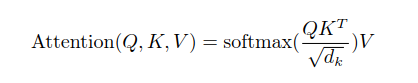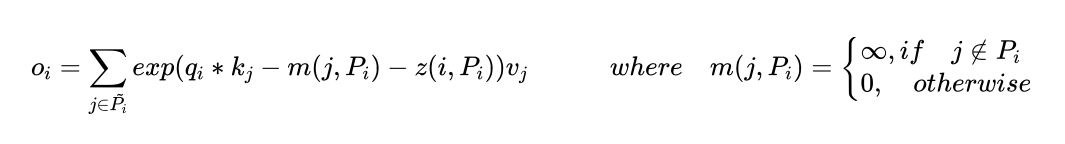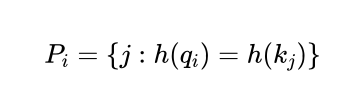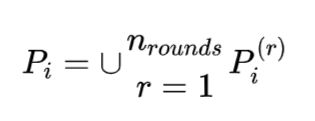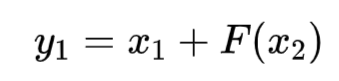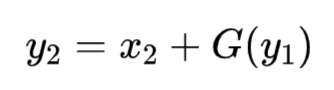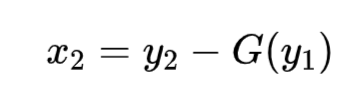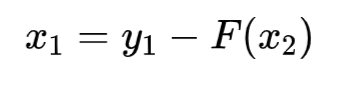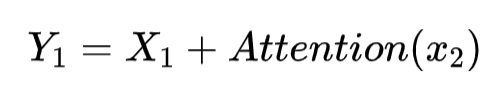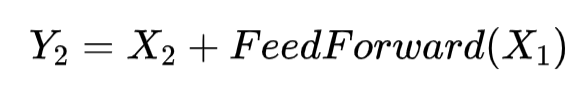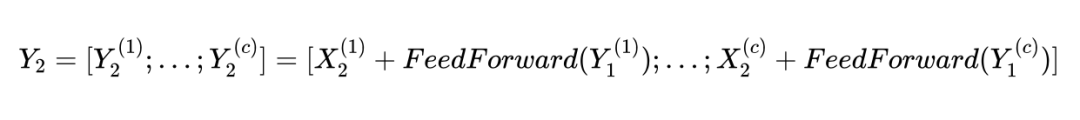![]()
本文介绍的是ICLR2020入选 Oral 论文《Reformer: The Efficient Transformer》,作者来自UC 伯克利和谷歌大脑。
作者 | 李光明
编辑 | 丛 末
![]()
论文地址:https://openreview.net/pdf?id=rkgNKkHtvB
Transformer是NLP中广为应用的成熟技术,在许多任务中取得了骄人的成绩,尤其是长序列文本上表现突出,但却极其耗费算力和内存资源,Transformer网络一层的参数量约0.5B,需要2G的内存空间,单层网络的Transformer在单台机器上尚可满足,但鉴于以下考虑,整个Transformer网络所需要的资源是惊人的:
-
一个N层的网络需要的内存资源要多于一层所需内存的N倍,因为同时需要存储激活结果,在反向传播时使用。
-
Transformer前馈全连接神经网络的宽度(神经单元数)要比attention激活的宽度(可理解为embedding的size)多,需要更多的内存消耗。
-
