CIKM21 | 淘宝多场景推荐排序模型ZEUS

本文介绍大搜索算法团队发表于CIKM 2021 的论文 Self-Supervised Learning on Users' Spontaneous Behaviors for Multi-Scenario Ranking in E-commerce。论文中提出了多场景推荐排序模型ZEUS (Zoo of ranking modEls for mUltiple Scenarios),基于用户主动行为预训练,解决推荐反馈闭环、小场景和新场景训练数据不足、多场景排序模型联合学习等问题,在电商搜索多个推荐场景将CTR、CVR、GMV平均提升了6.0%、9.7%、11.7%。

▐ 电商搜索导购与增长
电商搜索全域多场景Query推荐,包括首页底纹、搜索发现、频道页搜索发现、大促会场、联盟APP、特价版等多个场景。其中频道主要包括聚划算、百亿补贴、红包等。
例如,如下图所示:Scenario 1为底纹场景,用户进入APP后,首页搜索框默认推荐出query;Scenario 2为频道页搜索发现,用户进入频道页,点击搜索框时,会自动显示多个推荐的query,引导用户点击;Scenario 3为联盟APP场景,比如用户从其他APP(例如抖音)点击链接进入电商APP后,我们会在合适的时机推荐一个query,进入搜索页面;Scenario 4为特价版场景。
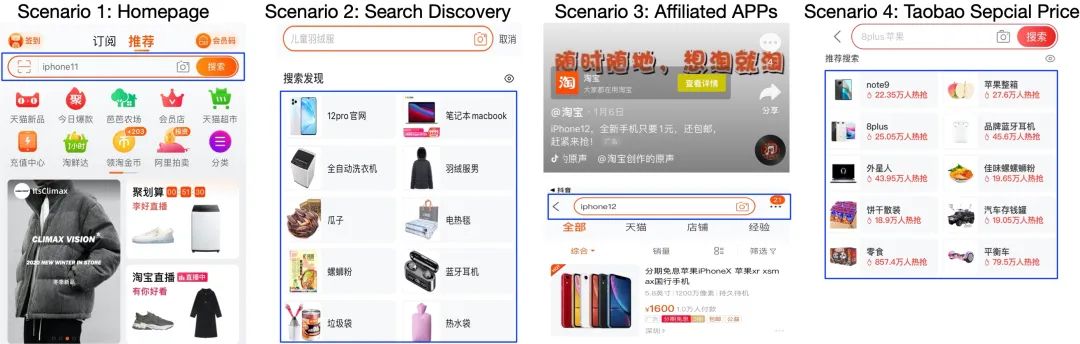
我们的工作是提出多场景Query推荐排序模型ZEUS(Zoo of ranking modEls for mUltiple Scenarios),同时提升多场景Query推荐的效率(例如搜索UV,购买UV,GMV等)。
▐ 多场景Query推荐排序模型的挑战
反馈闭环问题。搜索推荐广告中的排序模型,一般基于用户的隐式反馈 (implicit feedback)来训练: 模型上线后,推荐给用户多个item,然后用户会有点击或不点击这些item的反馈行为。通常我们将点击item作为正样本、未点击item作为负样本,来训练新的模型上线。这种偏向效率的训练方式,会导致排序系统展示出来的item通常具有高频的特点,很多长尾的item没有曝光的机会,马太效应严重,不利于生态的长期健康成长。
小场景和新场景训练数据不足。多个Query推荐场景中,很多场景属于小场景(例如频道页)、新场景(例如双11互动城活动),这些场景训练数据比较少,而排序模型参数量通常为千万级或亿级,直接用单个场景反馈数据训练,会导致过拟合问题,学习的模型效率较低。
多个场景联合学习。能否同时利用多个场景的数据,建模多个场景的共同点、不同点,提升多场景排序模型的效率呢?
