业界 | Facebook开源TTS神经网络VoiceLoop:基于室外声音的语音合成(附PyTorch实现)
选自GitHub
作者:Facebook Research
机器之心编译
参与:黄小天、路雪
近日,Facebook 在题为《Voice Synthesis for in-the-Wild Speakers via a Phonological Loop》的论文中提出一个文本转语音(TTS)的新神经网络VoiceLoop,它能够把文本转化为在室外采样的声音中的语音。目前 VoiceLoop 已在 GitHub 上开源并附有 PyTorch 实现。机器之心对论文摘要进行了编译。论文与GitHub链接请见文中。
论文:Voice Synthesis for in-the-Wild Speakers via a Phonological Loop

论文地址:https://arxiv.org/abs/1707.06588
摘要:我们展示了一种新的文本转语音的神经方法,该方法能够将文本转换成室外采样的声音的语音。与其他文本转语音的系统不同,我们的解决方案能够处理公众演讲中获取的非约束样本(unconstrained sample)。该网络架构比现有的架构简单,基于新型的移位缓冲工作储存器(shifting buffer working memory)。同样的缓冲用于评估注意力、计算输出音频以及更新缓冲。输入句子通过包含每个字或音素的条目的上下文无关查找表(context-free lookup table)进行编码。最后,说话者语音被简单表征为短向量,适用于生成语音里新的说话者和可变性(variability),该语音通过在生成音频之前启动缓冲来获得。在两个数据集上的实验结果证明该方法具备处理多个说话者和室外语音的能力。为了促进可重复性,我们公开了源代码和模型:PyTorch 代码和样本音频文件可在 ytaigman.github.io/loop 获取。
该方法已在论文《Voice Synthesis for in-the-Wild Speakers via a Phonological Loop》详细描述,以下是其 PyTorch 实现。
项目地址:https://github.com/facebookresearch/loop
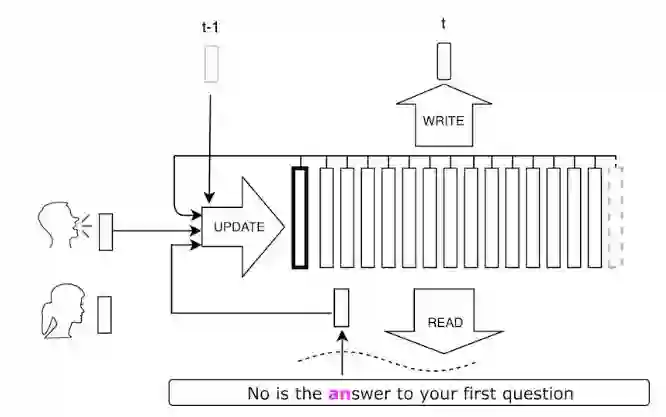
VoiceLoop 是一个文本转语音(TTS)的神经系统,能够把文本转化为在室外采样的声音中的语音。这里有一些演示样本(https://ytaigman.github.io/loop/site/)。
重要链接
演示样本:https://ytaigman.github.io/loop/site/
快速入门:https://github.com/facebookresearch/loop#quick-start
设置:https://github.com/facebookresearch/loop#setup
训练:https://github.com/facebookresearch/loop#training
快速启动
在安装中遵循以下指示,并简单地执行以下命令:
python generate.py --npz data/vctk/numpy_features_valid/p318_212.npz --spkr 13 --checkpoint models/vctk/bestmodel.pth
结果将被放置在 models/vctk/results。它将生成两个样本:
生成样本将会以 gen_10.wav 的扩展名保存。
它的真值(测试)样本也被生成,并使用 orig.wav 扩展名保存。
你也可以用不同说话者的语音生成相同的文本,具体如下:
python generate.py --npz data/vctk/numpy_features_valid/p318_212.npz --spkr 18 --checkpoint models/vctk/bestmodel.pth
这将会生成以下样本(https://ytaigman.github.io/loop/demos/vctk_tutorial/p318_212.gen_14.wav)。
下面是对应的注意力图:
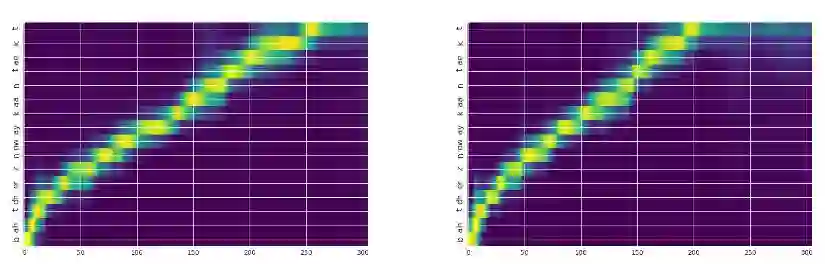
说明:X 轴是输出时间(声学样本),Y 轴是输入(文本/音素)。左图是说话者 10,右图是说话者 14
最后,该系统还支持自由文本:
python generate.py --text "hello world" --spkr 1 --checkpoint models/vctk/bestmodel.pth
安装
需求:Linux/OSX、Python2.7 和 PyTorch 0.1.12。代码当前版本需要 CUDA 支持训练。生成将在 CPU 上完成。
git clone https://github.com/facebookresearch/loop.git
cd loop
pip install -r scripts/requirements.txt
数据
论文中用于训练模型的数据可以通过以下方式下载:
bash scripts/download_data.sh
脚本下载 VCTK 的子集,并进行预处理。该子集包括美国口音的说话者。使用 Merlin 对该数据集进行预处理——使用 WORLD 声码器从每个音频剪辑文件中抽取声码器特征。下载完成后,该数据集将位于子文件夹 data 下,如下所示:
loop
├── data
└── vctk
├── norm_info
│ ├── norm.dat
├── numpy_feautres
│ ├── p294_001.npz
│ ├── p294_002.npz
│ └── ...
└── numpy_features_valid
使用 Kyle Kastner 的脚本执行预处理管线,脚本链接:https://gist.github.com/kastnerkyle/cc0ac48d34860c5bb3f9112f4d9a0300。
预训练模型
通过以下方式下载预训练模型:
bash scripts/download_models.sh
下载完成后,模型在子文件夹 models 下,如下所示:
loop
├── data
├── models
├── vctk
│ ├── args.pth
│ └── bestmodel.pth
└── vctk_alt
最后,语音生成需要 SPTK3.9 和 WORLD 声码器,正如 Merlin 中一样。使用下列方式下载可执行程序:
bash scripts/download_tools.sh
然后得到以下子目录:
loop
├── data
├── models
├── tools
├── SPTK-3.9
└── WORLD
训练
在 vctk 上训练一个新模型,首先使用水平为 4 的噪声训练模型,输入长度为 100 的序列:
python train.py --expName vctk --data data/vctk --noise 4 --seq-len 100 --epochs 90
之后,在全长序列上使用水平为 2 的噪声继续训练模型:
python train.py --expName vctk_noise_2 --data data/vctk --checkpoint checkpoints/vctk/bestmodel.pth --noise 2 --seq-len 1000 --epochs 90
引用
如果你觉得这些代码对你的研究有所帮助,请引用:
@article{taigman2017voice,
title = {Voice Synthesis for in-the-Wild Speakers via a Phonological Loop},
author = {Taigman, Yaniv and Wolf, Lior and Polyak, Adam and Nachmani, Eliya},
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprinttype = {arxiv},
eprint = {1705.03122},
primaryClass = "cs.CL",
year = {2017}
month = July,
}
许可
Loop 有 CC-BY-NC 许可。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



