深度排序模型在淘宝直播的演进与应用
分享嘉宾:纪志辉 阿里巴巴 算法专家
编辑整理:李春雷
出品平台:DataFunTalk
DBMTL
DMR
RUI Ranking
总结
1. DBMTL1.0
淘宝直播深度排序模型应用的两个场景:
场景1:直播入口
打开淘宝的APP,在首页上会看到淘宝直播的宫格位,点进去就是淘宝直播的频道页,这是淘宝直播的主要入口之一,此外在“猜你喜欢”信息流、店铺页和商品详情页都可以看到淘宝直播的身影。
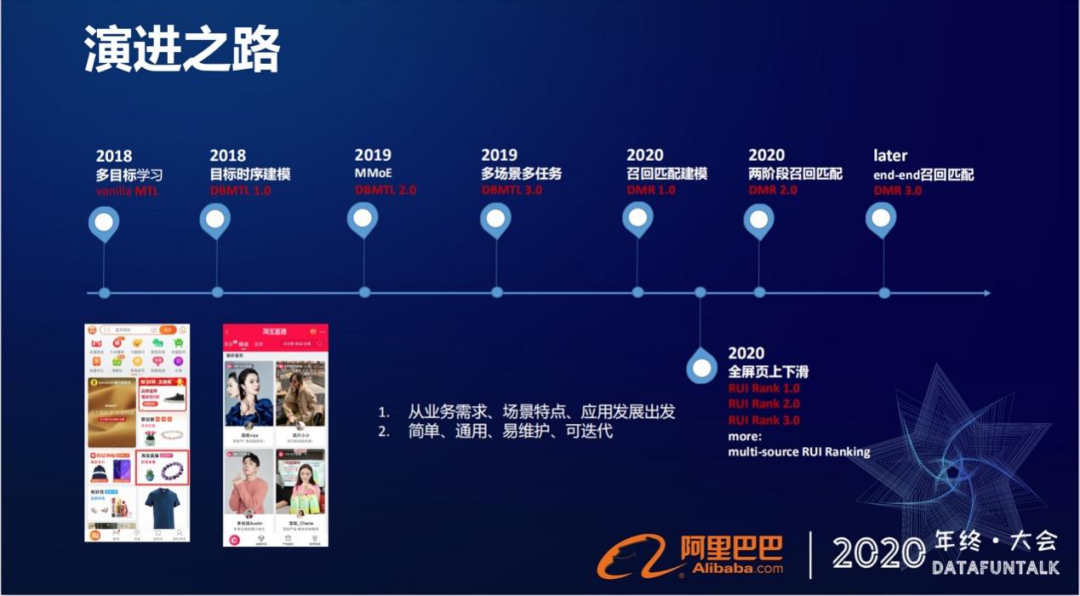
上图的时间轴,展示的是从2018年至今,淘宝直播做的排序优化工作。从2018年开始,我们就将排序模型升级到了原生的多目标学习框架MTL ( Multi-task Learning )。在2018年底我们基于目标持续建模,提出了自己的多目标学习框架DBMTL,2019年结合MMoE对框架进行升级,又做了多场景多任务的网络框架。今年围绕着召回匹配建模做了DMR架构,还做了两阶段召回匹配的模型,这些是我们在淘宝直播的列表页信息流下做的一些优化工作。
场景2:全屏页上下滑
另外还有一个场景,进入直播间之后,全屏页的上下滑,也做了一些工作。
① 背景/动机
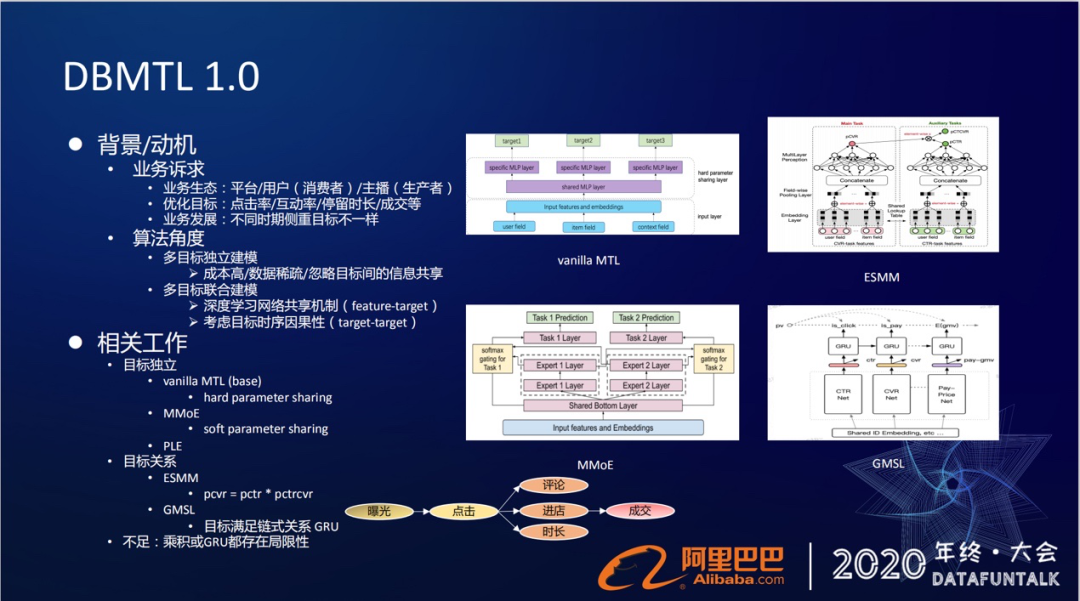
淘宝直播跟其他一些推荐场景其实是很相似的。我们的业务生态由平台、用户(消费者)和主播(生产者)组成,只是我们推荐的对象是主播。为了满足业务生态良性运转的需要,我们需要去满足消费者的体验,生产者的利益,证明平台的价值,放大在平台上的双边市场效应。
为了达到这个目的,我们需要去优化点击率/互动率/停留时长/成交等等各种各样的目标。另外,在业务发展的不同时期,侧重的目标也是不一样的。因此,对于算法而言,我们就需要有一套多目标优化的方案。
多目标优化有两套方案:
方案1:目标独立建模
为每个目标单独去建立一个模型,这种方案可能会面临着成本高的问题。另外有些目标会面临着数据稀疏的问题,更重要的是忽略了目标间之间的信息共享关系。比如一个5秒钟的点击和一个5分钟的点击,它带来这个效果是不一样的,如果能把这种时间上的信息作用到点击上,也是可以提升点击效果的。
