CVPR 2018 | 腾讯优图提出SRN-DeblurNet:高效高质量去除复杂图像模糊
选自arXiv
作者:Xin Tao、Hongyun Gao、Xiaoyong Shen、Jue Wang、Jiaya Jia
机器之心编译
参与:Panda
因为手抖或焦点选择等问题,相机拍摄的图像中常常存在模糊状况。消除图像模糊,呈现图像细节是计算机视觉领域内的一个重要研究主题。香港中文大学、腾讯优图实验室和旷视科技的研究者合作提出的 SRN-DeblurNet 能更高效地实现比之前最佳方法更好的结果。该论文已被将在当地时间 6 月 18-22 日于美国犹他州盐湖城举办的 CVPR 2018 接收。
图像去模糊一直以来都是计算机视觉和图像处理领域内的一个重要问题。给定一张因运动或失焦而模糊(由相机摇晃、目标快速移动或对焦不准而造成)的图像,去模糊的目的是将其恢复成有清晰的边缘结构和丰富真实的细节的图像。
单图像去模糊在数学上是一个高度病态(ill-posed)问题。传统方法是通过对模糊的原理进行简化和建模(比如均匀模糊/非均匀模糊/考虑深度的模糊),并使用不同的自然图像先验 [1, 3, 6, 14, 26, 37, 38] 来约束解空间。这些方法大多数都涉及到大量的(有时是试验式的)参数调整和成本高昂的计算。此外,简化后的模糊模型往往有碍它们在真实拍摄样本上的表现。在真实世界中,模糊比建模的情况要复杂很多,甚至还涉及到相机内部的图像处理过程。
也有研究者为去模糊提出了基于学习的方法。早期的方法 [28, 32, 35] 是借助外部训练数据,用一组可学习的参数替代传统框架中的一些模块或步骤。更近期的工作则开始使用端到端的可训练网络来进行图像 [25] 和视频 [18,31] 去模糊。其中,Nah et al.[25] 使用一种多尺度卷积神经网络(CNN)达到了当前最佳水平。他们的方法从非常小尺度的模糊图像开始,然后逐渐恢复更高分辨率的清晰图像,直到达到完整分辨率。这一框架遵循传统方法中的多尺度机制,其中「由粗到精」流程在处理大的模糊核时很常见 [6]。
在本论文中,我们探索了一种用于多尺度图像去模糊的更有效的网络结构。我们提出了一种新的尺度循环网络(SRN:scale-recurrent network),它讨论和解决了基于 CNN 的去模糊系统中两个重要的一般性问题。
尺度训练结构
在现有的多尺度方法中,求解器及其每个尺度的参数通常是一样的。直观上看,这是一种自然的选择,因为在每个尺度上,我们的目标都是求解同样的问题。还可以发现,每个尺度上使用不同的参数可能会引入不稳定性并带来非限制性解空间的额外问题。另一个问题是输入图像可能会有不同的分辨率和运动尺度。如果允许每个尺度上都进行参数调节,那么这个解可能会在特定图像分辨率或运动尺度上过拟合。
基于同样的原因,我们相信这个方案也应该被应用于基于 CNN 的方法。但是,近期的级联网络 [4, 25] 仍然为每个尺度使用了独立的参数。在本研究中,我们提出在不同尺度上共享网络权重,从而显著降低训练复杂度以及引入明显的稳定性优势。
这种做法有两种好处。首先,这能显著减少可训练参数的数量。即使用同样数目的训练数据,在共享权重的循环利用下的效果也像是有多倍数据来学习参数,这实际上相当于在尺度上进行的数据增强。其次,我们提出的结构可以利用到循环模块,其状态传递能隐含地获取各个尺度上的有用信息并帮助图像恢复。
编码器-解码器 ResBlock 网络
编码器-解码器结构在多种计算机视觉任务上有效应用 [23, 31, 33, 39],我们探索了将其应用于图像去模糊任务的有效方法。在本论文中,我们将表明直接应用已有的编码器-解码器结构不能得到最优结果。相对而言,我们的编码器-解码器 ResBlock 网络会放大各种 CNN 结构的优势并实现训练的可行性。同时,这还会产生非常大的感受野,这对运动模糊很大的图像的去模糊至关重要。
我们的实验表明,使用循环结构并结合上述优势,我们的端到端深度图像去模糊框架可以极大地提升训练效率(大约 [25] 的四分之一的训练时间就能实现近似的恢复效果)。我们只使用了不到三分之一的可训练参数以及远远更少的测试时间。除了训练效率,我们的方法在定量和定性比较上都能得到比已有方法更高质量的结果,如图 1 所示。我们将这个框架称为尺度循环网络(SRN)。

