学界 | 精准防御对抗性攻击,清华大学提出对抗正则化训练方法DeepDefense
选自arXiv
作者:Ziang Yan等
机器之心编译
参与:刘晓坤、黄小天
本文提出了一个名为 DeepDefense 的训练方案,其核心思想是把基于对抗性扰动的正则化项整合进分类目标函数,从而使模型可以学习直接而精确地防御对抗性攻击。在 MNIST、CIFAR-10 和 ImageNet 上的扩展实验证明了该方法可以显著提高不同深度学习模型对高强度对抗攻击的鲁棒性,同时还不会牺牲准确率。
虽然深度神经网络(DNN)在许多挑战性的计算机视觉任务中都取得了当前最优的表现,但在对抗样本(在人类感知上和真实图像很相似,但却能欺骗学习模型做出错误预测的生成图像)面前,它们仍然非常脆弱 [32]。
合成对抗样本的通常方法是应用最坏情况的扰动到真实图像上 [32,7,26]。通过适当的策略,仅有真实图像像素值 1/1000 的扰动幅度就可以成功欺骗 DNN 模型,这种扰动通常对于人类来说是不可感知的。有研究称即使是当前最佳的 DNN 模型也会被这类对抗样本所欺骗,得出高信度的错误分类结果 [19]。更糟糕的是,对抗扰动还可以迁移到不同的图像和网络架构上 [25]。这种迁移性使得黑箱攻击变得可行,即不需要任何模型架构或参数的知识就可以实现欺骗 [28]。
虽然 DNN 的这种特性很有趣,但其还会导致现实世界应用的潜在问题(例如,自动驾驶汽车和人脸识别支付等)。和对抗随机噪声的不稳定性不同(已被证明理论上和实践上都不是很重要 [6,32]),深度学习的对抗扰动脆弱性仍然是很严重的问题。目前有许多研究都尝试对其进行分析和解释 [32,7,5,12]。例如,Goodfellow 等人 [7] 称 DNN 的脆弱性的主要原因在于线性本质(而不是非线性)以及过拟合。基于该解释,他们设计了一种高效的线性扰动,并在进一步研究中将其结合到对抗训练中 [32],以优化正则化效果。最近,Cisse 等人 [5] 探索了基于 DNN 分类器的 Lipschitz 常数,并提出了 Parseval 训练法对该常数进行控制,从而提高 DNN 分类器的鲁棒性。然而,和某些以前提出的基于正则化的方法类似 [8],Parseval 训练法需要对其理论最优约束做一些近似,限制了其对非常强的对抗攻击的有效性。
本文提出了 DeepDefense,这是一种用于训练 DNN 提高模型鲁棒性的对抗正则化方法。与很多已有的使用近似和优化非严格边界的方法不同,研究者准确地将一个基于扰动的正则化项结合到分类目标函数中。从理论的角度看,这使得 DNN 模型可以直接从对抗扰动中学习并进一步对其进行防御。具体来说,就是给正确分类的样本分配更大的正则化项值,给错误分类的样本分配更小的正则化项值,来惩罚对抗扰动的范数。作为正则化项,它将和原始的学习目标函数联合优化,并且整个问题将被当做训练一个类似递归型的网络而高效地求解。在 MNIST、CIFAR-10 和 ImageNet 上的扩展实验证明了该方法可以显著提高不同 DNN 对高强度对抗攻击的鲁棒性,同时还不会牺牲准确率。
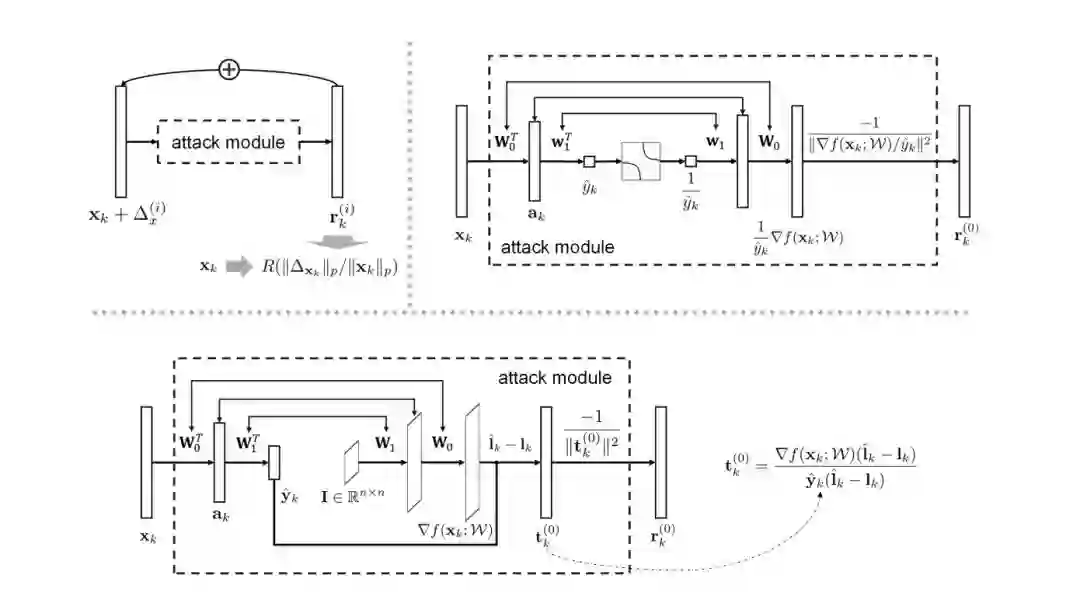
图 1:左上,该类似递归型的网络以重塑的图像 x_k 为输入,并相继地通过利用一个预设计的攻击模块计算每个 r^(i)_k(0≤i<u)。右上:用整合的攻击模块生成 r^(0)_k 的示例,其中三个双向箭头,从下到上,分别表示第一个和第四个全连接层之间的权重共享、两个 ReLU 激活层之间的索引共享,以及第二个和第三个全连接层之间的权重共享。底部:n 类别分类场景的攻击模块(n≥2),其中 y^hat_k∈R^n 表示 softmax 之前的网络输出,I∈R^nxn 是单位矩阵,I^hat_k∈{0,1}^n 和 I_k∈{0,1}^n 分别表示当前预测标签的 one-hot 编码,以及在第一次迭代中用于欺骗的标签。
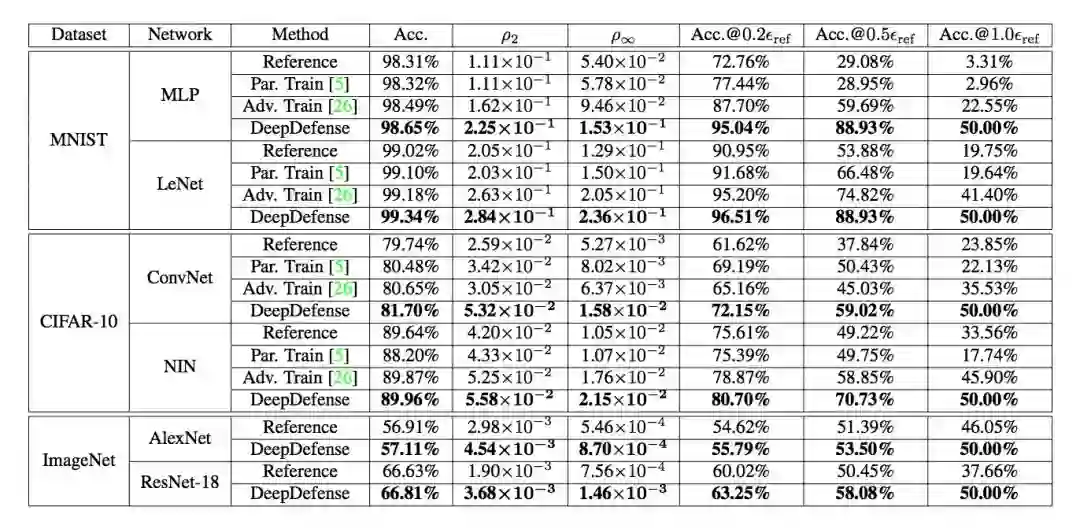
表 1:不同防御方法在对抗攻击下的测试性能。第 4 列:无对抗扰动的测试图像的准确率。第 5 列:在 DeepFool 攻击下的 ρ_2 值。第 6 列:在 Fast Gradient Sign(FGS)攻击下的 ρ_∞ 值。第 7-9 列:FGS 扰动图像上的分类准确率,ε_ref 是使得 50% 的扰动图像被本文提出的正则化模型误分类的最小 ε 值。
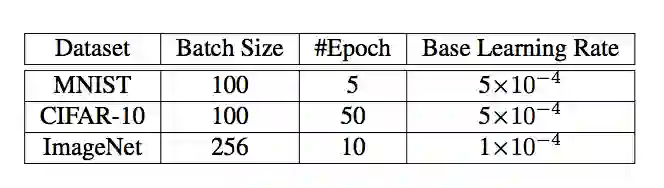
表 2:精调过程中的一些超参数。
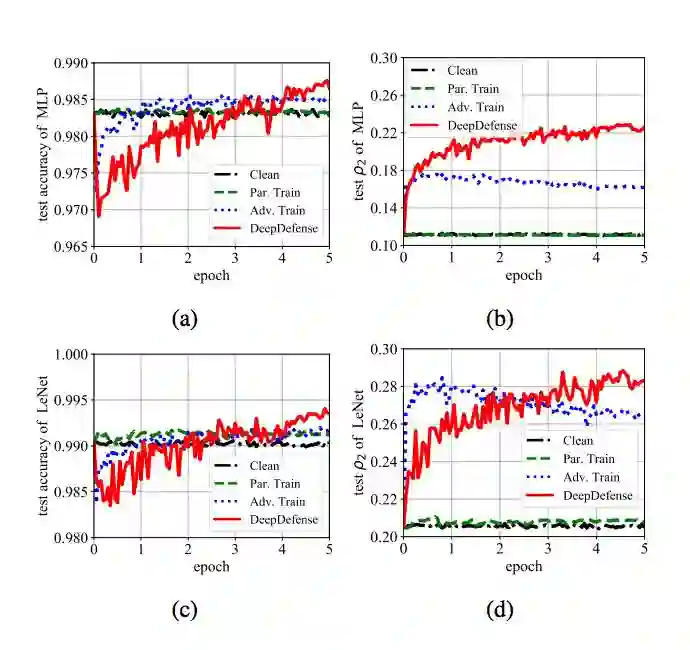
图 2:MNIST 上的收敛曲线:(a) MLP 的测试精度,(b) MLP 的测试ρ_2 值,(c) LeNet 的测试精度,(d) LeNet 的测试 ρ_2 值。「Clean」表征无扰动图像上的精调。

图 3:一张来自 MNIST 测试集并标注为「0」的图像 (x_k),并基于 DeepFool 生成对抗样本以欺骗不同的模型,包括:(b) 参考模型,(c)-(e):带有对抗性训练的精调模型、Parseval 训练以及我们的 DeepDefense。图中上方的箭头表示实例被错误分类的类别结果,下方的数字表示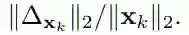
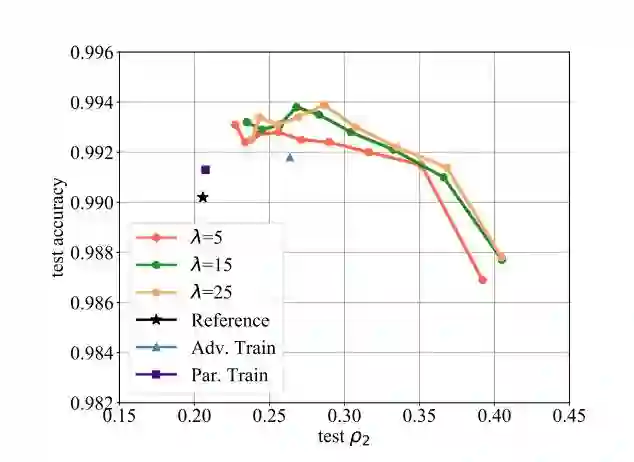
图 4:带有变化的超参数的 DeepDefense 在 MNIST 上的表现。这里使用 LeNet 作为参考网络。同一曲线上的不同点对应于不同 c 值的精调(从左至右依次减少)。
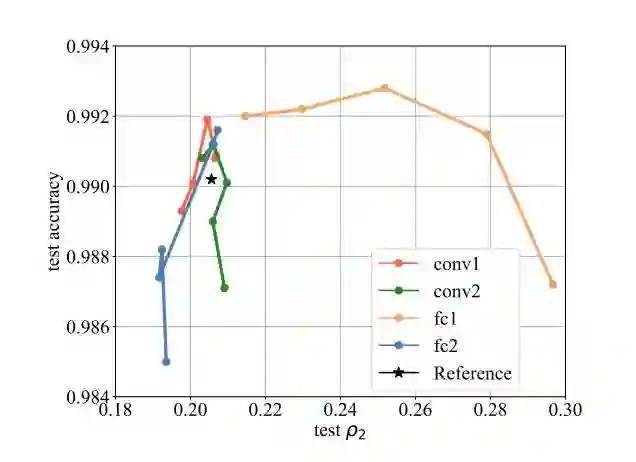
图 5:当仅优化一层以正则化 LeNet 分类目标函数时本文方法的表现。同一曲线上的不同点对应于不同的 c 值。
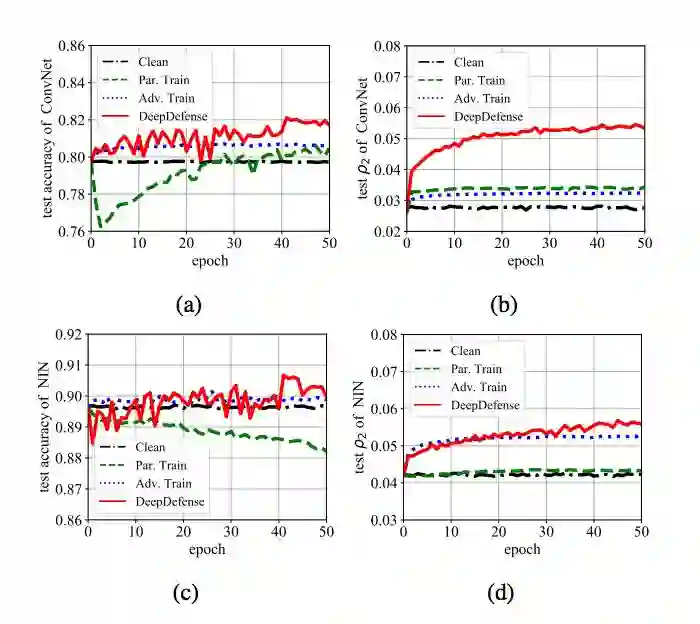
图 6:CIFAR-10 上的收敛曲线:(a) ConvNet 的测试精度,(b) ConvNet 的测试 ρ_2 值,(c) NIN 的测试精度,(d) NIN 的测试 ρ_2 值。
论文:DeepDefense: Training Deep Neural Networks with Improved Robustness

论文链接:https://arxiv.org/abs/1803.00404
摘要:尽管深度神经网络(DNNs)对于很多计算机视觉任务很有效,但很容易受到对抗性攻击,限制了其在安防系统的应用。最近工作已表明不可感知的扰动图像输入(即对抗样本)存在欺骗良好训练的 DNN 模型做出任意预测的可能性。为解决这一问题,我们提出了一个名为 DeepDefense 的训练方案,其核心思想是把基于对抗性扰动的正则化项整合进分类目标函数,从而使模型可以学习直接而精确地防御对抗性攻击。整个优化问题可以按训练递归网络的方式得到解决。实验结果表明我们的方法在不同数据集(包含 MNIST、CIFAR-10 和 ImageNet)和 DNN 架构上明显优于当前最佳方法。我们将很快公开发布再现这一结果的代码和模型。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com

