一文概览深度学习中的激活函数
来源:机器之心(ID:almosthuman2014)编译自Learn OpenCV
参与:路雪、蒋思源
本文从激活函数的背景知识开始介绍,重点讲解了不同类型的非线性激活函数:Sigmoid、Tanh、ReLU、LReLU、PReLU、Swish,并详细介绍了这些函数的优缺点。
本文介绍了多种激活函数,并且对比了激活函数的优劣。本文假设你对人工神经网络(AAN)有基本了解:
1. 什么是激活函数?
生物神经网络启发了人工神经网络的发展。但是,ANN 并非大脑运作的近似表示。不过在我们了解为什么在人工神经网络中使用激活函数之前,先了解生物神经网络与激活函数的相关性是很有用处的。
典型神经元的物理结构包括细胞体(cell body)、向其他神经元发送信号的轴突(axon)和接收其他神经元发送的信号或信息的树突(dendrites)。
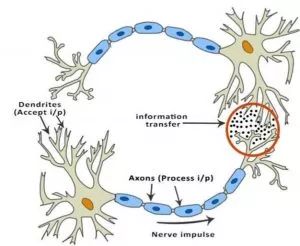
生物神经网络
上图中,红色圆圈代表两个神经元交流的区域。神经元通过树突接收来自其他神经元的信号。树突的权重叫作突触权值(synaptic weight),将和接收的信号相乘。来自树突的信号在细胞体内不断累积,如果信号强度超过特定阈值,则神经元向轴突传递信息。如未超过,则信号被该神经元「杀死」,无法进一步传播。
激活函数决定是否传递信号。在这种情况下,只需要带有一个参数(阈值)的简单阶梯函数。现在,当我们学习了一些新的东西(或未学习到什么)时,一些神经元的阈值和突触权值会发生改变。这使得神经元之间产生新的连接,大脑学会新的东西。
让我们再次理解这一概念,不过这次要使用人工神经元。
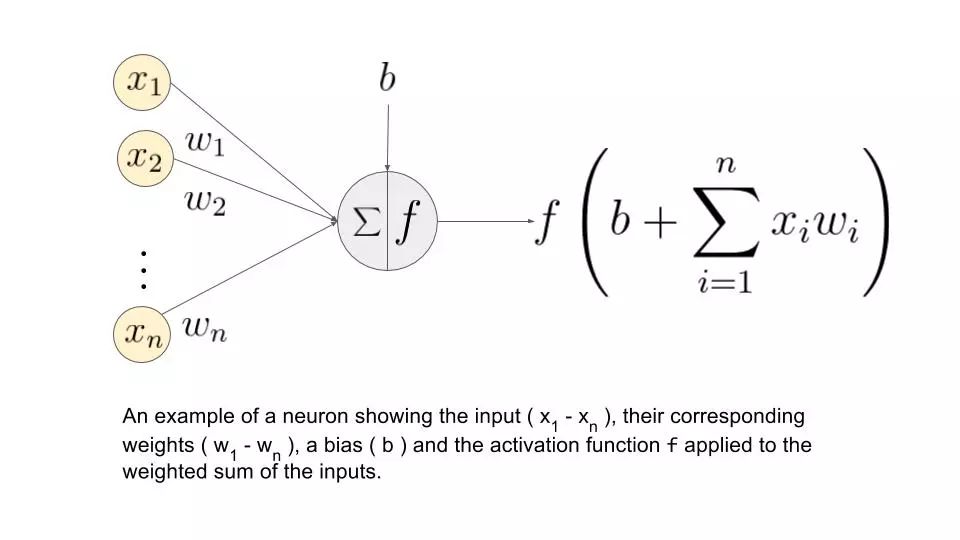
上图中(x_1, ..., x_n)是信号向量,它和权重(w_1, ..., w_n)相乘。然后再累加(即求和 + 偏置项 b)。最后,激活函数 f 应用于累加的总和。
注意:权重(w_1, ..., w_n)和偏置项 b 对输入信号进行线性变换。而激活函数对该信号进行非线性变换,这使得我们可以任意学习输入和输出之间的复杂变换。
过去已经出现了很多种函数,但是寻找使神经网络更好更快学习的激活函数仍然是活跃的研究方向。
2. 神经网络如何学习?
我们有必要对神经网络如何学习有一个基本了解。假设网络的期望输出是 y(标注值),但网络实际输出的是 y'(预测值)。预测输出和期望输出之间的差距(y - y')可以转化成一种度量,即损失函数(J)。神经网络犯大量错误时,损失很高;神经网络犯错较少时,损失较低。训练目标就是找到使训练集上的损失函数最小化的权重矩阵和偏置向量。
在下图中,损失函数的形状像一个碗。在训练过程的任一点上,损失函数关于梯度的偏导数是那个位置的梯度。沿偏导数预测的方向移动,就可以到达谷底,使损失函数最小化。使用函数的偏导数迭代地寻找局部极小值的方法叫作梯度下降。
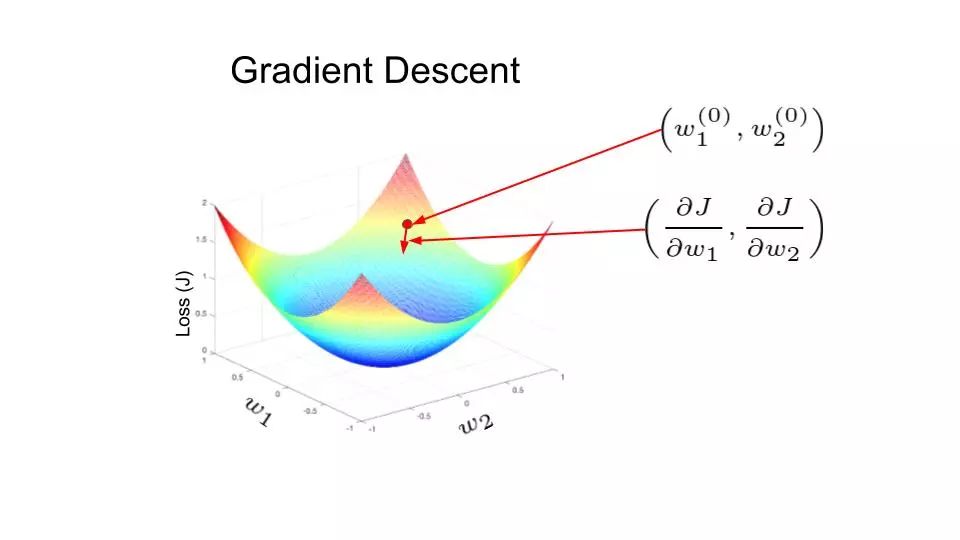
人工神经网络中的权重使用反向传播的方法进行更新。损失函数关于梯度的偏导数也用于更新权重。从某种意义上来说,神经网络中的误差根据求导的链式法则执行反向传播。这通过迭代的方式来实施,经过多次迭代后,损失函数达到极小值,其导数变为 0。
我们计划在其他文章中介绍反向传播。这里主要指出的就是训练过程中出现的求导步骤。
3. 激活函数的类型
线性激活函数:这是一种简单的线性函数,公式为:f(x) = x。基本上,输入到输出过程中不经过修改。
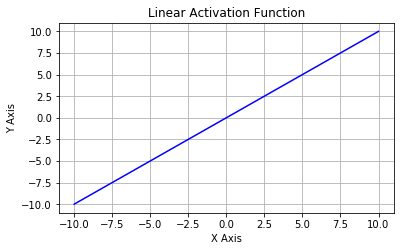
线性激活函数
非线性激活函数:用于分离非线性可分的数据,是最常用的激活函数。非线性方程控制输入到输出的映射。非线性激活函数有 Sigmoid、Tanh、ReLU、LReLU、PReLU、Swish 等。下文中将详细介绍这些激活函数。
非线性激活函数
4. 为什么人工神经网络需要非线性激活函数?
神经网络用于实现复杂的函数,非线性激活函数可以使神经网络随意逼近复杂函数。没有激活函数带来的非线性,多层神经网络和单层无异。
现在我们来看一个简单的例子,帮助我们了解为什么没有非线性,神经网络甚至无法逼近异或门(XOR gate)、同或门(XNOR gate)等简单函数。下图是一个异或门函数。叉和圈代表了数据集的两个类别。当 x_1、x_2 两个特征一样时,类别标签是红叉;不一样,就是蓝圈。两个红叉对于输入值 (0,0) 和 (1,1) 都有输出值 0,两个蓝圈对于输入值 (0,1) 和 (1,0) 都有输出值 1。
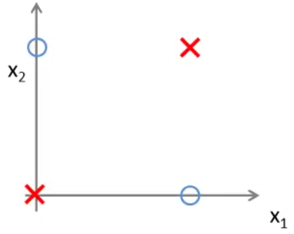
异或门函数的图示
从上图中,我们可以看到数据点非线性可分。也就是说,我们无法画出一条直线使蓝圈和红叉分开来。因此,我们需要一个非线性决策边界(non-linear decision boundary)来分离它们。
激活函数对于将神经网络的输出压缩进特定边界内也非常关键。神经元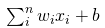
了解这些背景知识之后,我们就可以了解不同类型的激活函数了。
5. 不同类型的非线性激活函数
5.1 Sigmoid
Sigmoid又叫作 Logistic 激活函数,它将实数值压缩进 0 到 1 的区间内,还可以在预测概率的输出层中使用。该函数将大的负数转换成 0,将大的正数转换成 1。数学公式为:
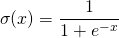
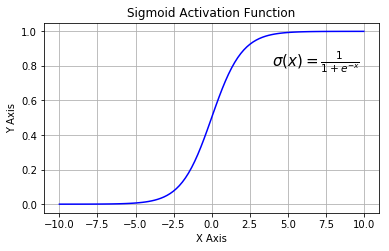
下图展示了 Sigmoid 函数及其导数:
Sigmoid 激活函数
Sigmoid 导数
Sigmoid 函数的三个主要缺陷:
1. 梯度消失:注意:Sigmoid 函数趋近 0 和 1 的时候变化率会变得平坦,也就是说,Sigmoid 的梯度趋近于 0。神经网络使用 Sigmoid 激活函数进行反向传播时,输出接近 0 或 1 的神经元其梯度趋近于 0。这些神经元叫作饱和神经元。因此,这些神经元的权重不会更新。此外,与此类神经元相连的神经元的权重也更新得很慢。该问题叫作梯度消失。因此,想象一下,如果一个大型神经网络包含 Sigmoid 神经元,而其中很多个都处于饱和状态,那么该网络无法执行反向传播。
2. 不以零为中心:Sigmoid 输出不以零为中心的。
3. 计算成本高昂:exp() 函数与其他非线性激活函数相比,计算成本高昂。
下一个要讨论的非线性激活函数解决了 Sigmoid 函数中值域期望不为 0 的问题。
5.2 Tanh
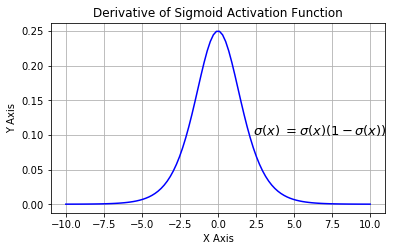
Tanh 激活函数
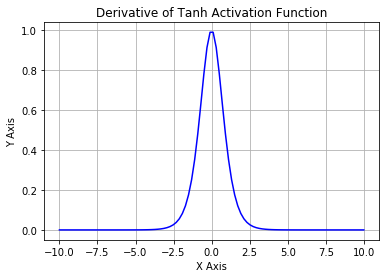
Tanh 导数
Tanh 激活函数又叫作双曲正切激活函数(hyperbolic tangent activation function)。与 Sigmoid 函数类似,Tanh 函数也使用真值,但 Tanh 函数将其压缩至-1 到 1 的区间内。与 Sigmoid 不同,Tanh 函数的输出以零为中心,因为区间在-1 到 1 之间。你可以将 Tanh 函数想象成两个 Sigmoid 函数放在一起。在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值。唯一的缺点是:
1. Tanh 函数也会有梯度消失的问题,因此在饱和时也会「杀死」梯度。
为了解决梯度消失问题,我们来讨论另一个非线性激活函数——修正线性单元(rectified linear unit,ReLU),该函数明显优于前面两个函数,是现在使用最广泛的函数。
5.3 修正线性单元(ReLU)
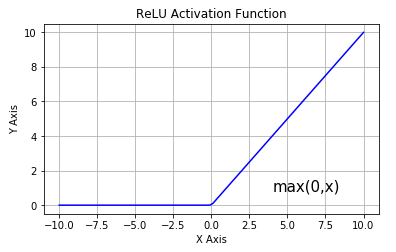
ReLU 激活函数
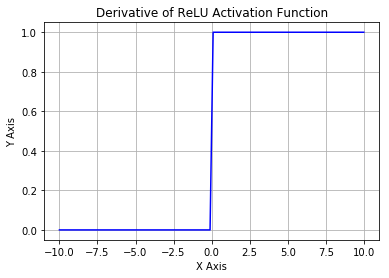