方案2:多目标联合建模
用一个模型来同时优化多个目标,这种方案在我们深度学习网络里面其实是比较容易实现的。
通过深度学习的网络共享机制,可以实现目标之间的信息共享。我们也称为在feature-target,通过底层网络的信息共享来达到目标之间关系的刻画。
我们的目标都是通过用户行为来反馈标定的。而在推荐场景下,用户的行为有一定的时序关系,比如先有点击,再有点赞、评论等等其他互动行为,所以在做多目标联合建模的时候,也需要去考虑目标时序关系,也就是target-target层面。
② 相关工作
基于上面的考虑,业界有两种做法。一种做法是目标之间的独立性假设。没有刻画目标之间的联系,而是通过底层的共享机制来完成,像这种原生的Multi-task Learning也称为share-bottom 的这种方法。然后还有谷歌提出的MMoE的方法,腾讯提的这种PLE的方法。
另外一类做法是做建模目标关系,像阿里巴巴提出的ESMM,然后还有lazada提出的这种GMSL的模型。这四个图简单给大家介绍一下。
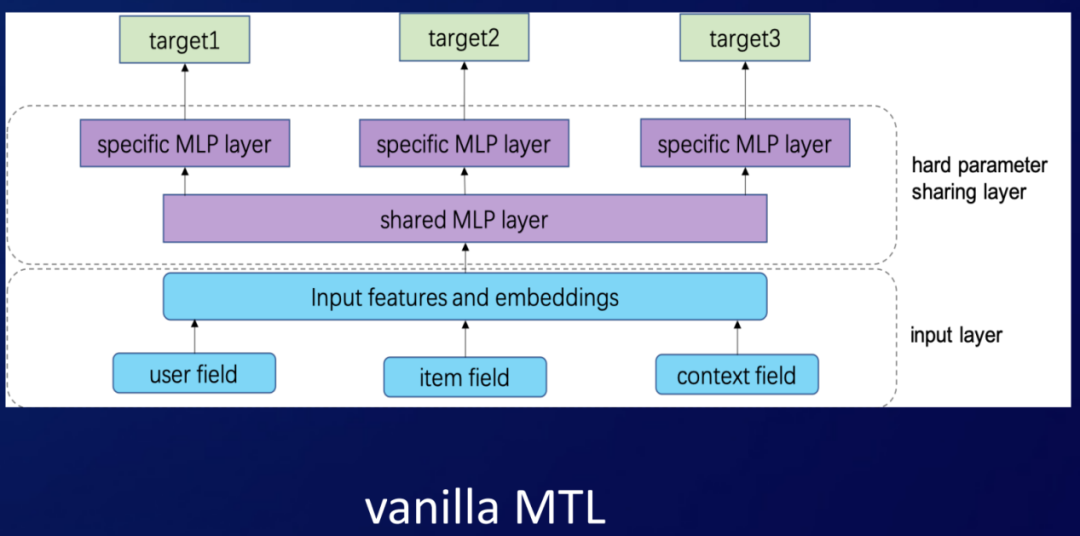
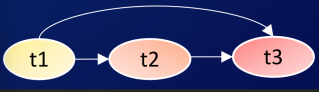
左上角这张图是原生Multi-task Learning,也是我们2018年升级之后的base模型。它是通过底层的共享网络来实现信息的迁移共享,每个目标之间共享share layer,然后在上层会有各自的specific layer,通过这种人为去定义哪些要共享,哪些不要共享的网络形式来实现信息的迁移。因为这种方式是通过人工方式来指定的,所以我们也称为hard parameter sharing的一个方法。
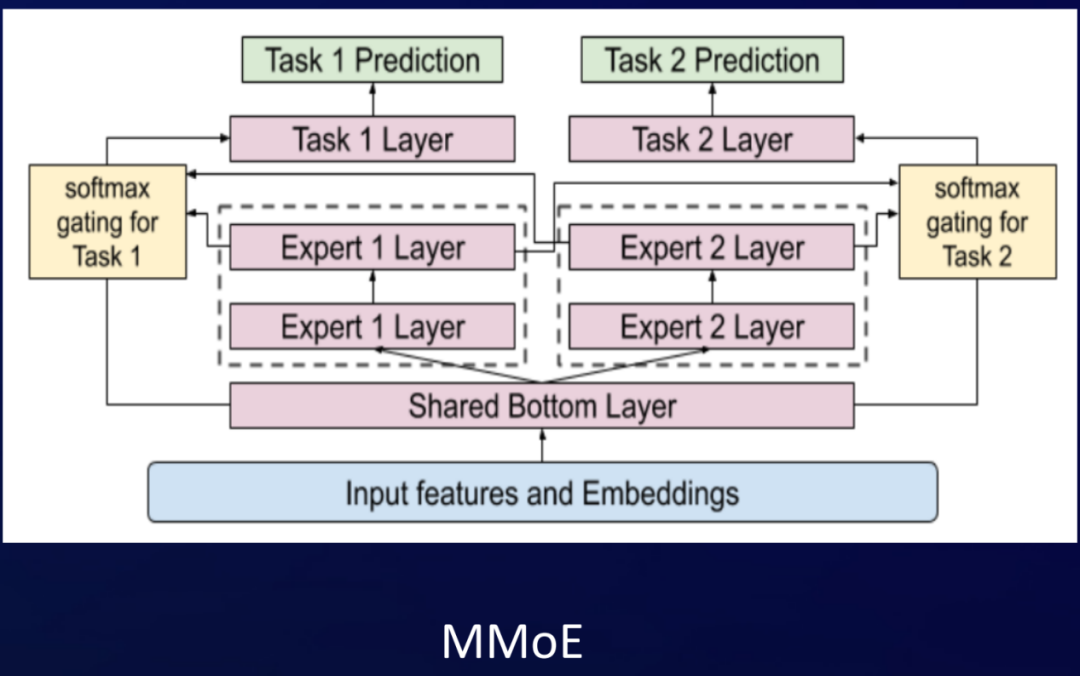
这张图是Google的MMoE,它是采用soft parameter sharing方法来实现。因为它通过定义多组的专家网络,每一个目标会在网络里自适应的学习,我们要选择哪一些专家网络来实现信息的共享,所以它会有一个门控的机制。通过这种门控来学习每个目标对每一个专家网络组的权重关系,实现底层特征的信息共享。