对一个长度为L的序列,Attention层的复杂度是,这对长序列文本处理是无法接受的。
针对上述问题,这篇文章通过下面几项技术解决上面提到的几个问题:
-
使用可逆残差层取代标准残差层,在训练阶段只需要存储一层的激活结果而不是N层(N是网络层数)(消除了网络中N的倍数)。
-
分离前馈全连接层的激活部分,分区块进行处理,消除对内存的消耗。
-
使用局部敏感哈希(Local-Sensitive Hashing, LSH)技术把计算attention部分的复杂度(主要来自于点乘)从降至(其中L代表序列长度)。
Transformer的注意力计算公式(encoder和decoder相同)如下:
不妨假设Q, K, V的 shape 都是[
,
,
],计算复杂度主要来源于
,其 shape为[
,
,
],处理64k长度的序列时,即使
为1,一个64k * 64k的 float矩阵需要16G内存,这通常是不切实际的。
其实,
矩阵并不需要全部存储在内存中,只需要计算每个query
的
进一步分析,其实并不需要计算
和全部keys的结果,因为点乘的最大值会在softmax之后得到最大的权重,从而在attention的结果中影响最大,因此只需要关心与
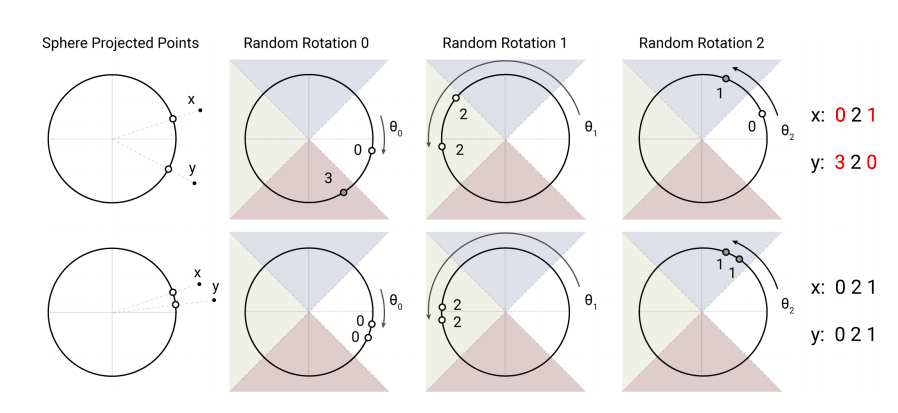
相近的key即可(得到较大的点乘值),这样可以大幅提升效率。LSH是寻找最近邻的有效手段,它会赋予每个向量一个Hash值,并且相近的向量会大概率获得相同的Hash值,相距较远的向量则不同。
![]()
上图是LSH的一个简单示意图,在示意图的上部分,x和y不属于近邻,所以在三次随意旋转后,有两次投影都不一样;而在示意图的下部分,x和y相距很近,在三次的随意旋转后,三次都投影都一样,这就是LSH的基本原理。
为计算LSH attention,首先重写
的一次attention计算如下:
其中
表示
需要关注的key集合,
是分区函数(可以理解成softmax的分母),为了书写方便,这里省去了
。为了批处理方便,把公式进一步修改为:
![]()
其中
是比
更大的集合(可以理解成全集),从公式可以看出,如果不属于
的
都被置为正无穷(
趋近于0),相当于对应的 key 被 mask 掉了。LSH 的作用就是生成
,仅限与
在同一个 Hash 桶中的 key 才会参与 attention 计算,满足:
![]()
下图的
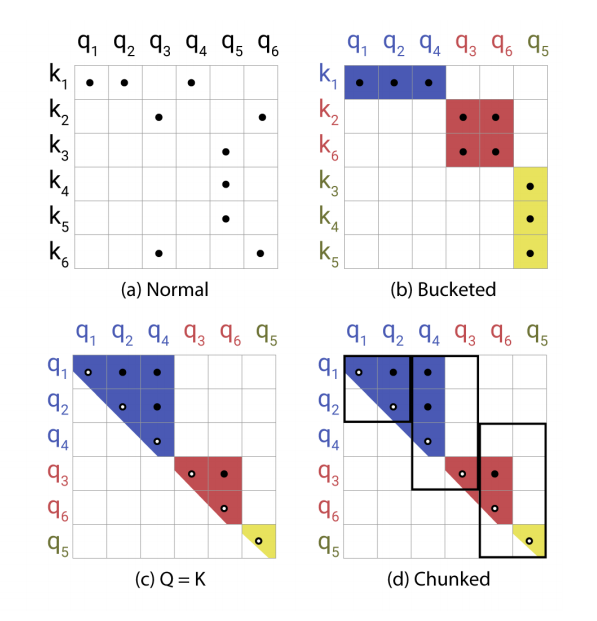
分别表示传统的系数attention矩阵,以及根据Hash分桶排序后的attention矩阵,从图中可以看出Hash值分桶可能发生不均匀的情况(跨多个桶的批处理是比较困难的),而且一个桶内的queries和keys数量也不一定相等,甚至有可能存在桶中只有queries而没有keys的情况。
为了解决这个问题,首先通过
确保
。接下来根据桶号和桶内序列位置对 queries 进行双层排序,排序后可以得到一个新的排序
,排序后的 attention 矩阵,同一个桶的将聚集在对角线附近,如下图c所示(Q=K,文中的设定,实验阶段会验证此设定不会造成太大影响),接下来可以定义一种批处理方法,使得排序后的 m 个连续的块相互关联,如下图d所示,关联规则是后面的块只需要往前看一个块,并对
设置如下:
其中
(认为桶的长度超过平均桶长度两倍的概率很小)
![]()
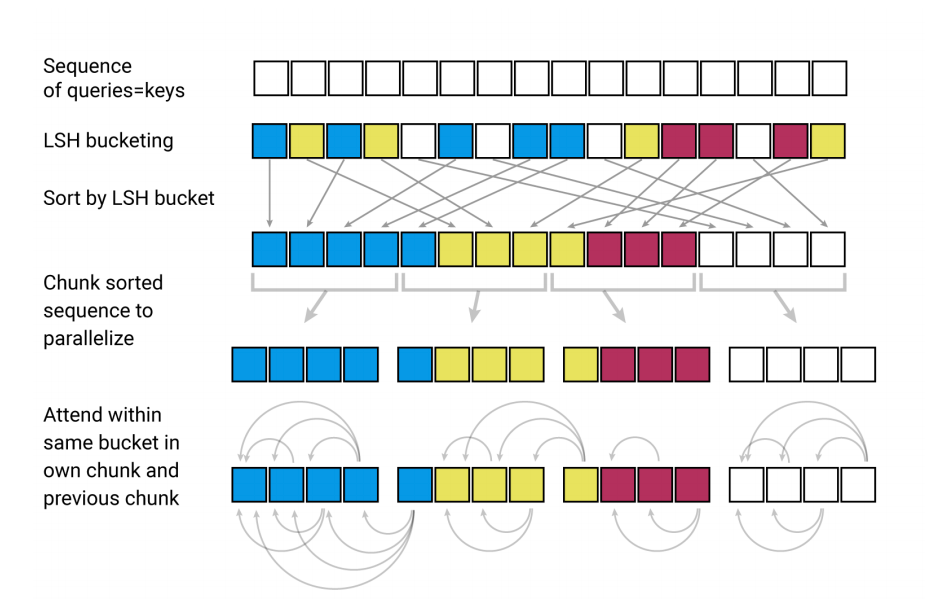
LSH attention的整个处理流程如下图所示:
![]()
单个Hash函数仍然存在较小概率导致相似的item不能分到相同的桶里,可以通过多轮Hash函数避免这个问题,多轮Hash使用不同的Hash函数
,有:
![]()
![]()
可逆残差网络的思路是在反向传播梯度时,仅依赖模型参数,就可以利用后续网络层恢复任何给定层的激活结果,从而节省内存空间。标准的残差层是从一个输入
到一个输出
的映射
,而可逆层的输入输出都是成对的:
,计算公式如下:
![]()
![]()
逆向过程通过减残差实现:
![]()
![]()
将可逆残差网络的思想应用到 Transformer 中,充分结合 Attention 层和 Feed-Forward 层,上式中的
变成 Attention 层,