ReLU 导数
从上图可以看到,ReLU 是从底部开始半修正的一种函数。数学公式为:
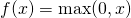
当输入 x<0 时,输出为 0,当 x> 0 时,输出为 x。该激活函数使网络更快速地收敛。它不会饱和,即它可以对抗梯度消失问题,至少在正区域(x> 0 时)可以这样,因此神经元至少在一半区域中不会把所有零进行反向传播。由于使用了简单的阈值化(thresholding),ReLU 计算效率很高。但是 ReLU 神经元也存在一些缺点:
1. 不以零为中心:和 Sigmoid 激活函数类似,ReLU 函数的输出不以零为中心。
2. 前向传导(forward pass)过程中,如果 x < 0,则神经元保持非激活状态,且在后向传导(backward pass)中「杀死」梯度。这样权重无法得到更新,网络无法学习。当 x = 0 时,该点的梯度未定义,但是这个问题在实现中得到了解决,通过采用左侧或右侧的梯度的方式。
为了解决 ReLU 激活函数中的梯度消失问题,当 x < 0 时,我们使用 Leaky ReLU——该函数试图修复 dead ReLU 问题。下面我们就来详细了解 Leaky ReLU。
5.4 Leaky ReLU
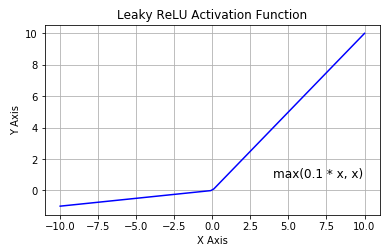
Leaky ReLU 激活函数
该函数试图缓解 dead ReLU 问题。数学公式为:
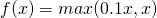
Leaky ReLU 的概念是:当 x < 0 时,它得到 0.1 的正梯度。该函数一定程度上缓解了 dead ReLU 问题,但是使用该函数的结果并不连贯。尽管它具备 ReLU 激活函数的所有特征,如计算高效、快速收敛、在正区域内不会饱和。
Leaky ReLU 可以得到更多扩展。不让 x 乘常数项,而是让 x 乘超参数,这看起来比 Leaky ReLU 效果要好。该扩展就是 Parametric ReLU。
5.5 Parametric ReLU
PReLU 函数的数学公式为:
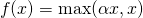
其中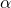
总之,最好使用 ReLU,但是你可以使用 Leaky ReLU 或 Parametric ReLU 实验一下,看看它们是否更适合你的问题。
5.6 Swish
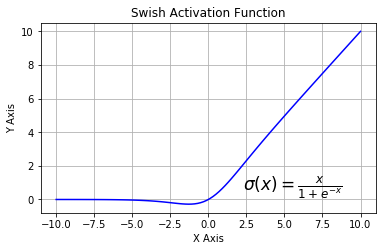
Swish 激活函数
该函数又叫作自门控激活函数,它近期由谷歌的研究者发布,数学公式为:
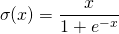
根据论文(https://arxiv.org/abs/1710.05941v1),Swish 激活函数的性能优于 ReLU 函数。
根据上图,我们可以观察到在 x 轴的负区域曲线的形状与 ReLU 激活函数不同,因此,Swish 激活函数的输出可能下降,即使在输入值增大的情况下。大多数激活函数是单调的,即输入值增大的情况下,输出值不可能下降。而 Swish 函数为 0 时具备单侧有界(one-sided boundedness)的特性,它是平滑、非单调的。更改一行代码再来查看它的性能,似乎也挺有意思。

原文链接:https://www.learnopencv.com/understanding-activation-functions-in-deep-learning/
本文为机器之心编译,转载请联系出处。
✄--------------------------------

限时干货下载
Step 1:长按下方二维码,添加微信公众号“数据玩家「fbigdata」”
Step 2:回复【2】免费获取完整数据分析资料「包括SPSS\SAS\SQL\EXCEL\Project!」




