业界 | 百度人机交互新研究:仅用少量样本生成高质量多说话者语音
选自Baidu Research
机器之心编译
参与:刘晓坤、许迪
语音复制(voice cloning)是个性化语音接口的非常急需的功能。在此论文中,百度介绍了一种能以少量音频样本作为输入的神经语音复制系统。
在百度研究院,我们的目标是用最新的人工智能技术革新人机交互界面。我们的 Deep Voice 项目在一年前启动,致力于教会机器从文本生成更加类人的语音。
通过超越单个说话者语音合成的局限,我们证明了单个系统可以学习生成几千个说话者身份,每个说话者只需要少于半小时的训练数据。我们通过在说话者之间学习共享的和区分的信息获得了这种性能。
我们希望走得更远,并尝试从仅仅少量的话语(即,仅有数秒持续时间的句子)中学习说话者特征。这个问题通常称为「语音复制」(voice cloning)。语音复制有望在人机交互界面的个性化方向中得到重要的应用。
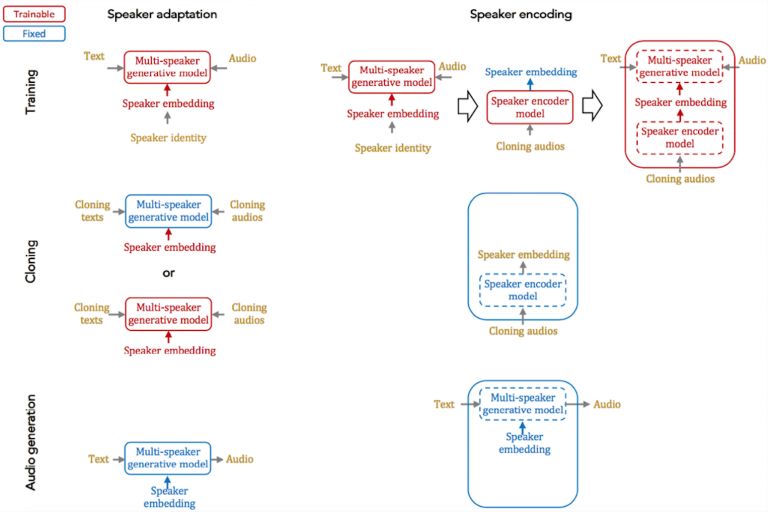
在这项研究中,我们聚焦于两种基本的方法,以解决语音复制的问题:说话者适应(speaker adaptation)和说话者编码(speaker encoding),这两种技术都可以通过说话者嵌入向量应用于一个多说话者生成语音模型,而不会降低语音质量。关于语音的自然性以及它和原始说话者的相似性,这两种方法都可以获得很好的性能,即使只有少量的复制音频。
复制语音样本的地址:https://audiodemos.github.io./
说话者适应基于用少量复制样本微调一个多说话者生成模型,使用基于反向传播的优化方法。适应机制可以应用于整个模型,或仅应用于低维说话者嵌入向量。后者可以用非常少的参数数量表示每个说话者,尽管它需要更长的复制时间,且音频质量也更低。
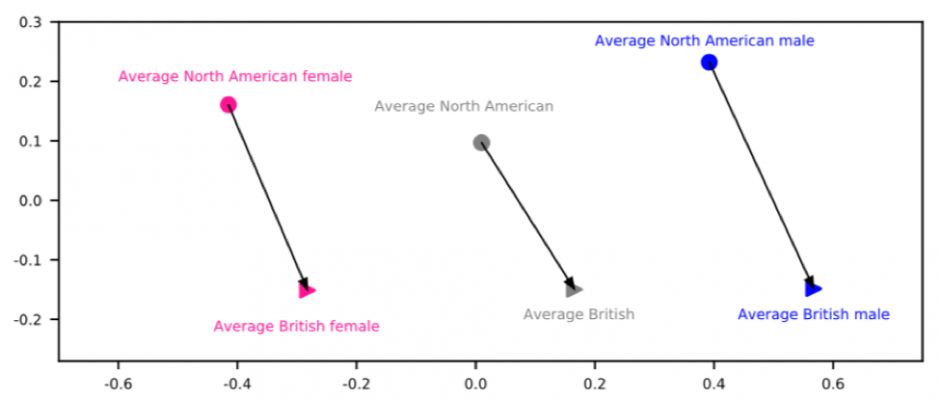
说话者编码基于训练一个独立的模型以直接从复制音频中推理出一个新的说话者嵌入向量,然后应用于多说话者生成模型。说话者编码模型有一个时域和频域处理模块以从每个音频样本中恢复说话者的身份信息,还有一个注意力模块以将它们以最优的方式进行组合。说话者编码的优势包括快速的复制时间(只需要数秒)以及只需要少量的参数数量表示每个说话者,使其更适用于资源稀缺部署的场景。除了准确得评估说话者嵌入之外,我们还观察到说话者编码器可以用有意义的方式将不同的说话者映射到嵌入空间中。例如,将来自不同区域口音或不同性别的说话者聚集到一起,这是通过在学习到的隐空间中转换说话者的性别或口音而得到的。我们的结果(见复制语音样本的地址)表明,这种方法在为说话者生成语音和变换说话者特征时非常有效。
关于语音复制的更多细节,请参见论文。
论文:Neural Voice Cloning with a Few Samples

论文链接:https://arxiv.org/pdf/1802.06006.pdf
摘要:语音复制(voice cloning)是个性化语音接口的非常急需的功能。基于神经网络的语音合成已被证明可以为大量的说话者生成高质量的语音。在本文中,我们引入了一种神经语音复制系统,其以少量音频样本作为输入。我们研究了两种方法:说话者适应(speaker adaptation)和说话者编码(speaker encoding)。说话者适应基于用少量复制样本微调一个多说话者生成模型。说话者编码基于训练一个独立模型以直接从复制音频中推理出一个新的说话者,然后应用于多说话者生成模型。关于语音的自然性以及它和原始说话者的相似性,这两种方法都可以获得很好的性能,即使只有少量的复制音频。虽然说话者适应方法可以达到更好的自然性和相似性,但是说话者编码方法的复制时间和内存占用显著更少,使其更适用于资源稀缺部署的场景。

原文链接:http://research.baidu.com/neural-voice-cloning-samples/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