深度学习排序模型DIN [1]、DIEN [2]、DMT [3]等,分别通过用attention, RNN, Transformer建模用户近期行为序列,取得了state-of-the-art的效果。例如,在淘宝搜索推荐商品排序中,采用Transformer建模用户行为序列,取得了很好的线上效果。
更多关于搜索推荐广告排序的模型介绍,请关注github:Awesome-Deep-Learning-Papers-for-Search-Recommendation-Advertising。
▐ 多场景排序模型
阿里巴巴AliExpress多场景搜索模型HMoE [4] ,阿里巴巴AliExpress多场景推荐模型SAML [5],阿里妈妈多场景广告排序模型STAR [6] ,这些优秀的工作关注于多个场景联合学习,能够通过建模多个场景的相同点、不同点,来优化多场景排序模型。这些方法基于多个场景的隐式反馈数据,我们的方法主要关注于如何借助用户主动行为数据进行预训练,来改进多场景排序模型的效率,和这些方法是正交互补的。
▐ Query推荐
淘宝搜索Query推荐模型,2018年从GBDT升级到MEIRec [7],2019年升级到FINN [8] 模型。
Query推荐和下拉推荐(Query Suggestion)不同,因为:下拉推荐需要用户先输入query前缀并且推荐出的query要满足前缀匹配,更像一个搜索问题;Query推荐是一个纯推荐问题,对推荐出的query没有额外要求。
▐ 自监督学习
Self-supervised Learning在NLP、CV领域取得了state-of-the-art的效果。例如NLP中,BERT [9] 和GPT [10]通过在海量无监督文本中预训练,在下游任务中取得了很好的效果;在CV中,SimSiam [11] 等自监督学习方法同样取得了很好的效果。基本思想是从海量无监督数据中,设计构造出监督任务,预训练模型,来改进后续监督任务的效果。
更多自监督学习的介绍,请关注微信公众号或知乎专栏“搜索推荐广告排序艺术”文章 自监督学习:人工智能的未来,github Awesome-Self-supervised-Learning-papers。
▐ 思想
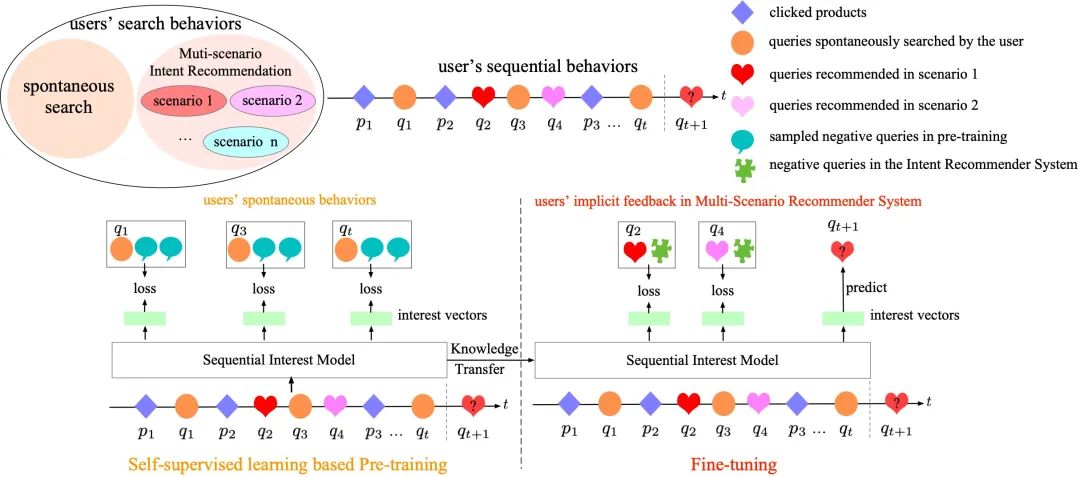
如下图右侧所示,已有的排序模型方法,利用implicit feedback反馈数据来训练排序模型 (Sequential Interest Model),输入的特征主要包括用户近期的行为序列。
自监督学习的核心思想,是从输入的一部分去预测剩余的部分。例如BERT在预训练阶段:通过Masked LM任务,从mask后的句子预测缺失的单词,预测被mask的单词;通过Next Sentence Prediction (NSP) 任务,预测是否是下一个句子。GPT基于language model预测下一个token。CV中预测图像被mask掉的部分,或预测图像旋转角度等。
