业界 | 谷歌用新的语音数据扩增技术大幅提升语音识别准确率

AI 科技评论按:把一段输入音频转换为一段文本的任务「自动语音识别(ASR)」,是深度神经网络的流行带来了极大变革的人工智能任务之一。如今常用的手机语音输入、YouTube 自动字幕生成、智能家电的语音控制都受益于自动语音识别技术的发展。不过,开发基于深度学习的语音识别系统还不是一个已经完善解决的问题,其中一方面的难点在于,含有大量参数的语音识别系统很容易过拟合到训练数据上,当训练不够充分时就无法很好地泛化到从未见过的数据。
当对于图像分类任务,当训练数据的数量不足的时候我们可以使用各种数据扩增(data augmentation)方法生成更多数据,提高网络的表现。但是在自动语音识别任务中情况有所不同,传统的数据扩增方法一般是对音频波形做一些变形(比如加速、减速),或者增加背景噪声,都可以生成新的训练数据,起到把训练数据集变大的效果,帮助网络更好地学习到有用的特征。不过,现有的传统音频数据扩增方法会带来明显的额外计算能力开销,有时也避免不了需要使用额外的数据。
在谷歌 AI 的近期论文《SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition》(SpecAugment:一个用于自动语音识别的简单数据扩增方法,https://arxiv.org/abs/1904.08779)中,谷歌的研究人员们提出了一种扩增音频数据的新方法,主要思路是把它看做是一个视觉问题而不是音频问题。具体来说,他们在 SpecAugment 不再直接使用传统的数据扩增方法,而是在音频的光谱图上(音频波形的一种视觉表示)施加扩增策略。这种方法简单、计算力需求低,而且不需要额外的数据。它能非常有效地提高语音识别系统的表现。雷锋网 AI 科技评论根据谷歌技术博客介绍如下。
新的音频数据扩增方法 SpecAugment
对于传统语音识别系统,音频波形在输入网络之前通常都需要编码为某种视觉表示,比如编码为光谱图。而传统的语音数据扩增方法一般都是在编码为光谱图之前进行的,这样每次数据扩增之后都要重新生成新的光谱图。在这项研究中,作者们尝试就在光谱图上进行数据扩增。由于直接作用于网络的输入特征,数据扩增过程可以在网络的训练过程中运行,而且不会对训练速度造成显著影响。
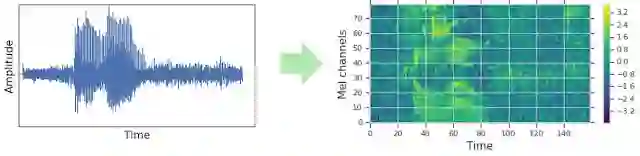
音频波形(时间-振幅)关系转化为梅尔频谱图(时间-梅尔频率),然后再输入网络
SpecAugment 对光谱图的修改方式有:沿着时间方向扭曲,遮蔽某一些频率段的信号,以及遮蔽某一些时间段的发音。作者们选择使用的这些扩增方式可以帮助网络面对时间方向的变形、部分频率信号的损失以及部分时间段的信号缺失时更加鲁棒。这些扩增策略的示意图如下。
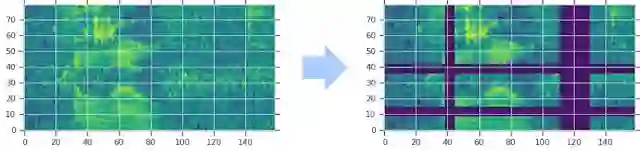
图中的梅尔频谱图经过了时间方向扭曲、多个频率段信号遮蔽(横条)以及多个时间段遮蔽(纵向条)。图中的遮蔽程度有所夸张。
作者们在 LibriSpeech 数据集上用实验测试了 SpecAugment 的效果。他们选取了三个语音识别常用的端到端 LAS 模型,对比使用数据扩增和不使用数据扩增的网络表现。自动语音识别模型表现的测量指标是单词错误率(WER),用模型输出的转录文本和标准文本对比得到。在下面的对比试验中,训练模型使用的超参数不变、每组对比中模型的参数数量也保持固定,只有训练模型用的数据有区别(使用以及不使用数据扩增)。试验结果表明,SpecAugment 不需要任何额外的调节就可以提高网络的表现。
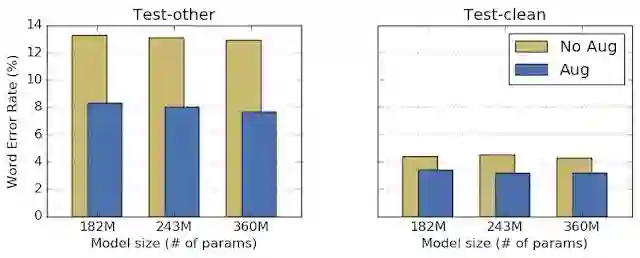
在 LibriSpeech 数据集上的测试中,每组测试中经过数据增强(蓝色条)都取得了更低的单词错误率。Test-other 数据集含有噪声,Test-clean 数据集不含有噪声
更重要的是,由于 SpecAugment 扩增后的数据里有故意损坏的部分,这避免了模型过拟合到训练数据上。作者们进行了对比试验如下,未使用数据扩增的模型(棕黄色线)在训练数据集上取得了极低的单词错误率,但是在 Dev-other(有噪声测试集)和 Dev-clean(无噪声数据集)上的表现就要差很多;使用了数据扩增的模型(蓝色线)则正相反,在训练数据集上的单词错误率较高,然后在 Dev-other 和 Dev-clean 上都取得了优秀的表现,甚至在 Dev-clean 上的错误率还要低于训练数据集上的错误率;这表明 SpecAugment 数据扩增方法不仅提高了网络表现,还有效防止了过拟合的发生。
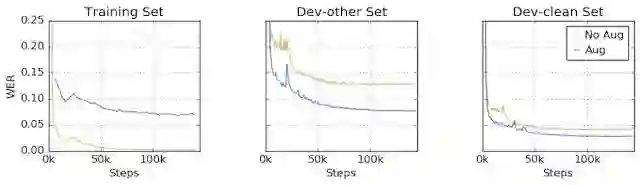
借助 SpecAugment 取得前所未有的模型表现
由于 SpecAugment 可以带来没有过拟合的表现提升,研究人员们甚至可以尝试使用更大容量的网络,得到表现更好的模型。论文作者们进行了实验,在使用 SpecAugment 的同时,使用参数更多的模型、更长的训练时间,他们分别在 LibriSpeech 960h 和 Switchboard 300h 两个数据集上都大幅刷新了此前的最佳表现记录(SOTA)。

作者们也为这种方法的出色表现感到惊讶,甚至于,以往在 LibriSpeech和 Switchboard 这样较小的数据集上有优势的传统语音识别模型也不再领先。
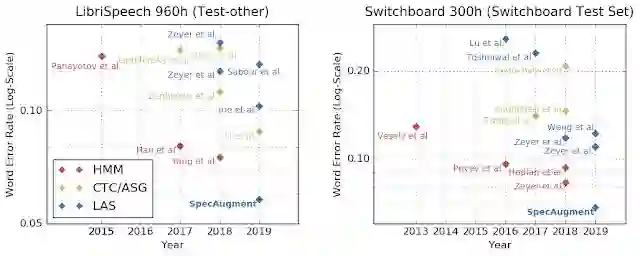
借助语言模型再上一层楼?甚至都不需要
自动语音识别模型的表现还可以通过语言模型进一步提高。在大量纯文本数据上训练出的语言模型可以学到一些语言规律,然后用它来更正、优化语音识别模型的输出。不过,语言模型通常需要独立于语音识别模型训练,而且模型的体积很大,很难在手机之类的小型设备上使用。
在 SpecAugment 的研究中,作者们意外发现借助 SpecAugment 训练的模型,在不使用语言模型增强的情况下就已经可以击败之前的所有使用语言模型增强的模型。这不仅意味着语音识别模型+语言模型的总体表现也被刷新,更意味着未来语音识别模型完全可以抛弃语言模型独立工作。
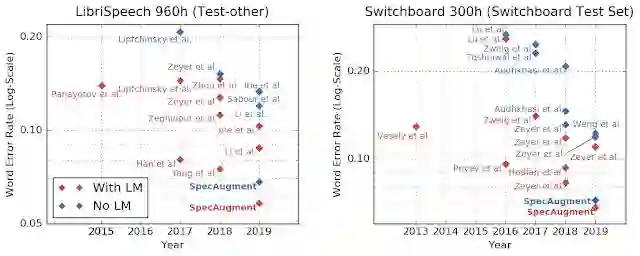
以往的自动语音识别系统研究多数都关注于找到更好的网络结构,谷歌的这项研究也展现了一个被人忽略的研究方向:用更好的方法训练模型,也可以带来大幅提升的网络表现。
论文原文见:
https://arxiv.org/abs/1904.08779
via ai.googleblog.com