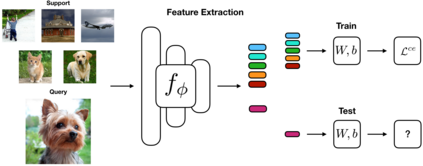
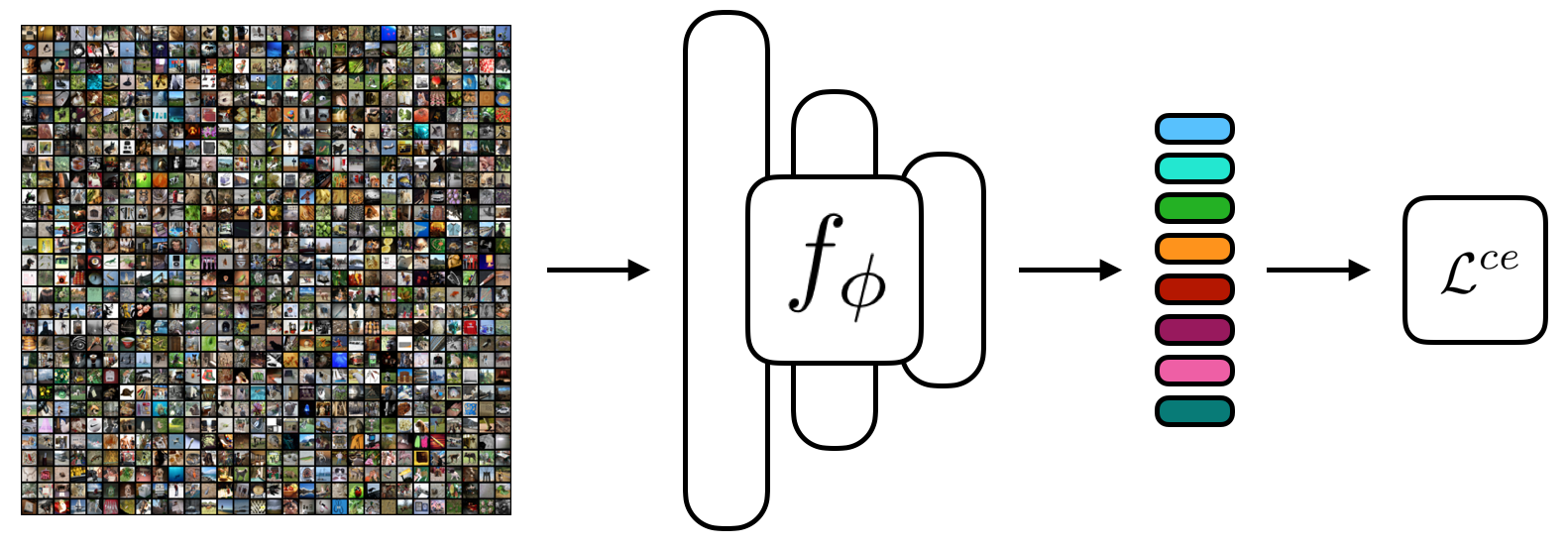
The focus of recent meta-learning research has been on the development of learning algorithms that can quickly adapt to test time tasks with limited data and low computational cost. Few-shot learning is widely used as one of the standard benchmarks in meta-learning. In this work, we show that a simple baseline: learning a supervised or self-supervised representation on the meta-training set, followed by training a linear classifier on top of this representation, outperforms state-of-the-art few-shot learning methods. An additional boost can be achieved through the use of self-distillation. This demonstrates that using a good learned embedding model can be more effective than sophisticated meta-learning algorithms. We believe that our findings motivate a rethinking of few-shot image classification benchmarks and the associated role of meta-learning algorithms. Code is available at: http://github.com/WangYueFt/rfs/.
翻译:最近元学习研究的重点是发展学习算法,这种算法可以迅速适应以有限的数据和低计算成本测试时间任务。少见的学习被广泛用作元学习的标准基准之一。在这项工作中,我们展示了一个简单的基线:在元培训组上学习一个受监督或自我监督的代表制,然后在这种代表制上培训一个线性分类员,这优于最先进的少见的学习方法。通过使用自我蒸馏,可以取得额外的推动力。这表明,使用一个良好的学习嵌入模型比复杂的元学习算法更有效。我们认为,我们的调查结果促使人们重新思考少见的图像分类基准和元学习算法的相关作用。代码见:http://github.com/WangYueFt/rfs/。