腾讯的PLE,认为MMoE是所有的专家组都是共享的,它没有每个目标自己的一个专家组网络,所以又提出了在每个目标都有一个Specific的Expert的优化方案。
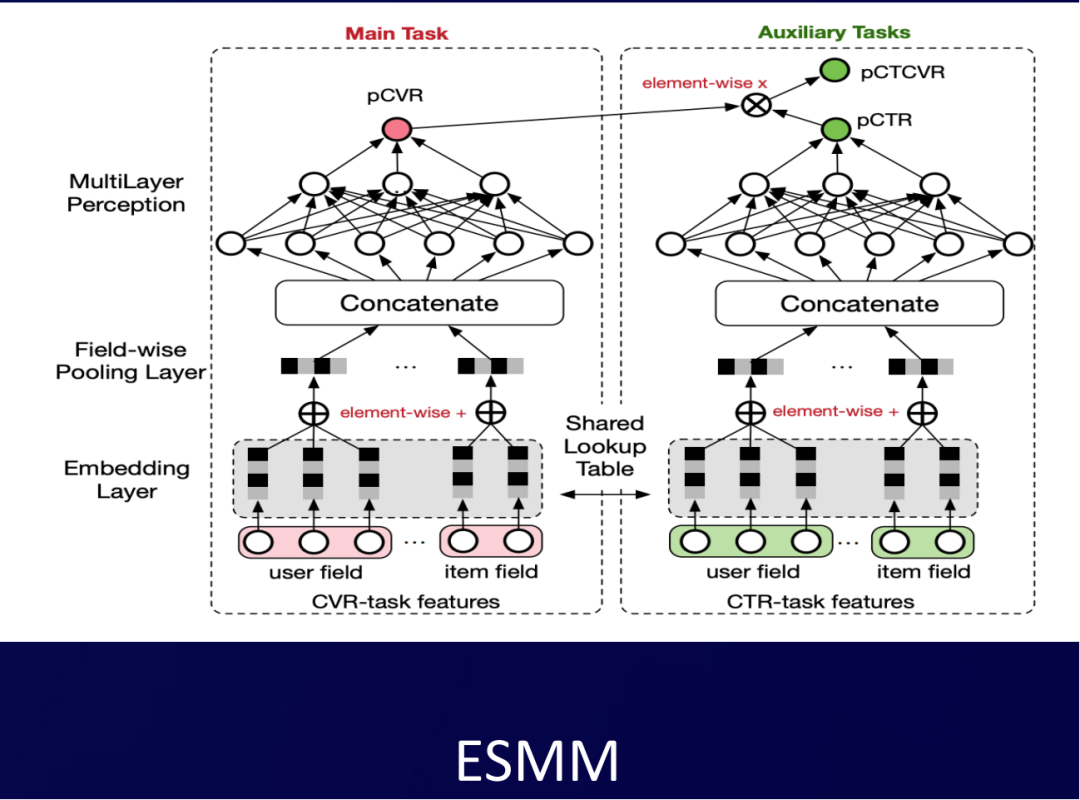
这张图是阿里巴巴的ESMM,它最初的一个目标是要去优化pCVR,然后通过引入pCVR=pCTR*pCTCVR这样的目标关系刻画,解决了样本选择空间偏差的问题,进一步优化pCVR。
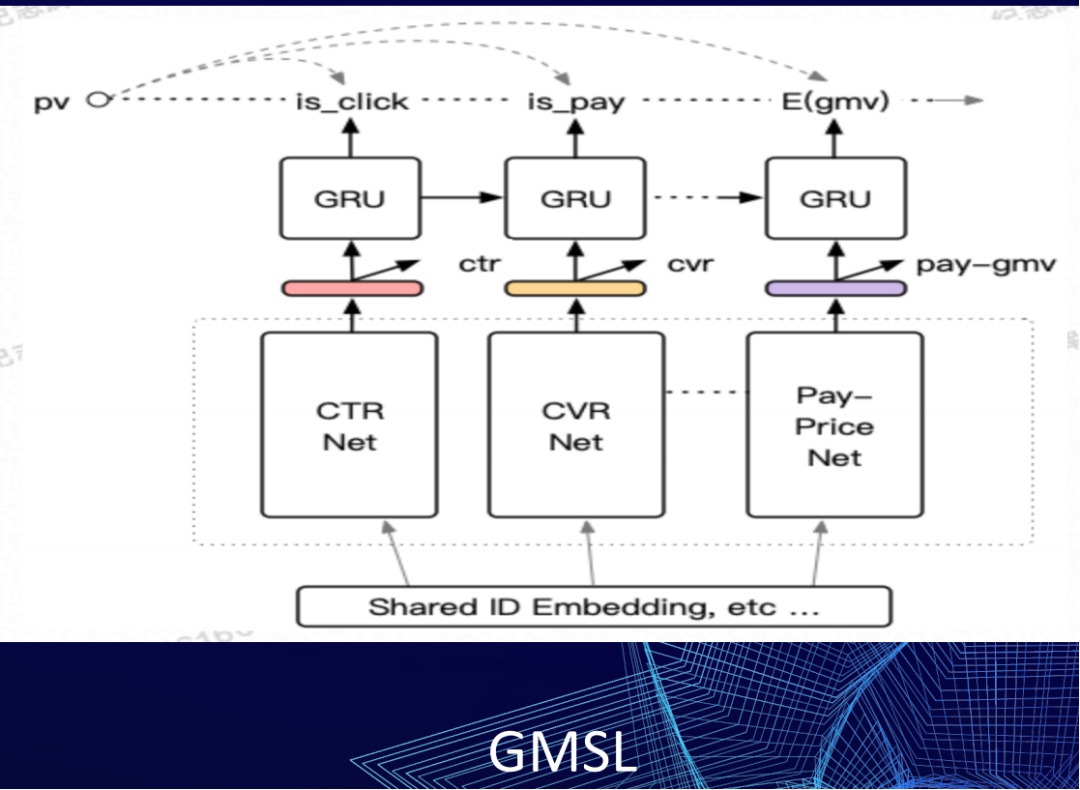
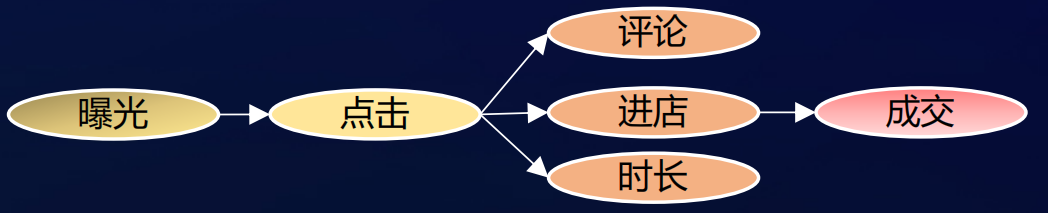
这张图是lazada提出的GMSL,它是通过GRU结构去优化目标之间的链式关系。无论是ESMM的这种乘积,还是GMSL这种GRU的结构,它都只能去刻画特定关系的目标。像下面的网络框架图(属于有向无环图),从点击到评论,点击到进店,到成交,然后到时长,这个相对比较复杂的贝叶斯网络,就没法很好的来满足目标的刻画。
③ DBMTL介绍
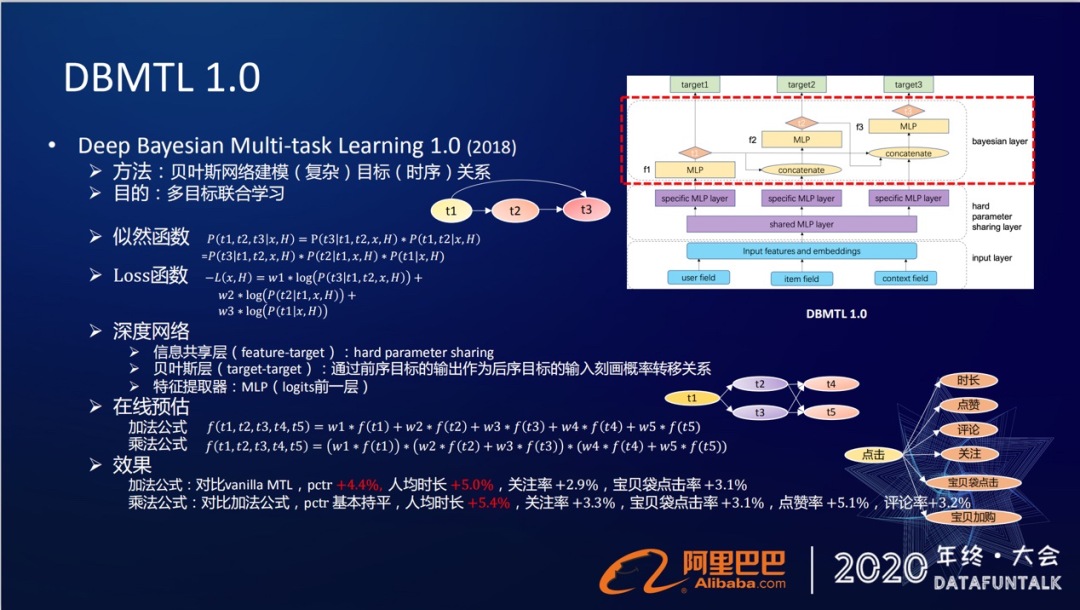
我们在贝叶斯网络的基础上,提出了自己的多目标学习框架DBMTL,全名是Deep Bayesian Multi-task Learning,就是通过贝叶斯网络来建模这种相对比较复杂的目标时序关系,目的是要达到多目标的联合建模。
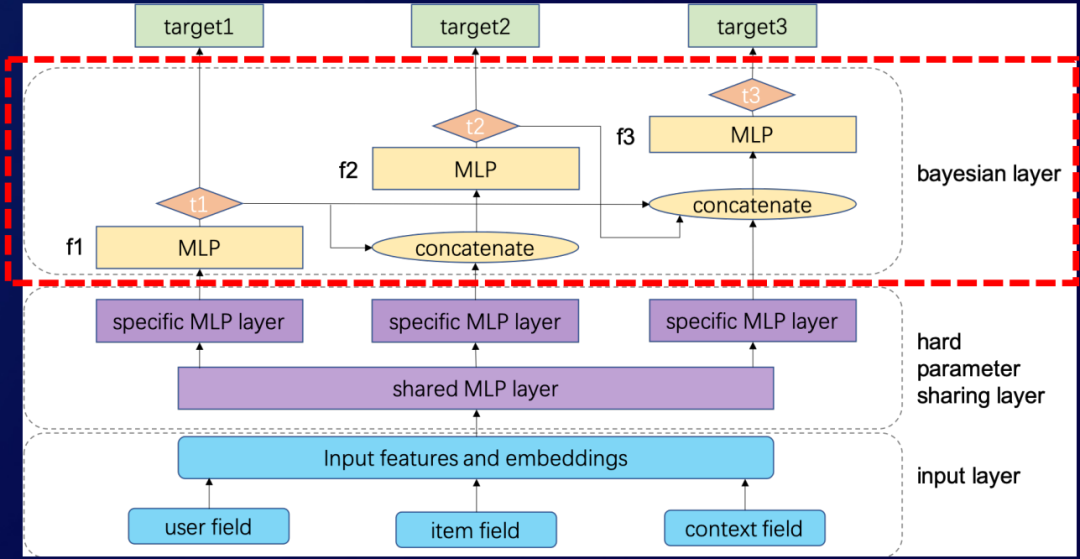
我们将目标稍微简化一下,假设现在我们有三个目标,t1,t2,t3,它们的关系满足t1到t2,t2到t3,然后t1到t3这样的关系。
在贝叶斯网络里面,它们的一个联合概率就可以表示为:
P(t1,t2,t3|x,H)=P(t3|t1,t2,x,H)*P(t1,t2|x,H)=P(t3|t1,t2,x,H)*P(t2|t1,x,H)*P(t1,x,H)
对应的损失函数,可以表示为:
-L(x,H)=w1*log(P(t3|t1,t2,x,H))+w2*log(P(t2|t1,x,H))+w3*log(P(t1|x,H))
这个公式在深度学习网络里面要怎么去刻画呢?在多目标优化的框架下,我们主要做了两点的优化。
第一点:底层信息的共享(feature-target层面)
由于是从原生的Multi-task Learning演化过来的,所以从一开始在信息共享层采用原来的hard parameter sharing的方法(也是share-bottom的这种方式)。
第二点:目标之间关系的刻画
贝叶斯关系的刻画是在target-target层。基本的原理是通过前序目标的输出作为后续目标的输入来刻画它们的转移关系,概率关系的刻画是通过一个简单的MLP(输出的Logits的前一层)来刻画的。
下面我们就对照着贝叶斯的公式和右边框架图,来过一遍目标关系是怎么来刻画的。
首先t1目标是没有前序目标的,所以它就是我们的feature-X,输入之后,通过一个网络层,然后经过MLP,得到t1的输出,然后t2目标的前序目标是t1,所以t1就会作为t2的输入,跟原来t2自身的特征做融合,然后过MLP得到t2。t3目标的前序目标是t1和t2,所以t1和t2会作为t3的输入,跟原来的X得到的特征融合到一起,然后过一个MLP,得到t3的目标。通过这样的网络关系来刻画了目标之间的贝叶斯网络关系,这是我们在训练阶段的网络模型。
④ 在线预估
在线预估的时候,会拿到每个目标的预估分数,然后去做融合,融合的方式有两种。
第一种:加法公式
这是一种最简单的方式,得到每一个目标的预估值之后,直接做线性的加权和,所以命名为加法公式。
第二种:乘法公式
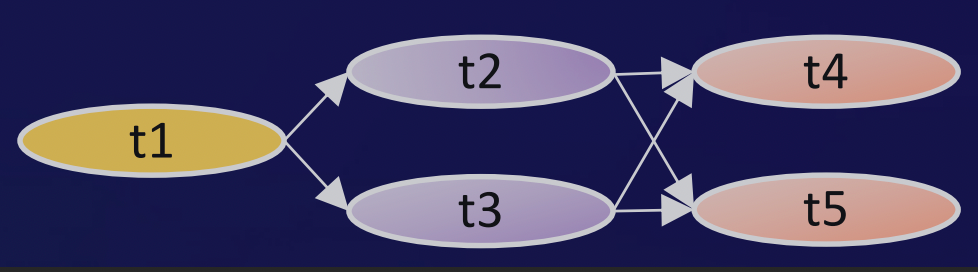
假设现在我们有另外5个目标,它满足的关系就是t1,t2,t3,t4,t5,t1指向t2、t3,然后另外两个会指向t4、t5。在这个网络关系下,我们就定义为网络的每一条边是一个乘积的关系。同一层网络之间是一个加法的关系,提出我们的乘法公式
f(t1,t2,t3,t4,t5)=(w1*f(t1))*(w2*f(t2)+w3*f(t3))*(w4*f(t4)+w5*f(t5))。
⑤ 效果
这套多目标框架也在我们的淘宝直播里面落地实验。最初的优化的目标是点击率到时长,点击率到点赞,到评论,到关注,到宝贝袋点击,到宝贝加购这几个目标。
