自定义损失函数Gradient Boosting

本文为 AI 研习社编译的技术博客,原标题 :Custom Loss Functions for Gradient Boosting
翻译 | 就2 校对 | Lamaric 整理 | 菠萝妹
原文链接:https://towardsdatascience.com/custom-loss-functions-for-gradient-boosting-f79c1b40466d
用于梯度提升的自定义损失函数
优化最重要
作者: Prince Grover and Sourav Dey

简介
梯度提升技术在工业上得到了广泛的应用,并赢得了多项Kaggle比赛。
互联网上有很多关于梯度提升的很好的解释(我们在参考资料中分享了一些选择的链接),但是我们注意到很少有人提起自定义损失函数的信息:为什么要自定义损失函数,何时需要自定义损失函数,以及如何自定义损失函数。
这篇文章中我们将总结自定义损失函数在很多现实问题中的重要性,以及如何使用 LightGBM gradient boosting(LightGBM渐变增强包) 实现它们。
优化机器学习算法通常是最小化训练数据的损失函数。
在一般的ML库中有许多常用的损失函数。如果你想了解更多这方面的知识,请阅读普林斯在攻读数据科学硕士学位时写的这篇文章。在现实世界中,这些“现成的”损失函数通常不能很好地适应我们试图解决的业务问题。所以我们引入自定义损失函数。
自定义损失函数

一个使用自定义损失函数的例子是机场准时的不对称风险。问题是:你要决定什么时候从家里出发,这样你才能在按时到达机场。我们不想太早走,在机场等上几个小时。同时,我们不想错过我们的航班。任何一方的损失都是不同的: 如果我们提前到达机场,情况真的没有那么糟;如果我们到得太晚而错过了航班,那真是糟透了。
如果我们使用机器学习来决定什么时候离开,我们可能想要在我们的模型中直接处理这种风险不对称,通过使用一个自定义损失函数来惩罚延迟错误而不是提早到达错误。
另一个常见的例子出现在分类问题中。例如,在疾病检测方面,我们可能会认为假阴性比假阳性严重得多,因为给健康人用药通常比不给病人用药危害小。在这种情况下,我们可能想要优化F-beta 分数,其中取决于我们想给假阳性的权重大小。这有时被称为内曼-皮尔逊准则(Neyman-Pearson criterion)。
在Manifold公司,我们最近遇到了一个问题,需要一个自定义损失函数。我们的客户之一Cortex Building Intelligence提供的一个应用程序,可以帮助工程师更精确地操作一栋建筑的供暖、通风和空调系统。大部分商业楼宇有“房东义务”,在办公时间内,例如在上午九时至下午六时的工作时间,把楼宇的室内温度调至“舒适”的温度范围,例如在70至74华氏度之间。同时,这种HVAC温控是建筑最大的运营成本。高效的HVAC运行的关键是在不需要的时候关闭系统,比如在晚上,然后在清晨再次打开,以履行“房东义务”。为了达到这个目的,Manifold帮助Cortex建立了一个预测模型,以推荐在建筑物中打开HVAC系统的确切时间。
然而,错误预测的惩罚不是对称的。 如果我们预测的开始时间早于实际所需的开始时间,那么建筑物将过早地达到舒适的温度并且会浪费一些能量。 但是如果预测的时间晚于实际所需的开始时间,那么建筑物将会来得太晚,租户也不会感到高兴——没有人想在寒冷/闷热的建筑物中工作,购物或学习。 因此,迟到比早期更糟糕,因为我们不希望租户(毕竟真金白银交了租金)不开心。 我们通过创建自定义非对称Huber损失函数在我们的模型中编码了这种业务知识,当残差为正与负时,该函数具有更高的误差。 有关此问题的更多详细信息,请参阅此文章。
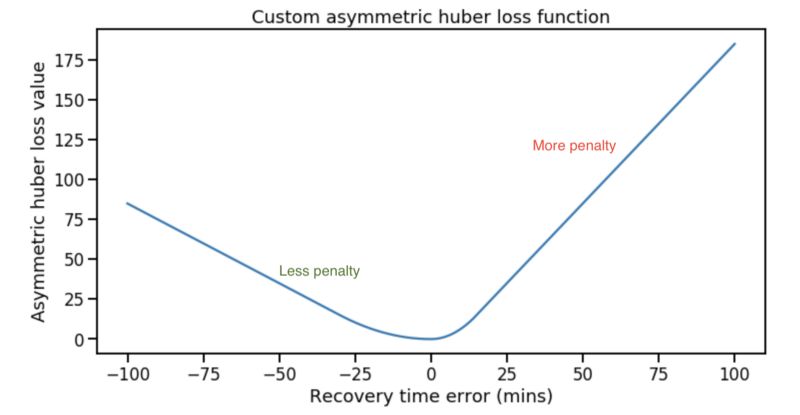
忽略恢复时间错误的含义
另外: 找到一个与你的商业目标紧密匹配的损失函数。通常,这些损失函数在流行的机器学习库中并没有默认的实现。但是没关系: 定义自己的损失函数并使用它来解决问题并不难。
自定义训练损失函数并验证
在进一步深入之前,让我们明确一下我们的定义。ML文献中使用了许多术语来指代不同的事物。我们将选择一组我们认为最清楚的定义:
1、训练损失。这是对训练数据进行优化的函数。例如,在神经网络二进制分类器中,这通常是二进制交叉熵。对于随机森林分类器,这是基尼指数。训练损失也常被称为“目标函数”。
2、验证损失。这是我们用来评估我们的训练模型在看不见的数据上的性能的函数。这通常与训练损失不同。例如,在分类器的情况下,这通常是接收器工作特性曲线下的面积(ROC) -虽然这从来没有直接优化,因为它是不可微的。这通常被称为“性能或评估度量”。
在许多情况下,定制这些损失可以真正有效地构建更好的模型。这对于梯度增强特别简单,如下所示。
训练损失
在训练过程中,训练损失得到优化。对于某些算法来说很难定制,比如随机森林(见这里),但是对于其他算法来说相对容易,比如梯度提升和神经网络。由于梯度下降的某些变体通常是优化方法,训练损失通常需要一个具有凸梯度(一阶导数)和海森(二阶导数)的函数。最好是连续的,有限的,非零的。最后一个很重要,因为函数为0的部分可以冻结梯度下降。
在梯度提升的背景下,训练损失是利用梯度下降法进行优化的函数,如梯度提升模型的“梯度”部分。具体来说,使用训练损失的梯度来改变每个连续树的目标变量。(如果你对更多细节感兴趣,请看这篇文章。)请注意,即使训练损失定义了“梯度”,每个树仍然需要使用贪婪分割算法来生长,而不是绑定到这个自定义损失函数。
定义一个定制的训练损失通常需要我们做一些微积分来找到梯度和海森(矩阵 Hessian matrix)。正如我们接下来将看到的,首先更改验证损失通常更容易,因为它不需要太多的开销。
验证损失
验证损失用于优化超参数。它通常更容易定制,因为它不像训练损失那样有很多功能需求。验证损失可以是非凸的、不可微分的和不连续的。因此,从定制开始通常更容易。
例如,在LightGBM中,一个重要的超参数是增加轮数。验证损失可用于找到最佳数量的助推轮次。这种LightGBM中的验证损失称为
eval_metric
