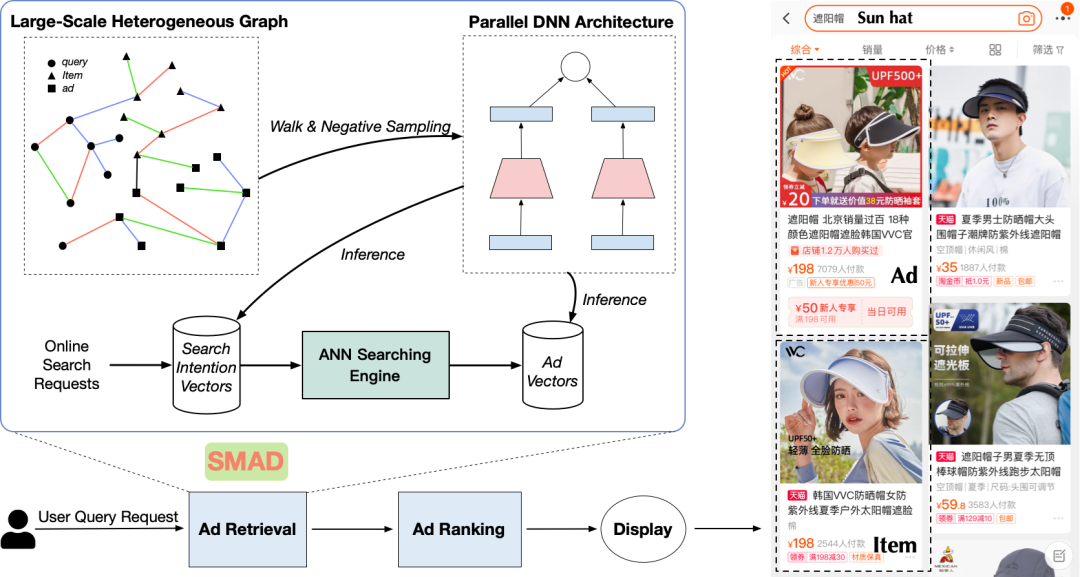
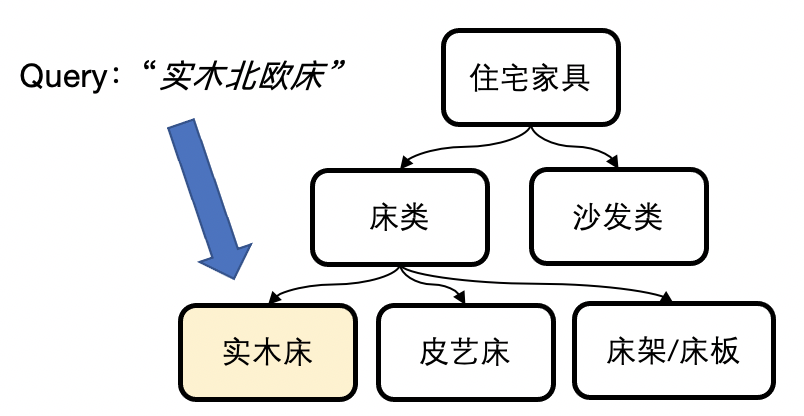
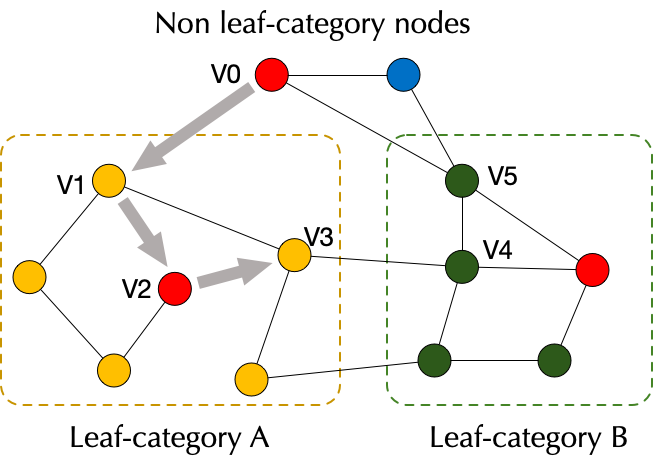
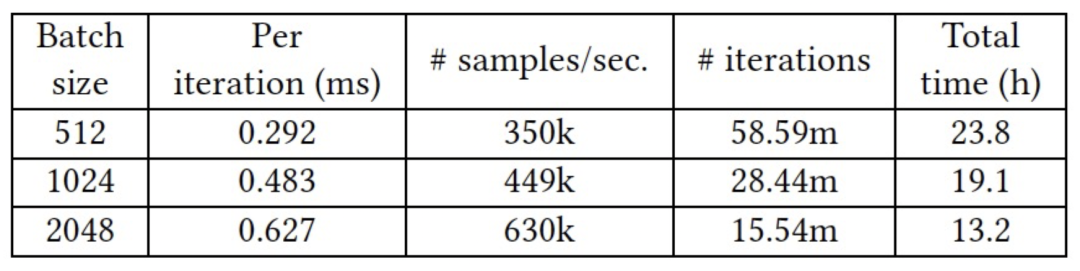
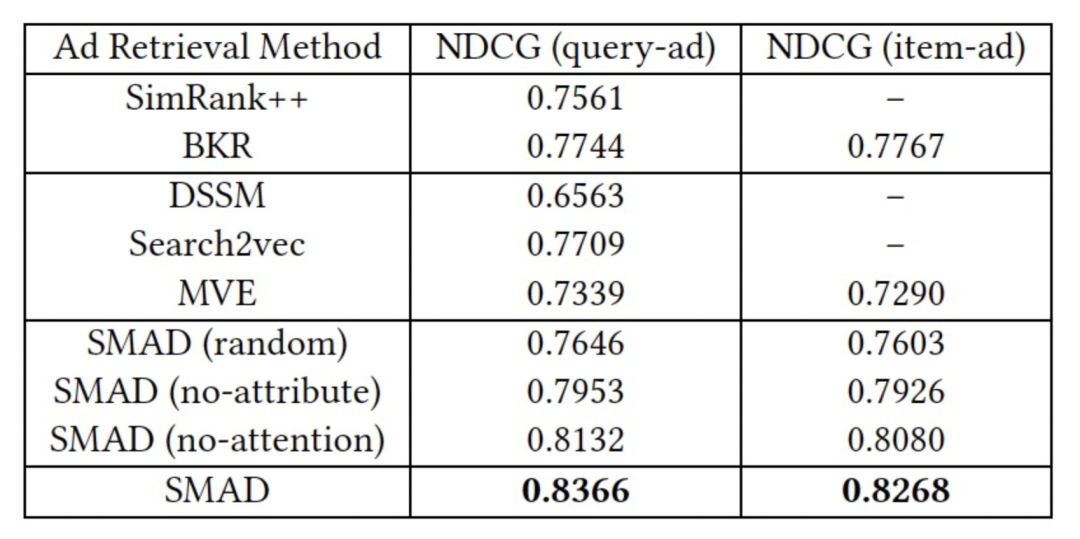
本文介绍了一种海量规模广告召回框架 SMAD,该框架将广告场景下用户行为抽象成图,并引入丰富的点边属性,通过衡量结构相似度,多视图建模相关性,从而实现 Query 和 Ad 的有效匹配。我们采用了一种基于搜索广告类目树结构的训练策略,并提出一种多视图网络模型汇聚 Query-Item-Ad 多维度异构关系和信息,在淘系十亿级别图数据上进行的离在线实验也充分证明了 SMAD 的有效性。
参考文献
[1] IoannisAntonellis,HectorGarciaMolina,andChiChaoChang.2008.Simrank++: query rewriting through link analysis of the click graph. Proceedings of the VLDB Endowment 1, 1 (2008), 408–421.
[2] Shaosheng Cao, Wei Lu, and Qiongkai Xu. 2016. Deep neural networks for learn- ing graph representations. In Thirtieth AAAI Conference on Artificial Intelligence.
[3] Yuxiao Dong, Nitesh V Chawla, and Ananthram Swami. 2017. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 135–144.
[4] MihajloGrbovic,NemanjaDjuric,VladanRadosavljevic,FabrizioSilvestri,Ri- cardo Baeza-Yates, Andrew Feng, Erik Ordentlich, Lee Yang, and Gavin Owens. 2016. Scalable semantic matching of queries to ads in sponsored search advertis- ing. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 375–384.
[5] Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 855–864.
[6] Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management. ACM, 2333–2338.
[7] BryanPerozzi,RamiAl-Rfou,andStevenSkiena.2014.Deepwalk:Onlinelearning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 701–710.
[8] Meng Qu, Jian Tang, Jingbo Shang, Xiang Ren, Ming Zhang, and Jiawei Han. 2017. An attention-based collaboration framework for multi-view network repre- sentation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. ACM, 1767–1776.
[9] JizheWang,PipeiHuang,HuanZhao,ZhiboZhang,BinqiangZhao,andDikLun Lee. 2018. Billion-scale commodity embedding for e-commerce recommendation in alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 839–848.
[10] SuYan,WeiLin,TianshuWu,DaoruiXiao,XuZheng,BoWu,andKaipengLiu. 2018. Beyond keywords and relevance: a personalized ad retrieval framework in e-commerce sponsored search. In Proceedings of the 2018 World Wide Web Conference. International World Wide Web Conferences Steering Committee, 1919–1928.
[11] Rex Ying, Ruining He, Kaifeng Chen, and Pong Eksombatchai. 2018. Graph Con- volutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM.