泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练


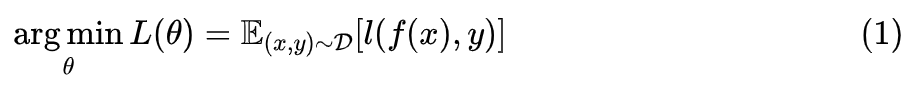
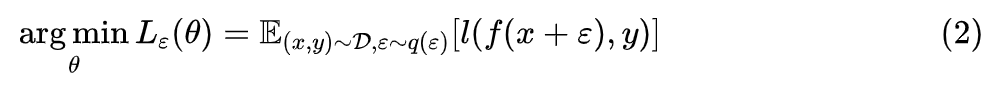

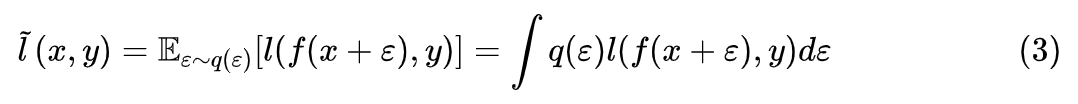
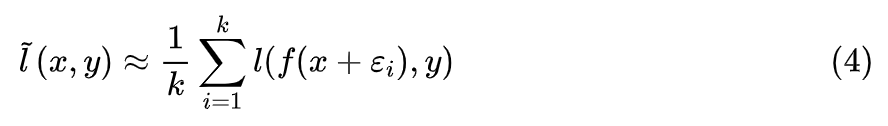
近似展开
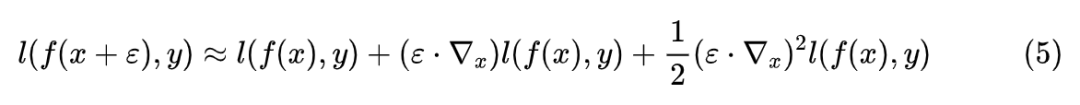
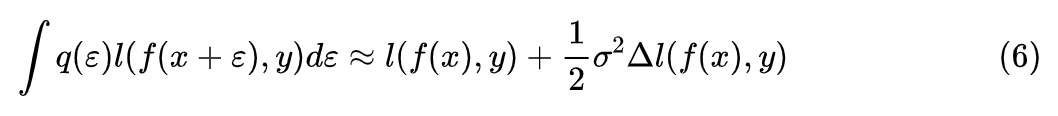

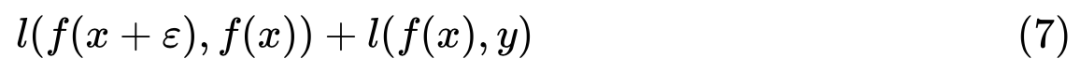
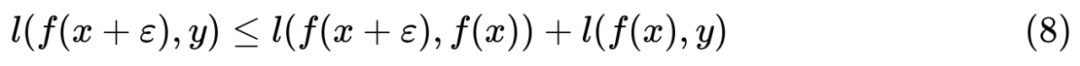
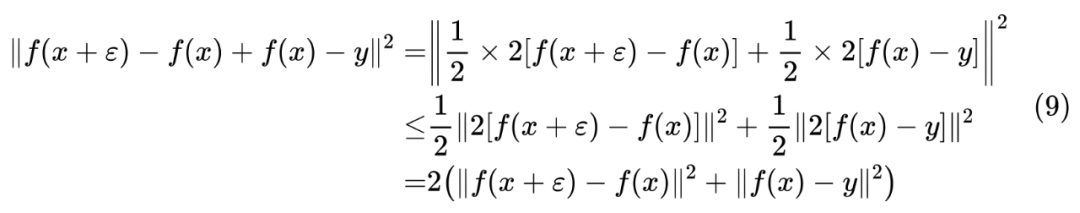
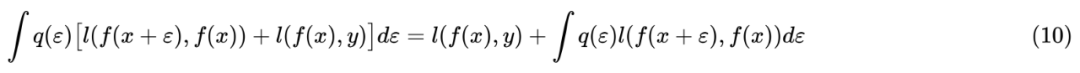
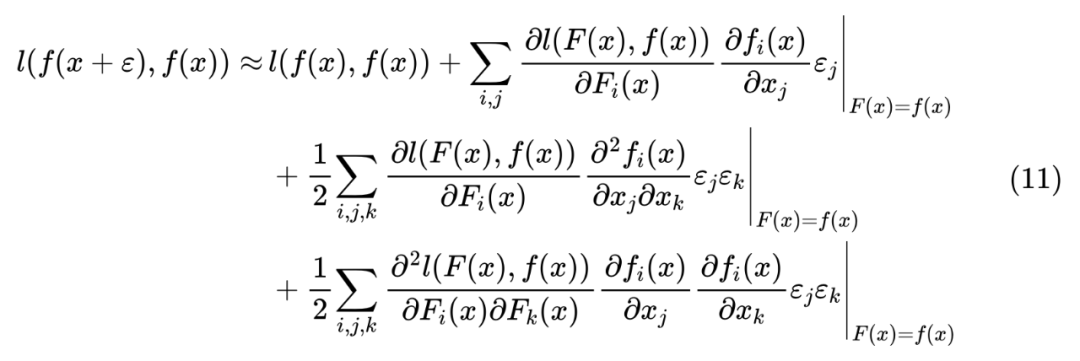
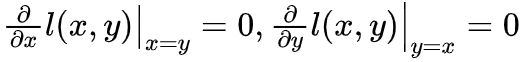 。
。
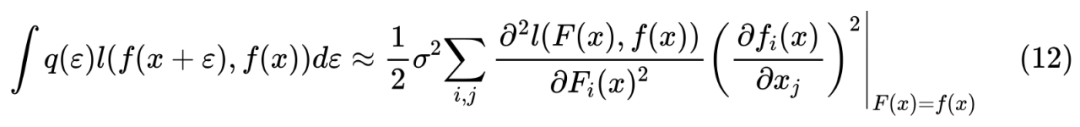
梯度惩罚
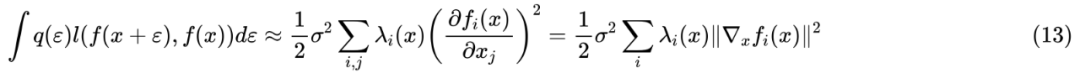
这些结果大家多多少少可以从著名的“花书”《深度学习》[1] 中找到类似的,所以并不是什么新的结果。类似的推导还可以参考文献 Training with noise is equivalent to Tikhonov regularization [2]。
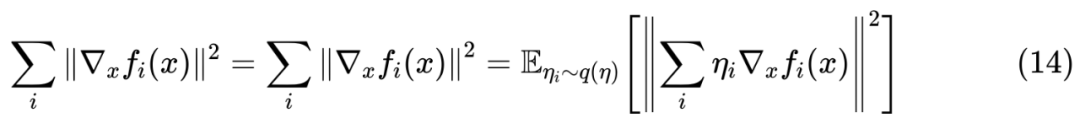