我们可以使用库中可用的验证损失之一,或者定义我们自己的自定义函数。因为它非常简单,如果它对您的业务问题很重要,那么您一定要自定义。
具体来说,我们通常使用early_stopping_rounds变量,而不是直接优化num boosting rounds。当给定数量的早期停止轮次的验证损失开始增加时,它会停止提升。实际上,它通过监视样本外验证集的验证损失来防止过拟合。如下图所示,设置更高的停止轮次会导致模型运行以进行更多提升轮次。
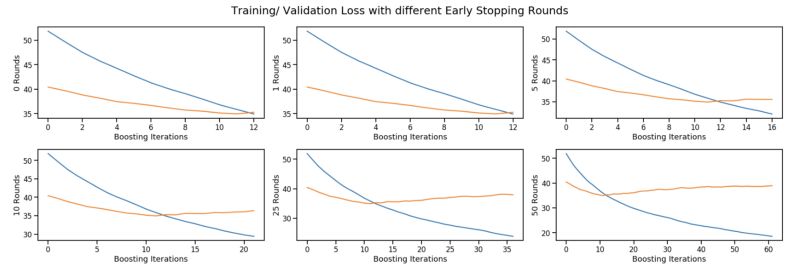
蓝色:训练的损失。橙色:验证损失。训练和验证都使用相同的自定义损失函数
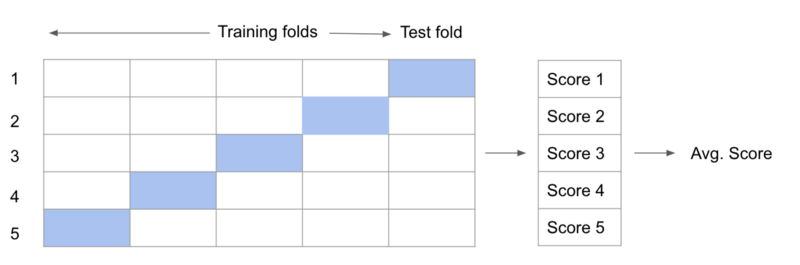
k-fold交叉验证。每个测试评分与验证损失
记住,验证策略也非常重要。上面的训练/验证分离是许多可能的验证策略之一。它可能不适合你的问题。其他的包括k-fold交叉验证和嵌套交叉验证,这是我们在HVAC开始时间建模问题上使用的。
如果适合于业务问题,我们希望对我们的训练和验证损失使用自定义函数。在某些情况下,由于自定义损失的功能形式,可能无法使用它作为训练损失。在这种情况下,只需更新验证损失并使用默认的训练损失(如MSE)就可以了。您仍然会得到好处,因为超参数将使用所需的自定义损耗进行调优。
在LightGBM中实现自定义损失函数
让我们看看实际情况,并在模拟数据上做一些实验。首先,我们假设高估比低估更糟糕。此外, 让我们假设平方损失是一个很好的误差模型为我们提供两个方向上的误差损失。为了对其进行编码,我们定义了一个自定义MSE函数,它对正残差的惩罚是负残差的10倍。下图展示了我们的自定义损失函数与标准MSE损失函数的对比。
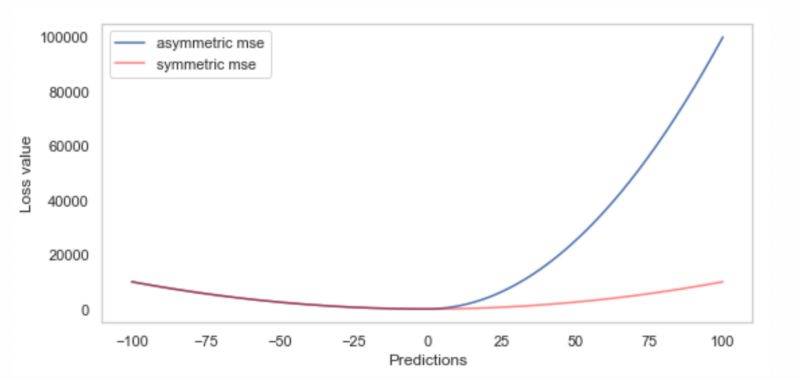
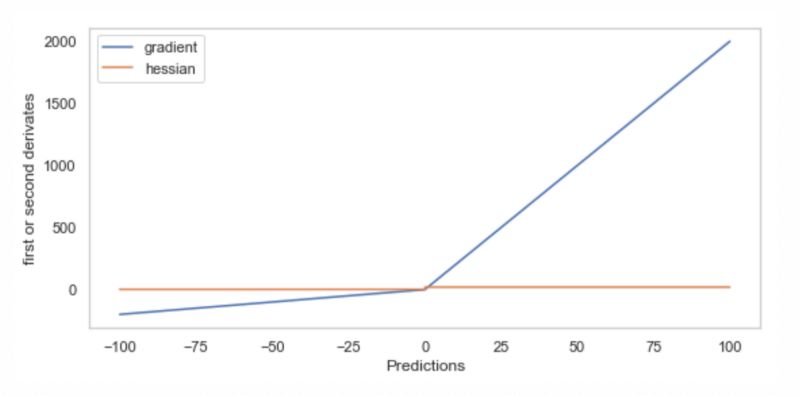
正如定义的那样,非对称MSE很好,因为它很容易计算梯度和hessian,如下图所示。注意,hessian在两个不同的值上是常量,左边是2,右边是20,尽管在下面的图中很难看到这一点。
LightGBM提供了一种直接实现定制训练和验证损失的方法。其他的梯度提升包,包括XGBoost和Catboost,也提供了这个选项。这里是一个Jupyter笔记本,展示了如何实现自定义培训和验证损失函数。细节在笔记本上,但在高层次上,实现略有不同。
1、训练损失:在LightGBM中定制训练损失需要定义一个包含两个梯度数组的函数,目标和它们的预测。反过来,该函数应该返回梯度的两个梯度和每个观测值的hessian数组。如上所述,我们需要使用微积分来派生gradient和hessian,然后在Python中实现它。
2、验证丢失:在LightGBM中定制验证丢失需要定义一个函数,该函数接受相同的两个数组,但返回三个值: 要打印的名称为metric的字符串、损失本身以及关于是否更高更好的布尔值。
用于在LightGBM中实现自定义丢失的代码
定义自定义验证和训练损失函数
在LightGBM中结合训练和验证损失(包括Python和scikit-learn API示例)