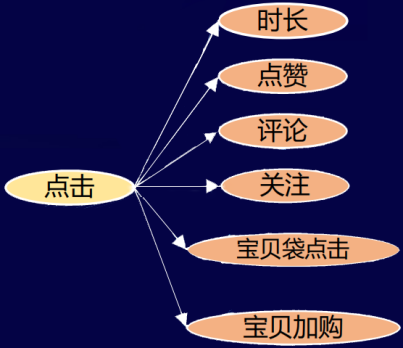
对于线上的效果,我们的加法公式对比原生的MTL(Multi-task Learning),在一跳的点击率和二跳的一些相关指标都有比较明显的效果提升:pctr +4.4%,人均时长 +5.0%,关注率 +2.9%,宝贝袋点击率 +3.1%。
乘法公式对比加法公式,在点击率基本持平的情况下,二条指标有了进一步的一个提升:人均时长 +5.4%,关注率+3.3%,宝贝袋点击率+3.1%,点赞率+5.1%,评论率+3.2%。
2. DBMTL2.0
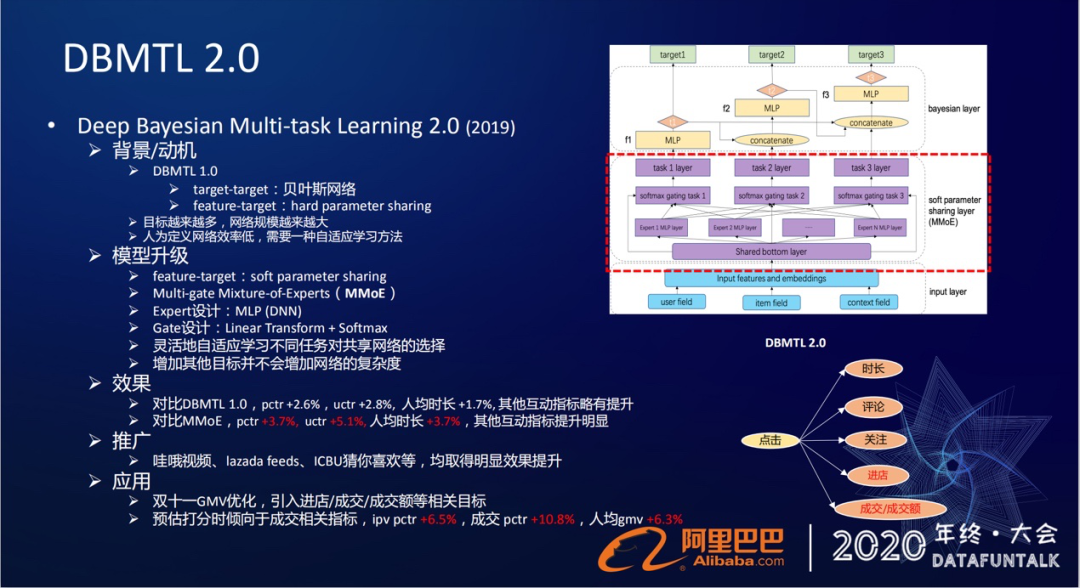
① 背景/动机
DBMTL1.0的优化。主要是通过贝叶斯层去刻画了目标与目标之间的时序关系,然后在信息共享Feature-target层,还是采用原来的这种hard parameter sharing的方法。这种底层特征的共享方法,在随着目标越来越多的情况下,网络规模就会越来越大。
另外人为的去定义网络效率相对比较低,所以我们需要一种自适应学习的方法。
② 模型升级
我们在2.0版本做了升级,引入了MMoE的soft parameter sharing方法。它的作用就是在信息共享层,将原来hard parameter sharing的share-bottom的方法替换为MMoE这种soft parameter sharing的方法。
先简单介绍下MMoE的原理,全称是多门混合专家网络组(Muti-gate Mixture-of-Experts),要定义多组的专家网络,它可以是简单的多组的DNN结构,需要为每个目标去选择属于它或者适合他的网络组,这就需要一个门控的机制。门控的机制就是通过我们的输入的feature通过线性映射,然后再过softmax就可以得到每一个目标。它在得到每一个专家网络组上面的权重,通过线性加权的方式,再得到各自目标的输出。
通过这种MMoE的方式就可以灵活的,自适应学习不同任务对共享网络的选择。另外增加其他目标也并不会增加网络的复杂度。
③ 效果
我们2.0版本同样也是在直播的信息流去做落地,对比1.0版本,点击率和时长都有一两个点的提升:pctr +2.6%,uctr+2.8%,人均时长+1.7%,其他互动指标略有提升。
虽然提升并不是特别大,但是如果把上面的贝叶斯层去掉,这个网络就是一个MMoE的网络了,对比MMoE在一跳的点击率和二跳的时长的提升都比较明显,pctr+3.7%,uctr+5.1%,人均时长 +3.7%,其他互动指标提升明显,这也进一步的验证了通过上层的贝叶斯网络去刻画目标关系的正确性。
④ 推广
这个网络框架,除了在我们淘宝直播落地之外,也在我们集团内的其他一些场景落地,像哇喔视频、lazada的feeds、ICBU猜你喜欢等等,也取得了明显的效果提升。
⑤ 应用
我们的多目标也要随着业务的发展去适应业务需求。在双十一的时候,我们就需要去优化GMV。所以在双十一的时候,我们也在多目标的框架的基础上引入了进店/成交额相关的指标。
在预估打分的时候,会更倾向于成交相关的一些指标,这种多目标优化在双十一的时候也取得了成交指标的明显提升:ipv pctr +6.5%,成交 pctr +10.8%,人均gmv +6.3%。
以上就是我们在多目标优化DBMTL框架下做的两点优化,一个就是在底层信息共享层MMoE替换原来的hard parameter sharing的方法,另外就是我们通过贝叶斯网络层去刻画目标之间的关系。
3. DBMTL3.0
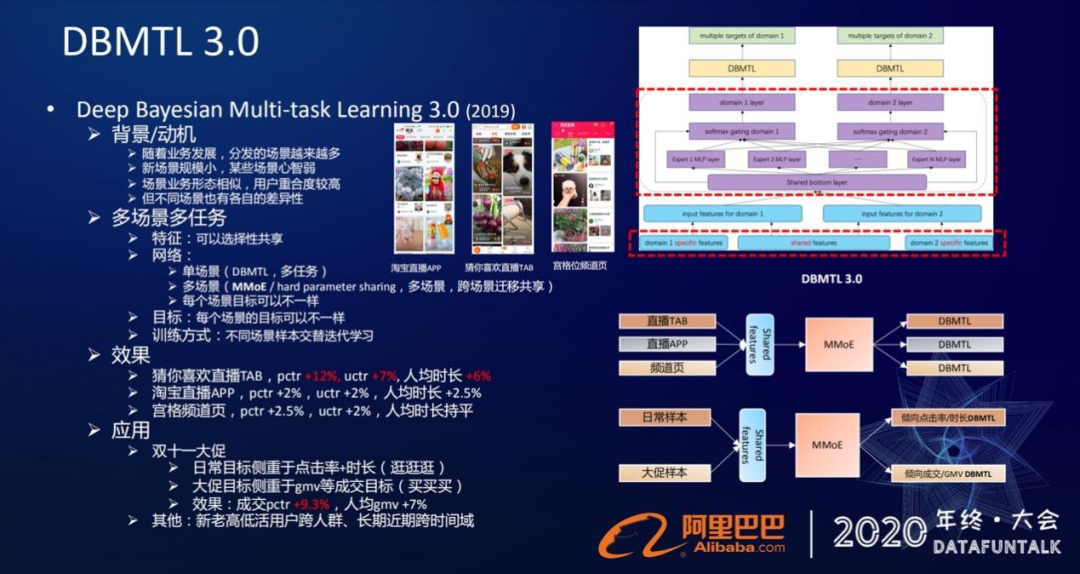
① 背景/动机
随着直播业务的发展,我们要分发的场景就越来越多包括:首页宫格的频道页,独立的淘宝直播的APP,猜你喜欢直播TAB (随着首页信息流改造,现在TAB已经不见了)。
在一些场景刚分发的时候,会面临着数据规模比较小,场景心智也会比较弱的问题。另外这些场景的业务形态都是比较相似的,都是在淘类里面去做导流,用户重合度也相对比较高,但是由于他们又在不同的渠道下去分发,所以每个场景又有各自的差异性。
② 多场景多任务框架
我们有这么多的场景和这么多的数据,怎么样去做信息的迁移和共享?用一个模型能不能把这些不同场景下的相同点和差异性给体现出来?
于是在3.0版本,我们就做了一个多场景多任务的框架:
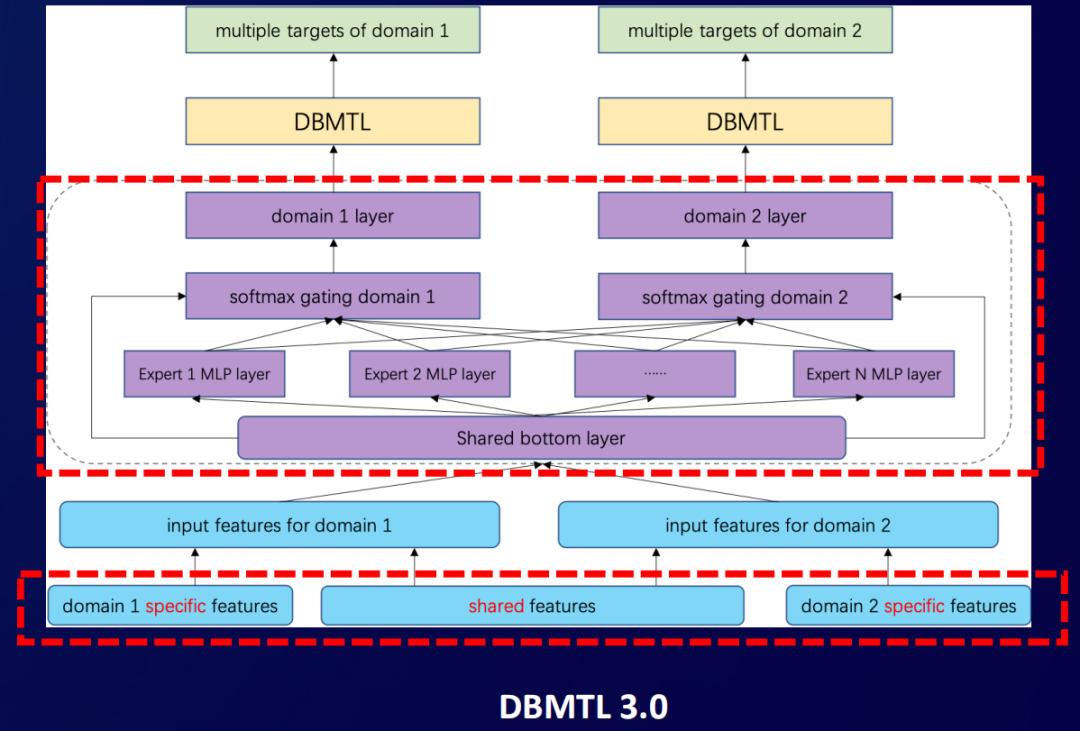
我们可以对照着框架图来解释一下:
首先是特征层面,我们现在有了三个场景的样本数据,在底层特征上面,每个场景有自己独特的特征,也可以将特征去做共享,所以特征之间是可以做选择性的共享的。
最上层的每一个场景内,依旧是一个多目标的框架,就是我们前面提到的DBMTL框架。
在中间层,我们就要去实现不同场景之间的底层网络信息的共享。我们还是采用了原来这种share-bottom的hard parameter sharing或者MMoE的方法来实现的。像这张框架图,它就是一个MMoE的实现,就跟之前的实现方式是一样的,只是说我们套用了从原来的多任务套用到现在的多场景而已。
通过这个实现方式,我们就实现了在底层做多场景特征网络共享,然后在各自场景里面同样是多目标的这种多场景多任务的框架。这样的框架怎么去做训练的呢?
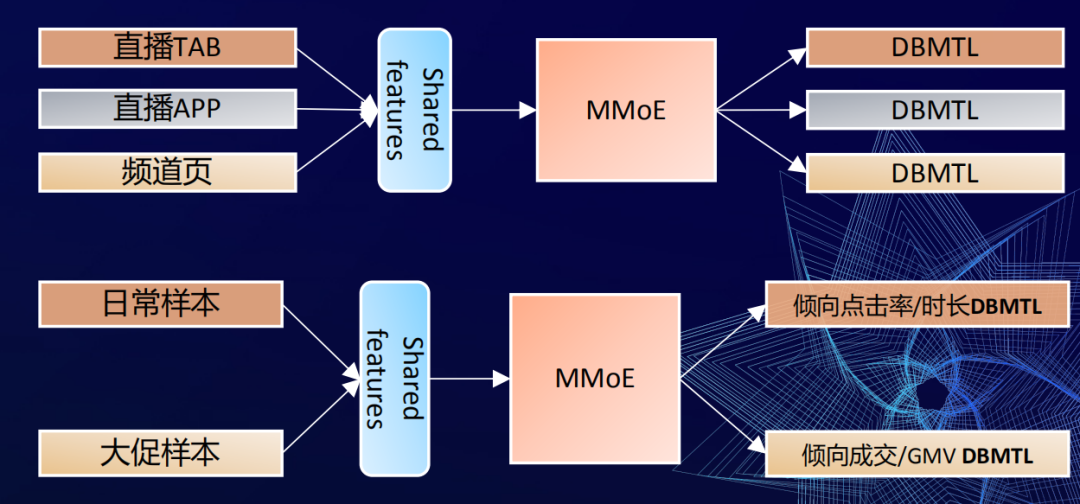
我们有3份样本,在每一个场景的样本里面,多个目标的loss做加权和迭代。在场景与场景之间,我们的方式是通过不同场景的样本去做交替迭代学习的,通过这种方式来更新模型。这个网络框架也在我们3个场景里面去落地,通过输入直播TAB的样本,直播APP的样本,频道页的样本,然后做特征的共享,过网络的共享,再到各自场景的多目标学习。而每个场景的目标侧重点是可以不一样的,根据场景的业务的需求去做差异性的定制。
③ 效果
这个框架也在3个场景里面落地实践,已经取得了明显正向的效果提升。
猜你喜欢直播TAB:pctr+12%,uctr+7%,人均时长+6%
淘宝直播APP:pctr+2%,uctr+2%,人均时长 +2.5%
宫格频道:pctr+2.5%,uctr+2%,人均时长持平)
尤其是在直播TAB这个场景下,效果提升非常明显(因为这不是一个有心智的入口,所以需要其他一些渠道的样本数据来补充和完善它的学习)。
④ 应用
这样的框架,也不仅仅只适合于有多个分发场景的业务,在很多地方都可以进行落地和应用,比如像双11大促的时候。
我们就将样本就切成两块,一块就是日常的样本,在日常场景里面,用户可能是来逛逛逛,所以优化侧重点击率+时长。另外一块是大促期间的样本,在双十一大促的时候大家会来这里买买买,所以双十一的样本我们会注重GMV等一些相关成交的目标优化。
通过这样将多场景多任务框架推广到双十一应用,我们也取得明显的提升,成交 pctr+9.3%,人均gmv+7%。