将自监督学习应用到排序,自然的方法是,采取Pre-training和Fine-tuning两个阶段的方式,这两个阶段,都使用Sequential Interest Model来建模用户的行为序列。
在Pre-training阶段,如下图左侧所示,基于排序模型的输入(即用户行为序列),学习用一部分取预测剩余的部分,来完成对排序模型的预训练。我们设计的预训练任务是,类似GPT,基于用户历史行为,预测下一个用户主动输入的query,因为用户主动输入的query正是Query推荐排序模型理想的结果。例如在下图中,当用户在p1, q2, p3有行为后,分别预测用户接下来会主动输入q1, q3, qt。
在Fine-tuning阶段,如下图右侧所示,基于多场景Query推荐的implicit feedback反馈数据来fine-tune排序模型,得到多个场景的排序模型。例如在下图中,在用户在p2, q3有行为后,分别预测用户接下来会主动搜索q2, q4。
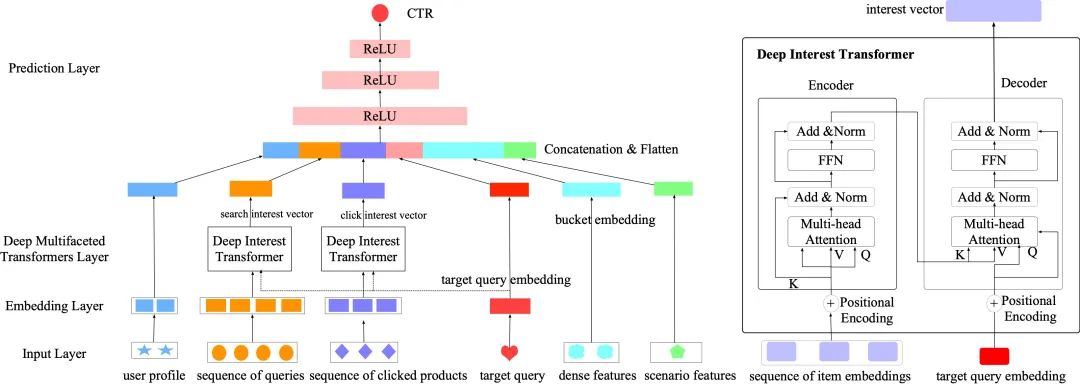
▐ Sequential Interest Model
在排序模型Sequential Interest Model中,输入包括用户画像, 用户的搜索query序列、点击商品序列,待排序query,线上原有模型(GBDT, FINN)使用的dense特征, 场景特征(场景名称等)。
对于序列建模,我们采取了stage-of-the-art的排序模型DMT中的方法,利用多个Transformer分别建模用户的搜索query序列、点击商品序列。对于每个行为序列,基于Transformer的Encoder的self-attention对序列建模,建模行为间的关联关系,然后再利用Decoder和待排序的query进行target attention,得到用户行为序列的兴趣向量。我们尝试了额外加入其他的序列,例如加购序列、购买序列,但是没有显著额外增益,因为这些行为相对比较稀少。
用户行为序列的兴趣向量和其他向量拼接后,通过MLP,预测出待排序query的CTR。
▐ Pre-training
在预训练阶段,借鉴BERT和GPT的思想,我们提出Next-Query Prediction (NQP)任务,来预训练排序模型Sequential Interest Model。
Next-Query Prediction (NQP) 任务
类似GPT,基于用户历史行为,预测下一个用户主动输入的query。
损失函数
在BERT和GPT中,采用softmax函数来计算要预测的token的概率分布,然后基于cross entropy计算损失函数,但是这种方式对搜索推荐广告排序并不适用。因为BERT和GPT中的token的词表大小仅分别有30,000和40,000,但搜索推荐广告要预测下一个item (query或商品)的词表大小通常是千万级或亿级。例如,在Query推荐场景,query的词表有2亿。
借鉴Contrastive Predicting Coding (CPC) [12] 的思想,可以采样一些负样本,基于InfoNCE loss来进行优化:

论文[14]指出InfoNCE loss可以用交叉熵损失函数来近似,我们实验中也发现了这种近似方法的有效性。
Hard Negative样本:简单地随机采样,会使得负样本过于简单,因此我们采样用户主动搜索query时曝光给用户但用户未点击的query作为hard negative examples。例如,用户在主动输入query时,下拉推荐会展示一些query给用户,我们把这些样本作为负样本。
讨论
我们采取的方法,和BERT和GPT对比,主要区别如下:
我们的模型和BERT、GPT参数量规模都是亿级,但我们的参数主要是embedding,BERT和GPT的参数量主要在超过12层的Transformer。因此BERT和GPT延迟会很高,无法直接应用到排序模型,而我们的模型线只有一层Transformer,线上排序仅需要25ms。
BERT和GPT需要输入数据组织成一个序列,而在排序模型中还有非序列的特征数据,例如用户画像、dense特征等。
BERT仅使用Transformer的encoder, GPT仅使用Transformer的decoder,而我们的模型同时使用了encoder和decoder,可以更好地建模历史行为序列和要预测的item的关系、建模多兴趣。
我们也尝试了CV中的Simsiam [11],在预训练阶段,加入额外的对比损失函数,但是没有带来额外增益。
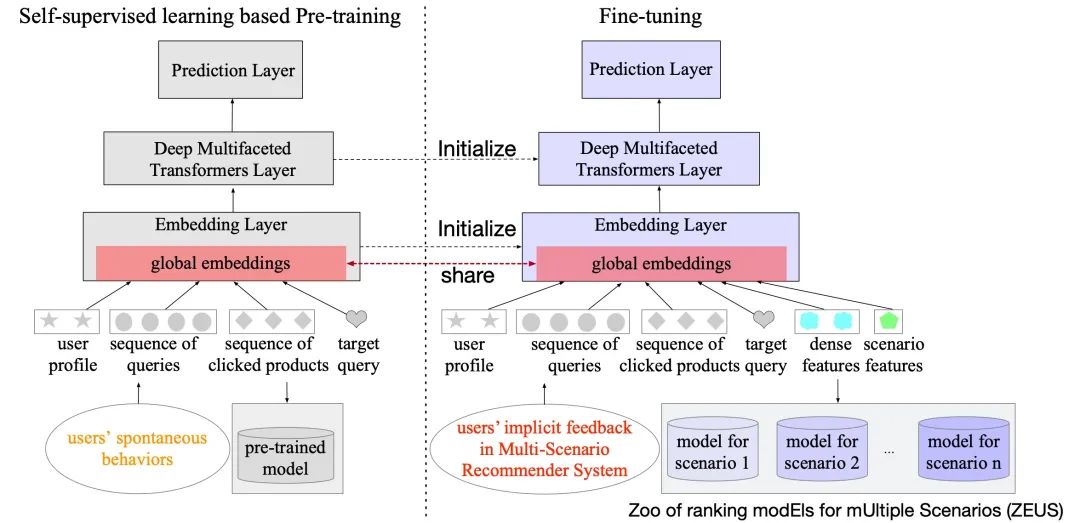
▐ Fine-tuning
在Fine-tuning阶段,可以将每个场景的排序模型学习看成BERT里的一种下游任务,直接用每个场景的隐式反馈数据fine-tuning,得到每个场景的排序模型。我们实验发现:在每个场景的隐式反馈数据fine-tuning之前,先使用所有场景的隐式反馈数据一起fine-tuning (即Multi-Scenario Fine-tuning),能取得更好的效果。
Fine-tuning阶段的具体操作如下:
加载预训练的排序模型后:
首先,同时使用多个Query推荐场景的implicit feeedback数据进行fine-tuning,来建模多个场景的共性,得到一个task-aware的排序模型,这个排序模型可以直接用到训练数据少的新场景或小场景。这个Multi-Scenario Fine-tuning的过程,也可以看成是基于多个场景Query推荐的反馈数据做任务导向的预训练。
然后,使用每个Query推荐场景的implicit feeedback数据对task-aware的排序模型继续fine-tuning,来建模每个场景的特点,得到每个场景的排序模型。
