
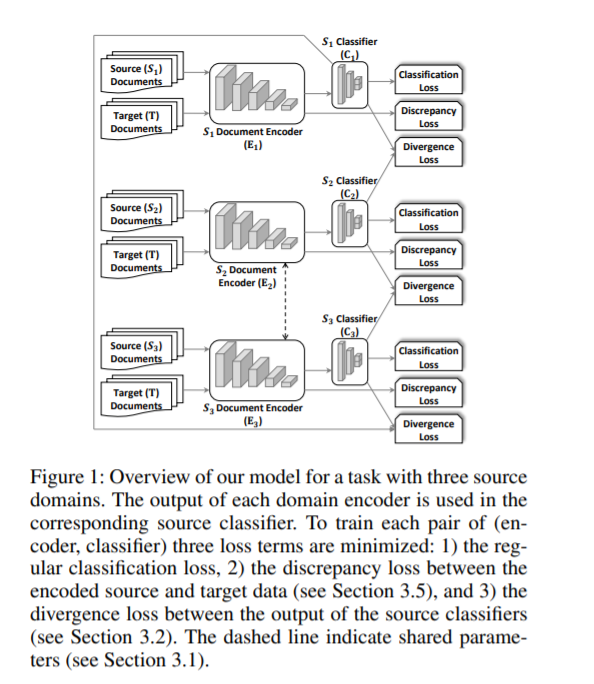
本文提出了一种新的多源无监督文本分类模型。我们的模型利用文档表示中的更新速率来动态地集成域编码器。为了对源分类器进行配对,它还采用了一种概率启发式来推断目标域中的错误率。我们的启发式利用数据转换成本和分类器的准确性在目标特征空间。我们使用领域自适应的真实场景来评估算法的有效性。在实验中,我们还使用了预训练好的多层变换器作为文档编码器,以证明领域自适应模型所取得的改进是否可以通过预训练的语言模型来实现。实验证明,我们的模型是在这种情况下性能最好的方法。
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯
相关论文