图 1:一个真实拍摄的示例。(a)输入的模糊图像,(b)Sun et al. [32] 的结果,(c)Nah et al. [25] 的结果,(d)我们的结果
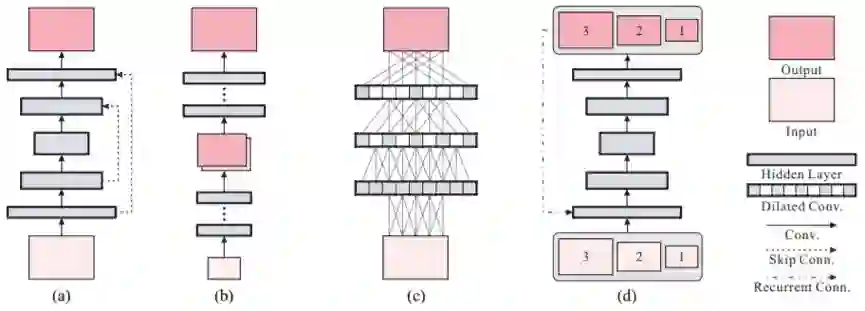
图 2:用于图像处理的不同 CNN。(a)U-Net [27] 或编码器-解码器网络 [24],(b)多尺度 [25] 或级联细化网络 [4],(c)扩张卷积网络 [5],(d)我们提出的尺度循环网络(SRN)。
网络架构
我们将我们提出的网络的整体架构称为 SRN-DeblurNet,如图 3 所示。其以在不同尺度上从输入图像下采样的一个模糊图像序列为输入,然后得到一组对应的锐利图像。在全分辨率下的锐利图像即为最终输出。
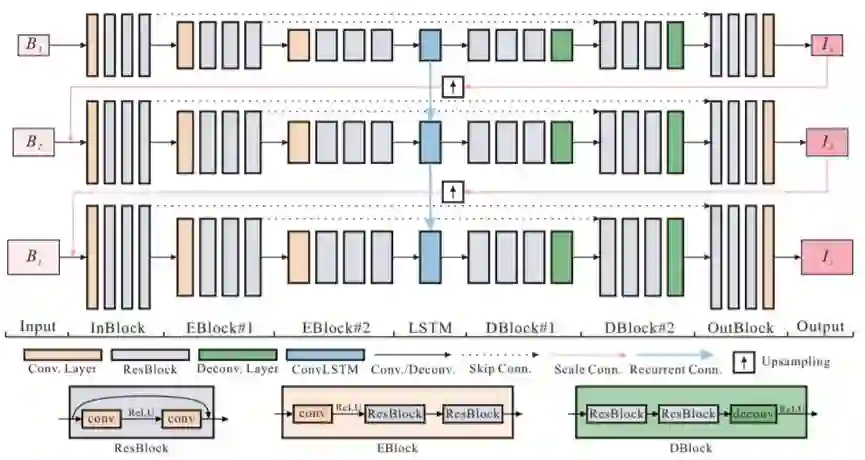
图 3:我们提议的 SRN-DeblurNet 框架
实验
我们的实验是在一台 PC 上执行的,其配置有英特尔 Xeon E5 CPU 和一块英伟达 Titan X GPU。我们在 TensorFlow 平台 [11] 上实现了我们的框架。我们全面评估了多种网络结构,以验证不同的结构对于效果的影响。为了公平起见,除非另有说明,所有实验都是在同一数据集上,使用同样的训练配置完成的。
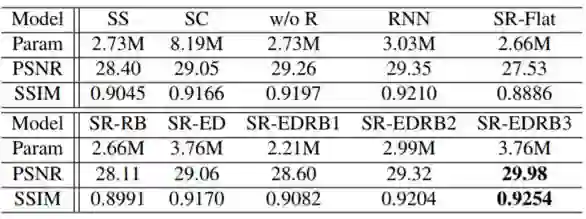
表 1:基准模型的定量结果
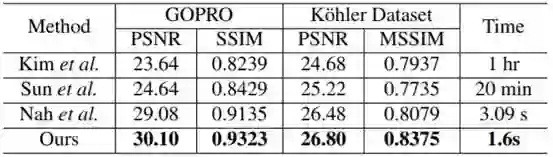
表 2:在测试数据集上的定量结果(PSNR/SSIM)

图 5:在测试数据集上的视觉比较。从上到下:输入、Whyte et al. [34]、Sun et al. [32]、Nah et al. [25] 和我们的方法。
论文:用于深度图像去模糊的尺度循环网络(Scale-recurrent Network for Deep Image Deblurring)

论文地址: http://www.cse.cuhk.edu.hk/leojia/papers/scaledeblur_cvpr18.pdf
摘要:在单图像去模糊中,「粗糙到精细」方案(即以金字塔的形式在不同分辨率上逐步恢复锐利图像)在传统的基于优化的方法和近期的基于神经网络的方法中都非常成功。在本论文中,我们研究了这一策略并提出了一种用于去模糊任务的尺度循环网络(SRN-DeblurNet)。相比于 [25] 中很多近期的基于学习的方法,它的网络结构更简单,参数数量更少,训练更容易。我们在带有复杂运动的大规模去模糊数据集上评估了我们的方法。结果表明,在定量和定性比较上,我们的方法能得到比之前最佳结果更高质量的结果。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