需要说明的是,由于预训练阶段没有dense features和scenario features,因此Prediction Layer的输入维度不同,所以Prediction Layer的参数没有共享,两个阶段共享的是embedding layer和Transformer序列模型的部分。这样可以共享底层表示和序列建模部分。
我们实验发现fine-tuning阶段固定住query和item embedding时,效果最好,因为这两个embedding参数量为亿级,训练数据不充分时容易过拟合。
因此,多个场景的Query推荐模型,使用这些共享的embedding参数以及联合训练来建模多个场景的共性,同时使用其他不同的参数来建模多个场景的不同点。
▐ 系统架构
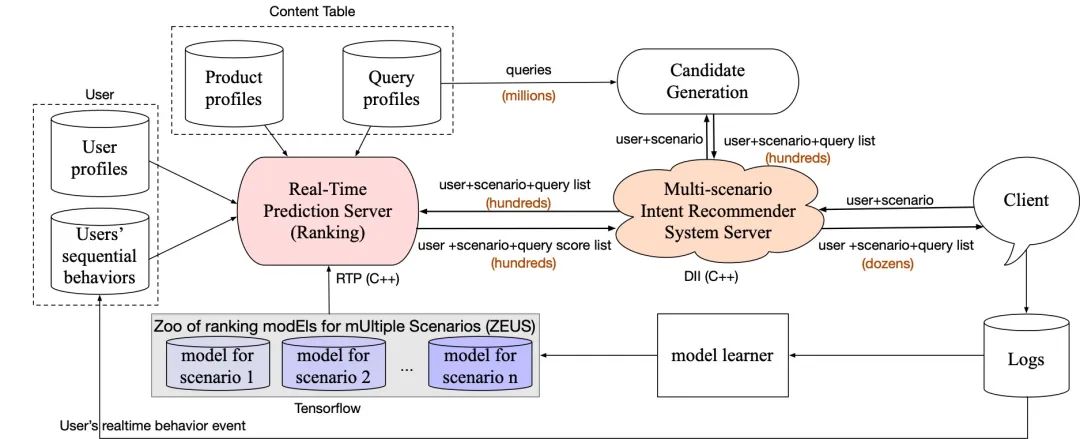
线上系统的架构如下图所示,在用户进入电商某个Query推荐场景时,客户端会将用户、场景信息传送到多场景Query推荐服务器 (通过DII实现),然后调用召回模块(例如基于用户点击商品、搜索query分别进行i2q, q2q召回),得到几百个query,再调用RTP模块对这些召回的query进行打分,RTP找到这个场景的排序模型进行打分,然后将得分高的query返回给客户端。
在实际部署时,多个场景的Query推荐模型部署到同一台物理机上,它们共享内存中加载的内容表(包括query和商品画像信息)。
▐ Dataset
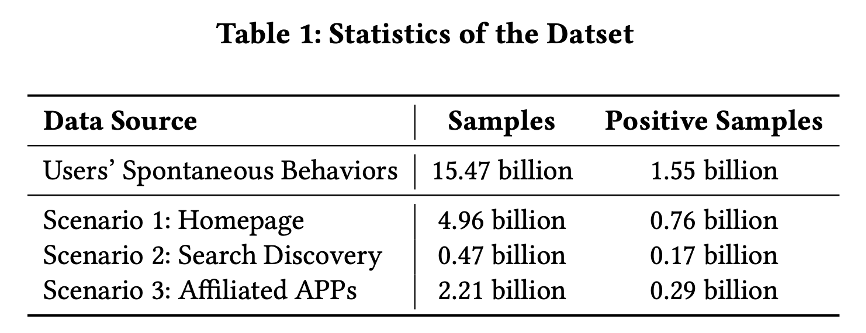
线上我们收集了Query推荐模型在场景1(底纹),场景2(搜索发现),场景3(联盟APP)一个月的训练数据。同时,收集了用户主动在搜索框输入query的数据。统计数据如下表所示。
▐ Baselines
Baseline选取了搜索线上Query推荐用的GBDT、FINN,以及Youtube DNN,DMT模型。
▐ 实验结果
和Baselines对比
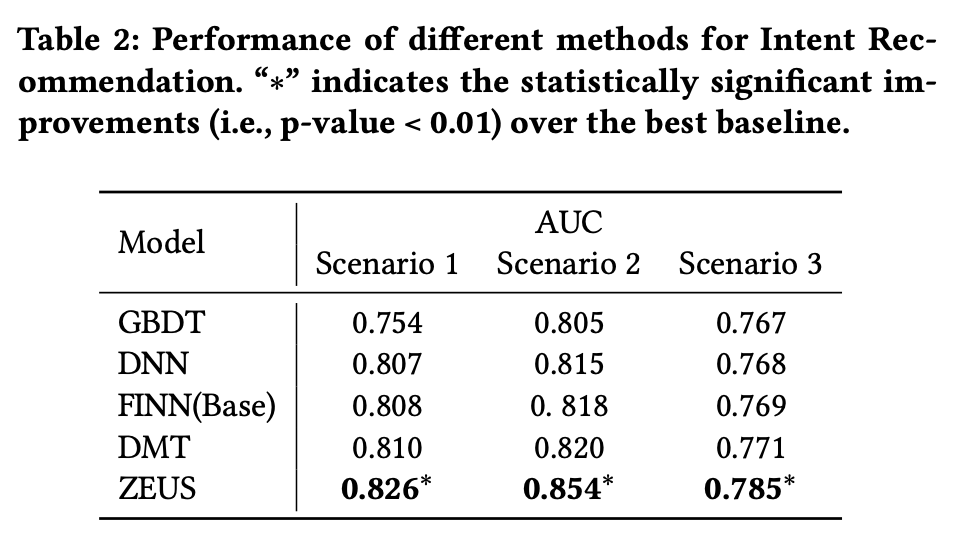
和Baselines对比结果如下表所示,可以看出:ZEUS比其他方法,都取得了明显的提升。其中ZEUS和DMT的区别在于,是否加入了Pre-training,从中可以看出:预训练对于效果提升有非常重要的作用。
Ablation Study
行为序列类型
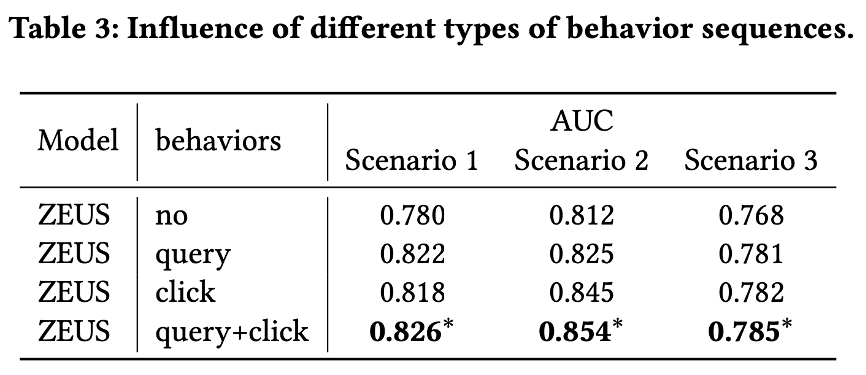
不同行为序列的影响如下表所示,可以看出:单独的搜索query序列、商品点击序列都有明显的作用,两种序列行为联合起来使用能取得更好的效果。
预训练
我们分析了是否使用预训练 (下表第二列)对模型效果的影响,如下表所示。可以看出:使用预训练能显著能提升模型的效果。
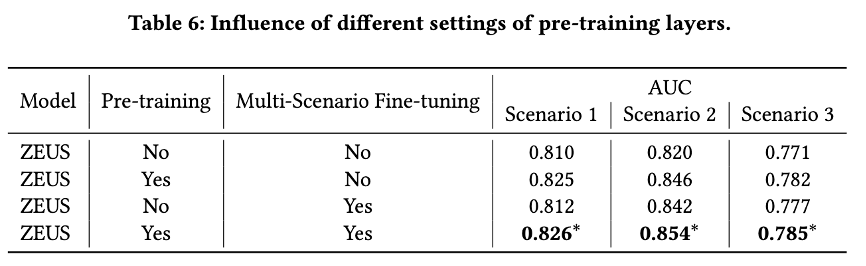
Multi-Scenario Fine-tuning
我们分析了在Fine-tuning阶段是否使用Multi-Scenario Fine-tuning(即在Fine-tuning阶段先使用Multi-Scenario的数据Fine-tuning) (上表第三列),对模型效果的影响,如上表所示。可以看出:使用Multi-Scenario Fine-tuning,建模多个场景的共性,能提升模型在各场景的效果。
Scenario-specific Fine-tuning
我们分析了在Fine-tuning阶段是否使用每个场景的数据分别fine-tuning (即Scenario-specific Fine-tuning), 实验结果显示:使用Scenario-specific Fine-tuning, 在底纹、搜索发现、联盟APP场景,离线AUC的绝对数值分别提升0.4%,0.6%,0.7%。这说明,使用Scenario-specific Fine-tuning,建模各个场景的特点,能提升模型在各场景的效果。
ZEUS模型在多个场景的线上效果如下表所示,其中Scenario 1为底纹,Scenario 2为搜索发现,Scenario 3为联盟APP,Scenario 4为特价版。其中对于特价版这个新场景,我们没有使用训练数据,直接使用了其他多个Query推荐场景的反馈数据联合Fine-tuning得到的模型。UCTR指query的点击率。
从表中可以看出:对于大、中、小、新场景,ZEUS模型都能取得比原有线上大流量模型FINN更好的效果。例如对于底纹场景,FINN比GBDT提升了+1.9%,没有预训练的DMT比FINN提升了+3.6%,ZEUS模型比FINN的UCTR提升了+16.6%。
线上效果说明了预训练能够提升多个场景的Query推荐效率。
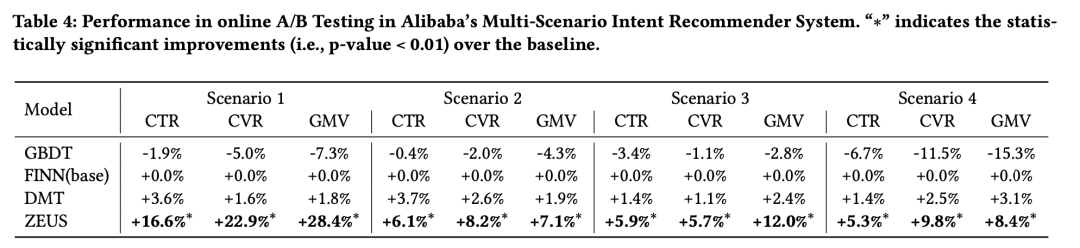
▐ 打破推荐闭环
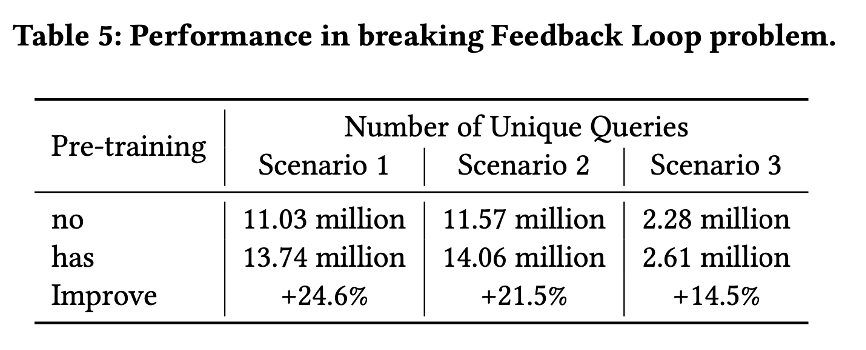
线上随机采样底纹场景的一个实例,如下图所示。
ZEUS模型根据用户的搜索query序列和点击商品序列,推荐出query "欧式针织毛衣"。
其中搜索query序列中“法式毛衣”和“针织毛衣”和推荐出的query相似度比较高,它们的attention分数也显著高;用户点击宝贝序列中,“针织裙子”和“欧式长款毛衣”和推荐出的query相似度比较高,它们的attention分数也显著高。
模型综合考虑用户的搜索query序列和点击商品序列,得出用户的主要兴趣是“毛衣”,同时她对“法式”,“欧式”,“针织”风格感兴趣,因此推出了query"欧式针织毛衣"。
可以看出,ZEUS模型有很好的推荐效果和对推荐结果的解释能力。

未来主要的优化方向有:
预训练:目前我们只是采用了简单的Next-Query Prediction任务来进行预训练。未来可以进一步设计新的预训练任务、对比损失函数,来进一步提升预训练效果。