自定义损失函数的实验
Jupyter 笔记本 的代码还对默认随机森林,默认LightGBM和MSE以及LightGBM与自定义训练和验证丢失功能进行了深入比较。
我们使用Friedman 1合成数据集,进行了8,000次训练观察,2,000次验证观察和5,000次测试观察。 验证集用于找到优化验证损失的最佳超参数集。下面报告的分数在测试观察结果上进行评估,以评估我们模型的普遍性。
我们做了一系列实验,总结如下表。 请注意,我们关心的最重要的分数是非对称MSE,因为它明确定义了我们的不对称惩罚问题。

实验和结果
让我们详细比较。
随机森林→LightGBM
使用默认设置,LightGBM在此数据集上的性能优于Random Forest 随机森林。 随着让更多树木充份生长和超参数的更好组合,随机森林也可能会给出好的结果,但这不是重点。
LightGBM→LightGBM,具有定制的训练损失
这表明我们可以使我们的模型优化我们关心的内容。 默认的LightGBM正在优化MSE(均方误差),因此它可以降低MSE损失(0.24对0.33)。 具有自定义训练损失的LightGBM优化了非对称MSE,因此对于非对称MSE(1.31 vs. 0.81)表现更好。
LightGBM→LightGBM使用MSE调整提前停止轮次
两种LightGBM模型都在优化MSE。 我们看到默认的MSE分数有了很大改善,只需稍微调整一下使用提前停止轮次(MSE:0.24 vs 0.14)。 因此,我们应该让模型使用提前停止超参数来确定最佳提升次数,而不是将提升次数限制为默认值( 即 100)。 超参数优化很重要!
LightGBM使用MSE→LightGBM调整提前停止轮次,并使用自定义MSE进行早期停止调整
这两个模型的得分非常接近,没有实质性差异。 这是因为验证损失仅用于决定何时停止提升。 梯度是在两种情况下优化默认MSE。 每个后续树为两个模型生成相同的输出。 唯一的区别是具有自定义验证损失的模型在742次增强迭代时停止,而另一次运行多次。
LightGBM使用自定义MSE→LightGBM通过定制丢失进行调整,并使用MSE进行早期停止调整
仅在不改变验证损失的情况下定制训练损失会损害模型性能。 只有自定义训练损失的模型比其他情况增加了更多轮次(1848)。 如果我们仔细观察,这个模型的训练损失非常低(0.013)并且在训练集上非常过度拟合。 每个梯度增强迭代使用训练误差作为目标变量来创建新树,但仅当验证数据的损失开始增加时,增强停止。 当模型开始过度拟合时,验证损失通常开始增加,这是停止构建更多树木的信号。 在这种情况下,由于验证和培训损失彼此不一致,因此模型似乎没有“得到消息”而导致过度拟合。 这个配置只是为了完整而包含在内,并不是人们在实践中应该使用的。
LightGBM具有经过调整的提前停止轮次,MSE→LightGBM训练定制训练损失,并通过定制验证损失调整提前停止轮次
最终模型使用自定义训练和验证损失。 它通过相对较少的增强迭代次数给出最佳的非对称MSE分数。 损失与我们关心的一致!
