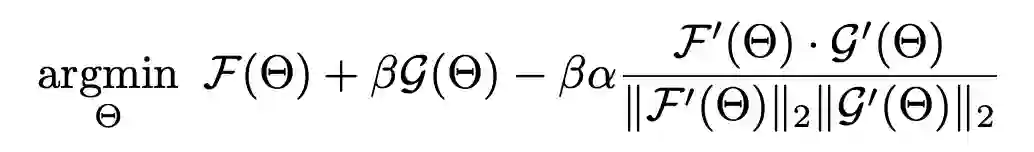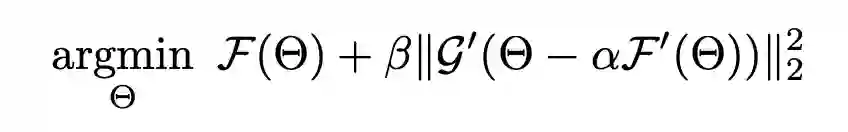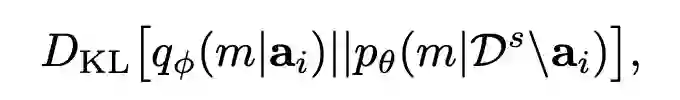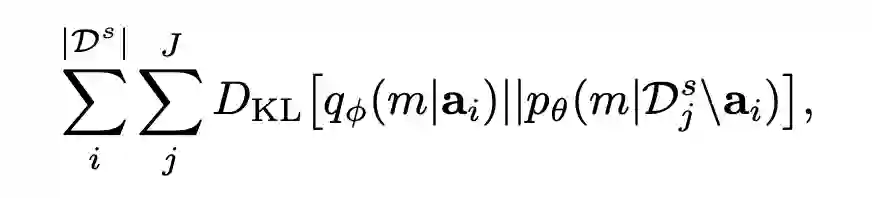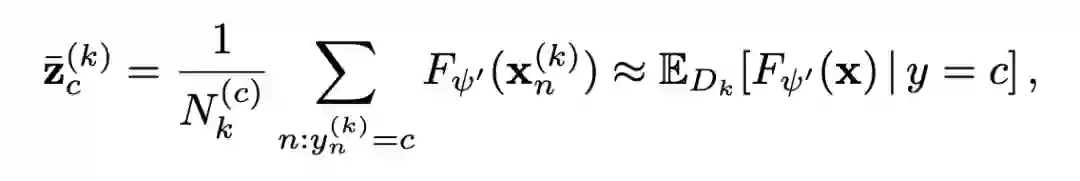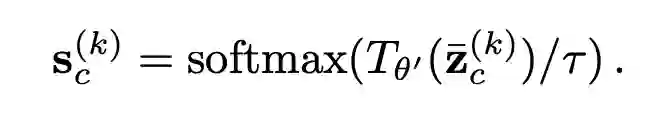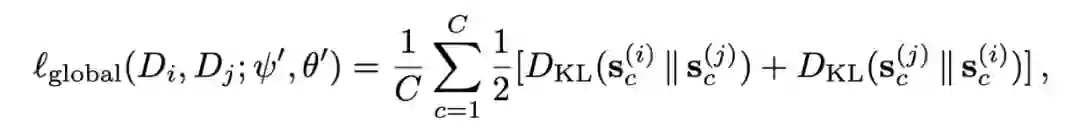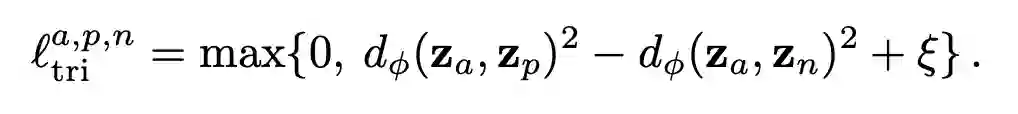这揭示了目标函数一是要最小化在 meta-training set 和 meta-testing set 上的误差(上式第一第二项),二是使 meta-training set 和 meta-testing set 的优化方向最大程度地相似(上式第三项)。显然,如果目标函数是 ,模型很可能偷懒,找一个容易使该式最小化的源域的梯度方向进行优化,从而过拟合这个源域。而 meta leanring 的目标函数函数加上了这个正则化约束,就促使模型考虑所有源域的梯度方向。因此作者还给出下面两种改进的 meta learning 目标函数,可以替代上式的点积计算相似度。
第一种改进是将点积替换成余弦相似度。第二种是退化为用 meta-training set 的方向优化 meat-testing set,这种方式关键是需要模型有好的初始化。 3.2 解决DG中的Batch Normalization问题
论文标题:
MetaNorm: Learning to Normalize Few-Shot Batches Across Domains
Recall that in this setting, we have access to target labeled data for only half of our categories. We use soft label information from the source domain to provide information about the held-out categories which lack labeled target examples.