多场景联合学习:如何更好地利用多个场景的反馈数据,建模多个场景的相同点、不同点,值得更深入的研究和尝试。
多目标优化:目前我们主要考虑优化推荐query的CTR,更好地实现query点击、引导商品点击、引导商品购买、GMV等多个目标优化,也值得进一步深入研究。
[1] Zhou, Guorui, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. "Deep interest network for click-through rate prediction." In KDD'18.
[2] Zhou, Guorui, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. "Deep interest evolution network for click-through rate prediction." In AAAI'19.
[3] Gu, Yulong, Zhuoye Ding, Shuaiqiang Wang, Lixin Zou, Yiding Liu, and Dawei Yin. "Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender Systems." In CIKM'20.
[4] Li, Pengcheng, Runze Li, Qing Da, An-Xiang Zeng, and Lijun Zhang. "Improving Multi-Scenario Learning to Rank in E-commerce by Exploiting Task Relationships in the Label Space." In CIKM'20.
[5] Chen, Yuting, Yanshi Wang, Yabo Ni, An-Xiang Zeng, and Lanfen Lin. "Scenario-aware and Mutual-based approach for Multi-scenario Recommendation in E-Commerce." arXiv preprint arXiv:2012.08952 (2020).
[6] Sheng, Xiang-Rong, Liqin Zhao, Guorui Zhou, Xinyao Ding, Qiang Luo, Siran Yang, Jingshan Lv, Chi Zhang, and Xiaoqiang Zhu. "One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction." In CIKM'21.