让我们仔细看看剩余直方图以获得更多细节。
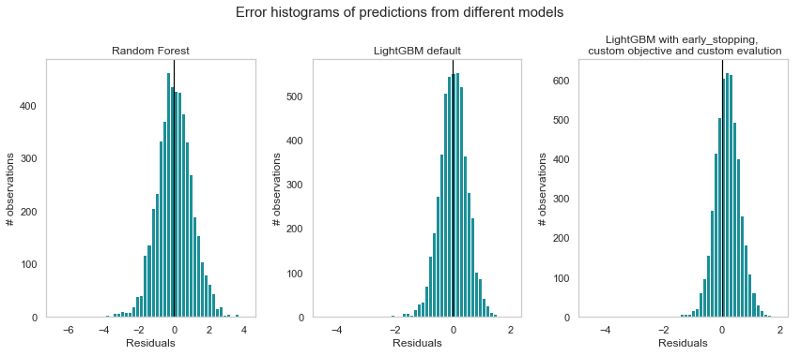
不同模型预测的残差直方图。
注意,使用LightGBM(即使有默认的超参数),与随机森林模型相比,预测性能得到了改善。带有自定义验证损失的最终模型似乎在直方图的右侧做出了更多的预测,即实际值大于预测值。这是由于非对称自定义损失函数的缘故。使用残差的核密度图可以更好地显示残差的右移。
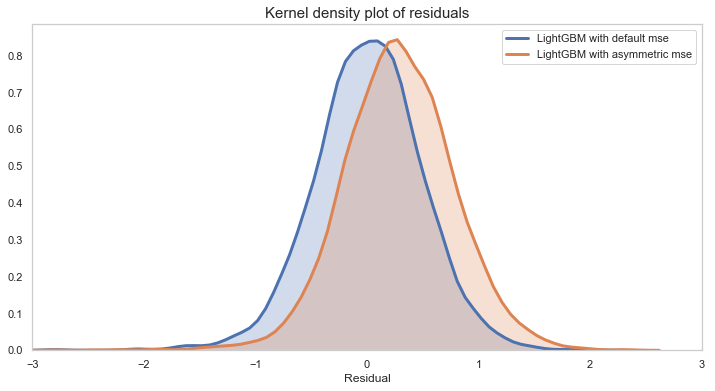
LightGBM模型与对称评价和非对称评价的比较
总结
所有的模型都有误差,但是许多业务问题并不能平等地对待低估和高估。有时,我们有意地希望我们的模型将误差偏向某个方向,这取决于哪些误差代价更高。因此,我们不应该局限于普通ML库中的“现成的”对称损失函数。
LightGBM提供了一个简单的界面来合并自定义的训练和验证丢失功能。在适当的时候,我们应该利用这个功能来做出更好的预测。同时,您不应该立即直接使用自定义损失函数。最好采用精益的、迭代的方法,首先从一个简单的基线模型开始,比如一个随机森林。在下一次迭代中,您可以采用像LightGBM这样更复杂的模型,并进行超参数优化。只有在这些基线稳定下来之后,才有必要继续定制验证和训练损失函数。
希望这有用!
推荐阅读
如果您不清楚一般梯度提升是如何工作的,我建议您阅读如何用Terence Parr解释梯度提升,以及用Prince从头开始解释梯度提升。
有很多关于如何在不同的GBM框架中优化超参数的文章。如果您想使用这些包中的一个,您可以花一些时间来了解要搜索的超参数范围。这个LightGBM GitHub问题给出了一个关于使用的值范围的粗略概念。Aarshay Jain写了一篇关于XGBoost和sklearn gradient boost的博客。我认为关于LightGBM的调优有很好的博客空间。
为了直观地了解哪种梯度提升包适合您的情况,请阅读Alvira Swalin的CatBoost vs Light GBM vs XGBoost,以及Pranjan Khandelwal的哪种算法获得冠军:Light GBM vs XGBoost ?
想要继续查看该篇文章更多代码、链接和参考文献?
戳链接:
http://www.gair.link/page/TextTranslation/1094