CVPR 2018 | 炫酷的卡通画目标检测

作者:Panzer
论文地址:https://arxiv.org/abs/1803.11365
源码地址:https://github.com/naoto0804/cross-domain-detection
背景介绍
近年来,通用目标检测器(如Faster R-CNN,SSD,R-FCN,Mask R-CNN)发展迅速,在有标签数据集上(Pscal VOC, COCO等)的检测性能不断提升。然而,这些检测器如果直接迁移到卡通画上进行目标检测,性能却难尽人意,这是因为Pscal VOC, COCO的真实场景图像和卡通画图像存在非常严重的域偏差(domain shift)。为了实现卡通画上的目标检测,一种可行的方式是,人工标注一定数量的卡通画图像,用于训练检测器,但势必带来巨大的人力物力资源消耗。自然我们可以想到,能否利用已有的有标签数据集(如Pscal VOC, COCO等)来达到我们的目的?本文对此做了一次有益尝试。
解决思路
在没有Bounding Box标签的情况下,如何使得检测器也能够在卡通画图像上得到比较好的目标检测性能?图1左侧子图解释了不同层面的标注形式,在源域(Pascal VOC)中既有Image-level的标签也有Instance-level的标签,在目标域中只有Image-level的标签。
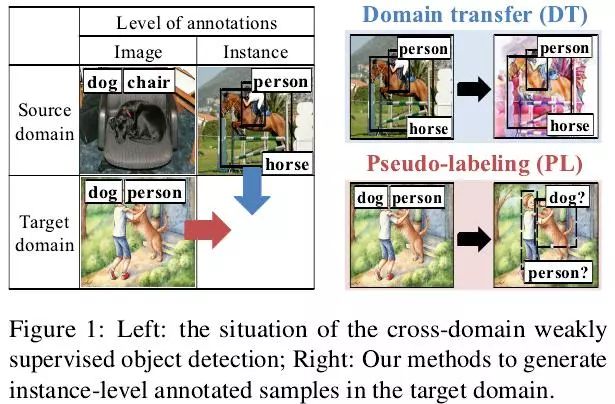
图1右侧子图给出了本文具体的处理流程,分别对应本文的两个处理策略。
策略1:Domain transfer
将Pscal VOC中的真实图像转换成卡通画风格的图像,并保留图像中的语义结构信息,例如图中的person和horse,这样转换的卡通画就有了Instance-level的标签,并用于训练检测器。这里作者采用的是Cycle-GAN [1]进行图像之间的转换,原始Cycle-GAN在不同图像转换任务上都取得了非常惊艳的效果。本文的实验证明Cycle-GAN在真实图像和卡通画图像之间的转换也非常成功,不仅在视觉效果上保留了图像中的语义结构信息,而且也带来了检测器的极大提升。
策略2:Pseudo-labeling
用策略1训练好的检测器给真实卡通画图像打上伪标签,进一步用真实卡通画图像去微调网络,最终得到一个在卡通画图像上表现优异的检测器。由于每张图像有Image-level的标签,所以取每张图像中对应类别得分最高的Bounding Box作为Instance-level的标签,这里基于这样一个强假设,也即每张图像上一个类别只有一个目标。值得一提的是,本文还公开了一个卡通画图像检测的数据集,通过数据集的大小(表1)可以发现这一假设在这个任务上是成立的。
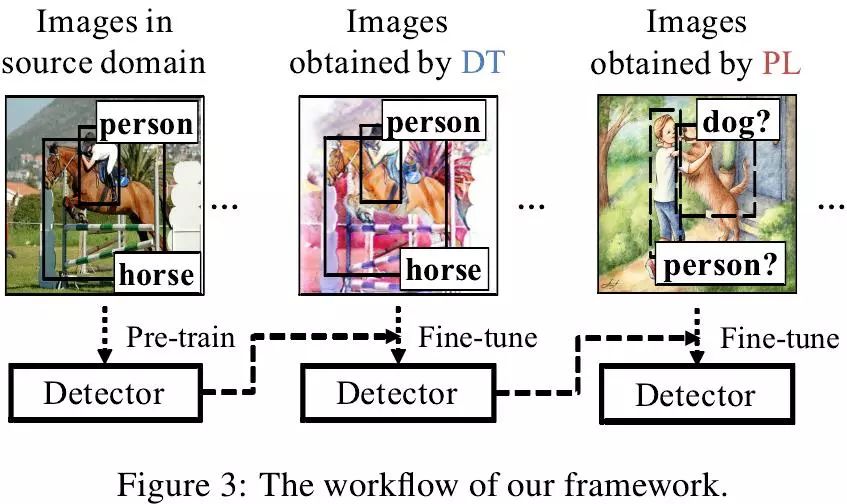
对应以上两种策略,图2给出了本文算法的训练过程,共分为三步:首先在Pascal VOC上预训练,其次在策略1得到的图像上进行微调,最后在策略2得到的图像上进行微调。
实验分析
1、性能分析
实验采用的检测器是SSD300,作者是在Chainer这个框架下实现的,并公开了源码。此外作者还和两种弱监督的目标检测方法以及一种域适应方法进行实验对比。对比结果如下图所示:
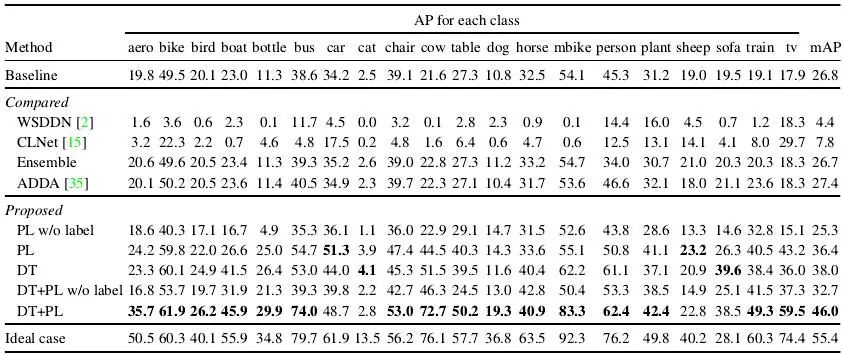
其中Ideal case代表利用卡通图像的有标签数据进行有监督训练的,mAP为55.4,可以本文方法取得了最接近有监督训练的结果(46.0),并且要远远优于两种弱监督以及域适应的方法。Baseline代表在Pascal VOC上训练的检测器,mAP只有26.8,通过本文算法的两种策略,将这一性能提升了近20个点。
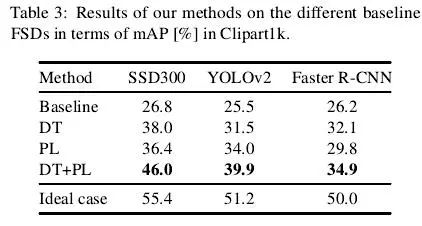
2、对不同检测器的鲁棒性
为了验证本文提出的两种策略的通用性,作者又在三个具有代表性的检测器(SSD,YOLO,Faster R-CNN)上做了实验,如下表所示。从表3可以发现,本文方法的优势在不同检测器上都有体现。其中有两点值得注意:(1)DT和PL对Baseline的提升旗鼓相当,说明这两种策略具有互补性且均非常必要;(2)Faser R-CNN的表现明显低于SSD,这和通用目标检测领域的结果是不符合的。为什么?笔者认为可能的一个原因是:SSD中采用了大量的图像数据增强技术,这些数据增强技术在Faser R-CNN的训练过程中是没有的,而本文的卡通图数据集的数据规模要比Pascal VOC低一个数量级(见表1)。从表3的Baseline(Pascal VOC数据训练)和Ideal case(卡通图数据训练)的对比中我们也可以发现:在Baseline上三种检测器的性能是不相上下的,较大的差距却出现在了Ideal case上。
总结展望
本文贡献:
(1)公开了一个卡通图检测数据集,并提出了目标检测的一个域适应问题:在Instance-level标签缺乏的情况下,如何实现通用检测器在卡通图上的目标检测;
(2)提出了两个策略(图像层面的域适应策略和弱监督伪标签策略),用于解决该问题。
个人见解:
(1)本文充分验证了Cycle-GAN的强大,在真实图像和卡通图像这两个风格差距巨大的domain中,也能完成成功的图像转换。在CVPR2018还有很多工作同样是采用了Cycle-GAN进行图像风格之间的转换,如这篇[2]将其用于Re-ID,用于解决Camera之间风格不同的问题。
(2)检测器的训练对数据的依赖非常严重,在数据有限的情况下,数据增强是很有必要的一种策略,我们对表3的分析可以得出这一结论。
(3)目标检测领域的域适应是一个非常有价值的问题,近年来逐渐得到学术界的关注,如同样发表于CVPR2018的这篇[3]便提出了真实场景中的目标检测域适应问题,极市已有技术文章对[3]进行解读。不可否认的是,对域适应问题的解决是目标检测迈向现实场景的重要一步。
参考文献
[1] Adversarial Discriminative Domain Adaptation. CVPR (2017)
[2] Camera Style Adaptation for Person Re-identification. CVPR (2018)
[3] Domain Adaptive Faster R-CNN for Object Detection in the Wild. CVPR (2018)
注:[3]已有论文解读发表于极市技术博客:
CVPR 2018 | ETH Zurich提出利用对抗策略,解决目标检测的域适配问题
END
—本文为极市原创,欢迎大家投稿,转载请后台留言—
*推荐文章*
10行代码实现目标检测,请收下这份教程
深度学习目标检测指南:如何过滤不感兴趣的分类及添加新分类?
PS.极市平台诚招计算机视觉算法工程师啦~工作要求请关注“极市平台”公众号(id:extrememart),点击菜单加入极市“诚招”栏或直接私信小助手(微信:Extreme-Vision),欢迎大牛来戳~