[7] Fan, Shaohua, Junxiong Zhu, Xiaotian Han, Chuan Shi, Linmei Hu, Biyu Ma, and Yongliang Li. "Metapath-guided heterogeneous graph neural network for intent recommendation." In KDD'19.
[8] Yang, Yatao, Biyu Ma, Jun Tan, Hongbo Deng, Haikuan Huang, and Zibin Zheng. FINN: Feedback Interactive Neural Network for Intent Recommendation. In WWW’21.
[9] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[10] Radford, Alec, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. "Improving language understanding by generative pre-training." (2018).
[11] Chen, Xinlei, and Kaiming He. "Exploring Simple Siamese Representation Learning." arXiv preprint arXiv:2011.10566 (2020).
[12] Oord, Aaron van den, Yazhe Li, and Oriol Vinyals. "Representation learning with contrastive predictive coding." arXiv preprint arXiv:1807.03748 (2018).
[13] Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. "Distributed representations of words and phrases and their compositionality." arXiv preprint arXiv:1310.4546 (2013).
[14] Kun Zhou,Hui Wang,Wayne Xin Zhao,Yutao Zhu,Sirui Wang,Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In CIKM’20.
大淘宝大搜索算法团队,负责淘宝天猫搜索排序模型 (CTR/CVR)、排序机制、召回、相关性、用户增长和导购、知识图谱、图像搜索、视频直播搜索、商家风控等业务。
欢迎对我们团队感兴趣的人才,联系jingyao.gyl#alibaba-inc.com(发送邮件时,请把#改为@)。