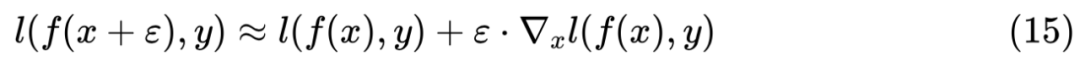
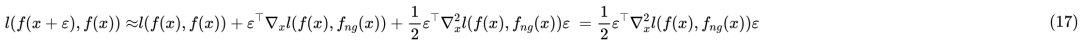
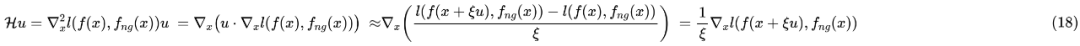
关于对抗训练的 Keras 实现,在对抗训练浅谈:意义、方法和思考(附Keras实现)一文中已经给出过,这里笔者给出 Keras 下虚拟对抗训练的参考实现:
def virtual_adversarial_training(
model, embedding_name, epsilon=1, xi=10, iters=1
):
"""给模型添加虚拟对抗训练
其中model是需要添加对抗训练的keras模型,embedding_name
则是model里边Embedding层的名字。要在模型compile之后使用。
"""
if model.train_function is None: # 如果还没有训练函数
model._make_train_function() # 手动make
old_train_function = model.train_function # 备份旧的训练函数
# 查找Embedding层
for output in model.outputs:
embedding_layer = search_layer(output, embedding_name)
if embedding_layer is not None:
break
if embedding_layer is None:
raise Exception('Embedding layer not found')
# 求Embedding梯度
embeddings = embedding_layer.embeddings # Embedding矩阵
gradients = K.gradients(model.total_loss, [embeddings]) # Embedding梯度
gradients = K.zeros_like(embeddings) + gradients[0] # 转为dense tensor
# 封装为函数
inputs = (
model._feed_inputs + model._feed_targets + model._feed_sample_weights
) # 所有输入层
model_outputs = K.function(
inputs=inputs,
outputs=model.outputs,
name='model_outputs',
) # 模型输出函数
embedding_gradients = K.function(
inputs=inputs,
outputs=[gradients],
name='embedding_gradients',
) # 模型梯度函数
def l2_normalize(x):
return x / (np.sqrt((x**2).sum()) + 1e-8)
def train_function(inputs): # 重新定义训练函数
outputs = model_outputs(inputs)
inputs = inputs[:2] + outputs + inputs[3:]
delta1, delta2 = 0.0, np.random.randn(*K.int_shape(embeddings))
for _ in range(iters): # 迭代求扰动
delta2 = xi * l2_normalize(delta2)
K.set_value(embeddings, K.eval(embeddings) - delta1 + delta2)
delta1 = delta2
delta2 = embedding_gradients(inputs)[0] # Embedding梯度
delta2 = epsilon * l2_normalize(delta2)
K.set_value(embeddings, K.eval(embeddings) - delta1 + delta2)
outputs = old_train_function(inputs) # 梯度下降
K.set_value(embeddings, K.eval(embeddings) - delta2) # 删除扰动
return outputs
model.train_function = train_function # 覆盖原训练函数
# 写好函数后,启用虚拟对抗训练只需要一行代码
virtual_adversarial_training(model_vat, 'Embedding-Token')https://github.com/bojone/bert4keras/blob/master/examples/task_sentiment_virtual_adversarial_training.py
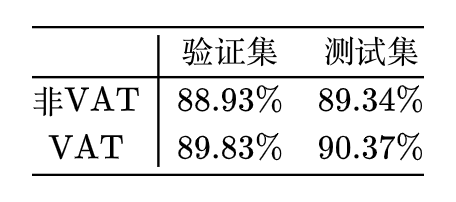

文章小结
本文先介绍了添加随机噪声这一常规的正则化手段,然后通过近似展开与积分的过程,推导了它与梯度惩罚之间的联系,并从中引出了可以用于半监督训练的模型平滑损失,接着进一步联系到了监督式的对抗训练和半监督的虚拟对抗训练,最后给出了 Keras 下虚拟对抗训练的实现和例子。

参考链接
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