变成 Feed-Forward 层,于是有:
![]()
![]()
Transformer 前馈网络的中间向量维度
甚至更高维度,依然非常占用内存;其实,序列中不同位置的文本可以完全独立计算,因此可以拆分成多个区块并行计算:
![]()
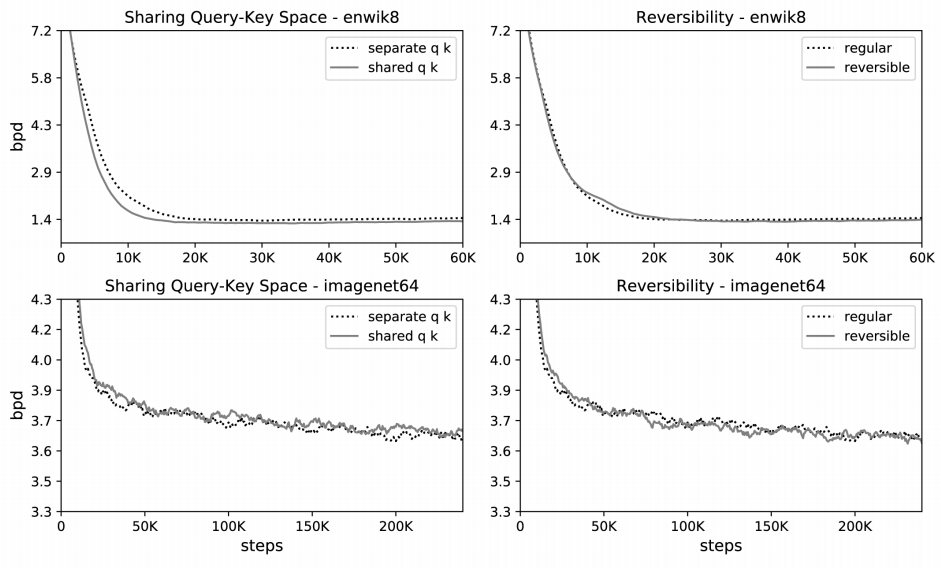
实验阶段会使用 imagenet64 和 enwik8-64K 两个数据集,依次验证可逆层和共享 Q-K(Q = K)不会对模型效果造成影响,进而分析验证 Hash Attention 和整个 Reformer 架构的结果。下图的困惑度曲线(信息论中衡量概率分布预测的指标,此处用来评价模型好坏)展示了共享 Q-K 对比独立的 Q-K (左)和可逆层(右)对比正常残差层在两个数据集上的效果,从图中可知共享 Q-K 和可逆层的使用并没有导致模型准度的降低。
![]()
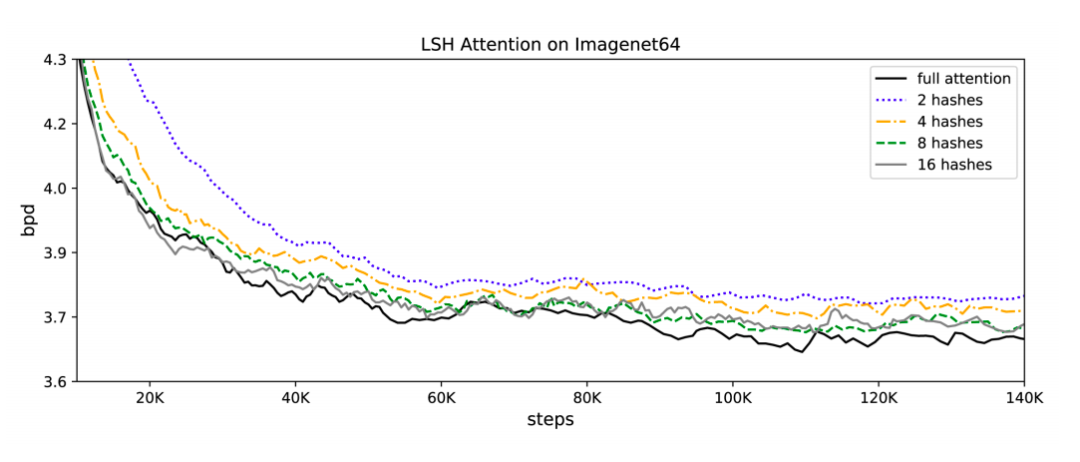
下图展示了LSH Attention的效果,随着hash函数量的增加,LSH Attention的精度损失随之减少,当hash函数量达到8个时,基本与full attention的效果持平。
![]()
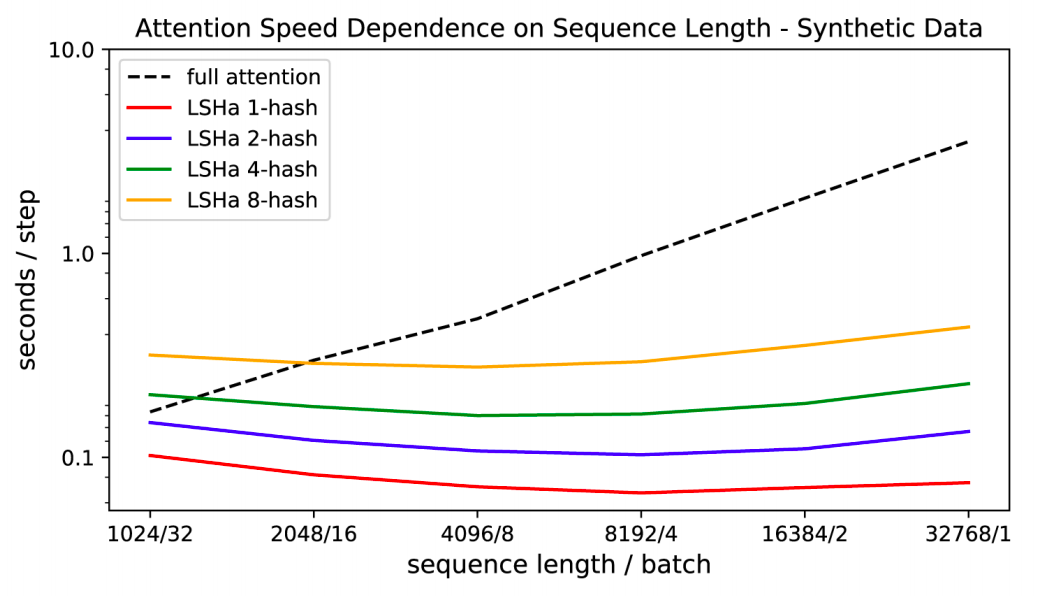
上图同时说明了hash函数量(可视为一个超参数)会影响Reformer整体效果,同样也会影响Reformer的性能,下图展示了hash函数量对性能的影响:
![]()
随着序列长度的不断增加,full attention模型变得越来越慢,而Reformer基本变化不大,提速效果非常明显。
疫情严重,ICLR2020 将举办虚拟会议,非洲首次 AI 国际顶会就此泡汤
疫情影响,ICLR 突然改为线上模式,2020年将成为顶会变革之年吗?
1、直播
回放 | 华为诺亚方舟ICLR满分论文:基于强化学习的因果发现
05. Spotlight | 华盛顿大学:图像分类中对可实现攻击的防御(视频解读)
06. Spotlight | 超越传统,基于图神经网络的归纳矩阵补全
4、Poster