学界 | 现实版柯南「蝴蝶结变声器」:谷歌发布从声纹识别到多重声线语音合成的迁移学习
机器之心报道
参与:邱陆陆
近日,谷歌科学家 Ye Jia 等人在 arXiv 上发布了一篇用迁移学习完成语音合成的论文。这项全新的语音合成技术能够通任意一段参考音频中提取出说话者的声纹信息,并生成与其相似度极高的合成语音,参考音频与最终合成的语音甚至不必是同一种语言。除了利用参考音频作为输入外,该技术还能随机生成虚拟的声线,以「不存在的说话者」的声音进行语音合成。
音频按顺序分别为参考音频 1、以参考音频 1 的声线为输入的生成句子 1(Take a look at these pages for crooked creek drive.)、生成句子 2(There are several listings for gas station.)、参考音频 2、以参考音频 2 的声线为输入的生成句子 1(同上)、生成句子 2(同上)。
点此查看更多生成音频样本。https://google.github.io/tacotron/publications/speaker_adaptation/
这篇名为「从声纹识别到多重声线语音合成的迁移学习」的论文中的系统由三个模块组成,分别是:
声纹编码器
基于 Tacotron2 的语音合成器
基于 WaveNet 的发声器
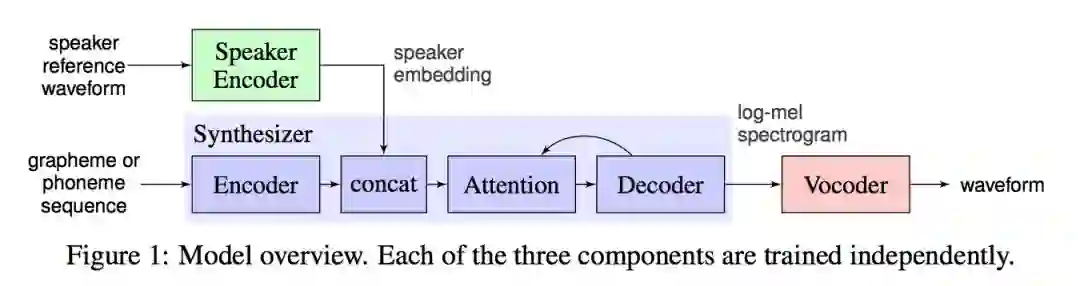
图 1: 论文所采用的系统架构。
其中,声纹编码器用于从一段参考音频中提取固定维度的声纹特征。本文的声纹编码器采用了 3 层 LSTM 架构,提取的声纹特征为 256 维。值得一提的是,声纹编码器不但不需要训练数据包含准确的文本,甚至允许数据中包含背景噪音。声纹编码器只需要数据来自于足够多的说话者,以覆盖尽可能多样的声纹即可。
随后,提取出的声纹特征与文本特征一起作为输入进入 Tracotron2 合成器,二者按照时间步进行拼接。相比于声纹编码器,合成器对训练数据的要求要严格得多,准确的文本,足够的时长,还要保证数据中不包含噪音。
合成器生成的频谱特征进而进入基于 WaveNet 的发声器,完全独立于声纹编码器的发声器将频谱特征转换为时序波形。
在训练方面,由于三个不同模块对训练数据集的要求截然不同,本文采用了不同的数据集分开训练了三个模块。
作者分别用一个非公开语音搜索语料库(3600 万条,18000 名说话者,美国,中位数时长 3.9 秒)训练了声纹编码器,用经过处理的公开数据集 VCTK(44 小时,109 名说话者,无噪音,英音,中位数时长 1.8 秒)和 LibriSpeech(436 小时,1172 名说话者,有背景噪音,中位数时长 5 秒)各自训练了语音合成器和发声器。
实验结果主要从合成语音的自然度,以及与参考说话者的相似度这两方面来度量模型的质量。在 VCTK 数据集上,对于训练数据中未出现过的说话者,自然度 MOS 能够达到 4.20,接近于真实语音的 4.49;在 LibriSpeech 上,自然度 MOS 达到 4.12,同样接近于真实语音的 4.42。在相似度方面,VCTK 和 LibriSpeech 上的 MOS 分别达到 3.28 和 3.03,虽然与真实语音的 4.67 和 4.33 相比还有不小差距,但也已经很大程度地保留了说话者的声音信息。文章同时提供了一组结果证明,增加训练数据中所出现的说话者数量,会显著提升合成语音的自然度和相似度。
最后,当模型训练完成后,如果将声纹编码器去掉,用随机生成的特征代替声纹编码器的输出作为合成器的输入,就可以给出虚拟声线的合成语音。这种方式生成的语音声线明显有别于训练数据中的任意说话者,并且能够达到 3.65 的自然度。
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
https://arxiv.org/abs/1806.04558
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