一个好的特征空间自然是不同 domain 的数据尽量混在一起难以区分,不同 class 的数据尽量形成良好的聚簇。作者就此分别对语义空间和特征空间采用了不同的操作。 首先是语义空间。对于每个 domain,计算特征空间中属于同一 class 的样本的均值,作为这个 class 的 'concept',并通过 softmax 得到这个 class 的软标签。
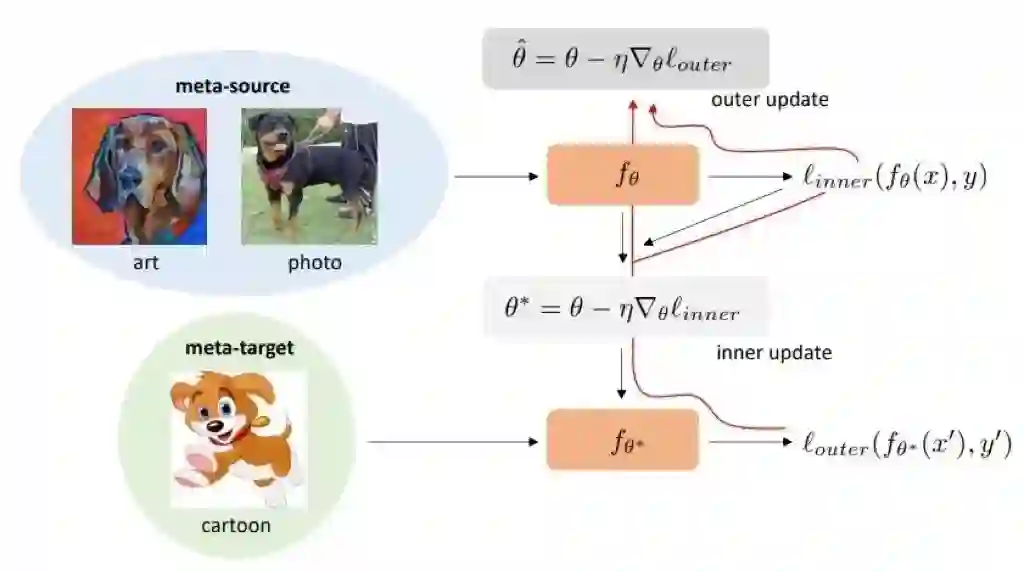
本文的训练数据同样被分为 meta-training set 和 meta-testing set 来模拟 distribution shift。
总结 Meta learning 就是通过对已有的数据作简单的划分模拟 distribution shift,使模型学得更 robust。它是一种训练的思路,可以和任何 DG 的模型结构结合来增强泛化性。 但是 meta learning 同样存在一些缺陷。一是虽然可能训练得到的模型对 distribution shift 不那么敏感,但仍不能避免模型对源域数据过拟合。二是模型每一层更新都要求两次梯度,计算效率自然会慢。