【CVPR2022】基于序列对比学习的长视频帧方向动作表示

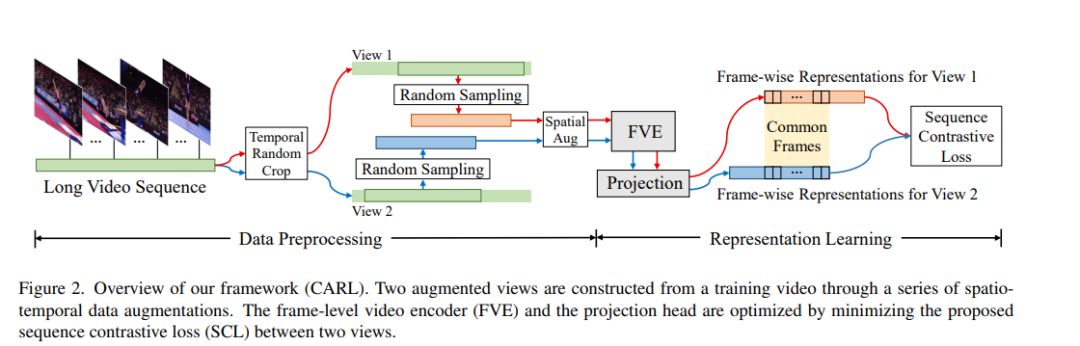
以往关于动作表示学习的研究主要集中在设计各种结构来提取短视频片段的全局表示。相比之下,许多实际应用,如视频对齐,对学习长视频的密集表示有很强的需求。在本文中,我们引入了一种新的对比动作表示学习(CARL)框架,以一种自监督的方式学习基于帧的动作表示,特别是长视频。具体地说,我们介绍了一个简单而有效的视频编码器,它考虑了时空上下文来提取帧方向表示。受自监督学习的最新进展的启发,我们提出了一种新的序列对比损失(SCL),应用于通过一系列时空数据增强获得的两个相关视图。SCL通过最小化两个增广视图的序列相似度与时间戳距离的先验高斯分布之间的KL散度来优化嵌入空间。在FineGym、PennAction和Pouring 数据集上的实验表明,我们的方法在下游细粒度动作分类方面的表现大大超过了以前的先进技术。令人惊讶的是,尽管没有对成对的视频进行训练,我们的方法在视频对齐和细粒度的帧检索任务中也表现出了出色的性能。代码和模型可以在https://github.com/minghchen/CARL_code上找到。
https://www.zhuanzhi.ai/paper/eed105f3942b2c53b026d1a1793f4be8
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VSCL” 就可以获取《【CVPR2022】基于序列对比学习的长视频帧方向动作表示》专知下载链接



登录查看更多
相关内容
专知会员服务
16+阅读 · 2022年4月11日
Arxiv
11+阅读 · 2021年12月16日



相关VIP内容
专知会员服务
16+阅读 · 2022年4月11日
相关资讯