此外这个框架也可以在其他地方应用,比如新老用户/高低活用户,这种跨人群的信息的迁移学习,还有业务上的一些波动会导致长期样本和近期样本的分布的不一样,也可以去通过这个框架来去做跨时间域的迁移学习。
1. DMR1.0(Deep Match & Rank)
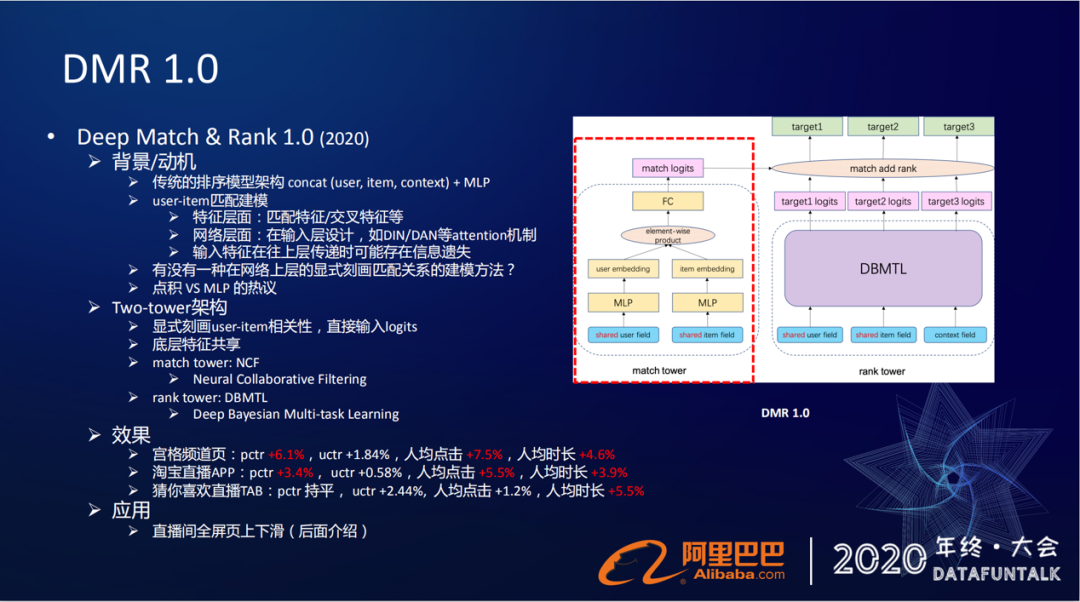
① 背景/动机
传统排序模型的架构下concat(user,item,context),然后再加MLP的架构。在这种架构下,如果要去显式的刻画user和item的匹配关系的话,一般会从特征层面去做匹配特征/交叉特征,在网络层面也会在输入层的时候,去做一些诸如DIN/DAN之类attention的机制。在底层刻画好的相关性的特征,在往上层传递的时候,可能会存在信息的遗失,有没有一种可以在网络上层直接显式刻画它们匹配关系的建模方法?
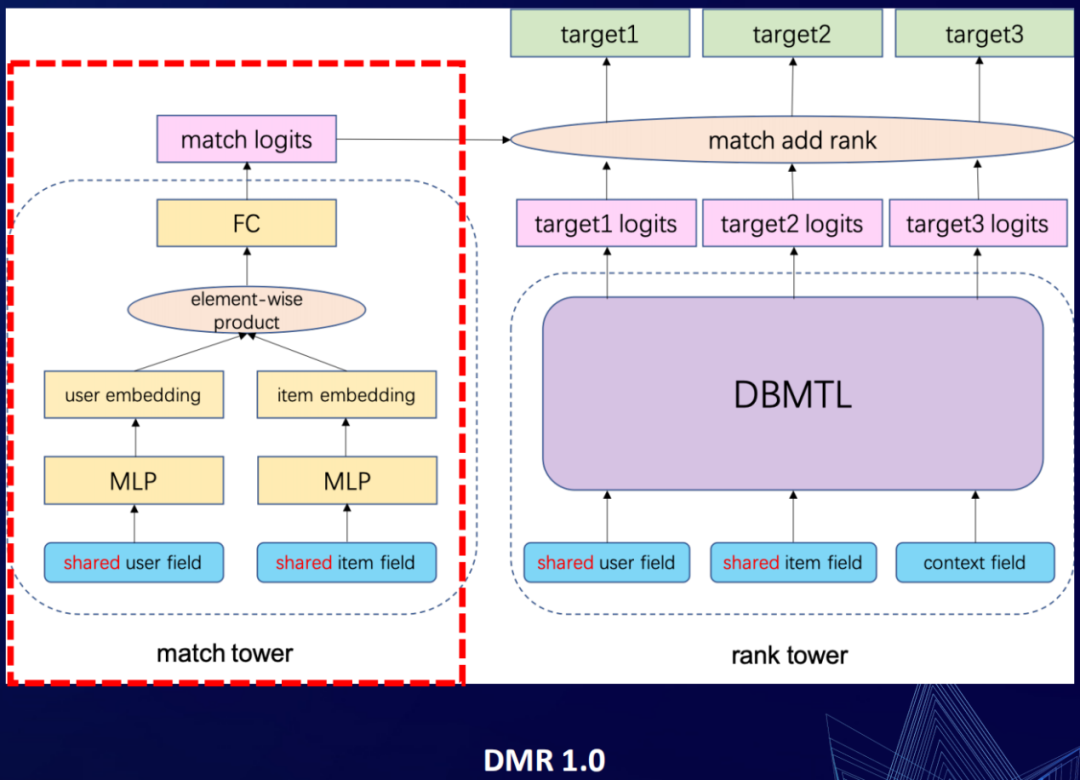
② Two-tower 架构
年初的时候有一篇关于“点积 vs MLP框架哪一种更适合推荐系统”文章的热议。我们从中得到了启发,在DMR里面做了一个双塔的架构。在原来的排序模型的框架下引入了一个新塔,称为match tower,原来的称为rank tower。这个match tower,就是一个点积的框架(一般粗排模型里面经常会用到这个框架)。通过这个match tower来显式刻画user和item的相关性,将user和item分别映射到的空间里面去,然后在这个空间里面去做点积的运算(也就是相似性的运算),然后过一个FC,然后得到match侧的logits,再跟原来我们rank侧得到的多目标的logits,直接做加法融合。
③ 效果
这个简单的双塔架构,也在我们直播的三个场景里面去落地实验,取得非常明显的效果提升。
宫格频道页:pctr+6.1%,uctr+1.84%,人均点击 +7.5%,人均时长 +4.6%
淘宝直播APP:pctr+3.4%,uctr+0.58%,人均点击 +5.5%,人均时长 +3.9%
猜你喜欢直播TAB:pctr 持平,uctr+2.44%,人均点击+1.2%,人均时长+5.5%
大家可能会对这里有所疑问,或者说质疑,我们也想过为什么这个东西引进来可以有这么大的效果提升?
我们觉得可能是因为底层特征关系的刻画做得还不够好,所以留给的网络空间就比较大,所在这个网络优化可以达到比较明显的效果,大家也可以去自己去实验一下这个框架。我们在后面的一个直播间全屏页的上下滑,也有不太一样的一个应用。
2. DMR2.0
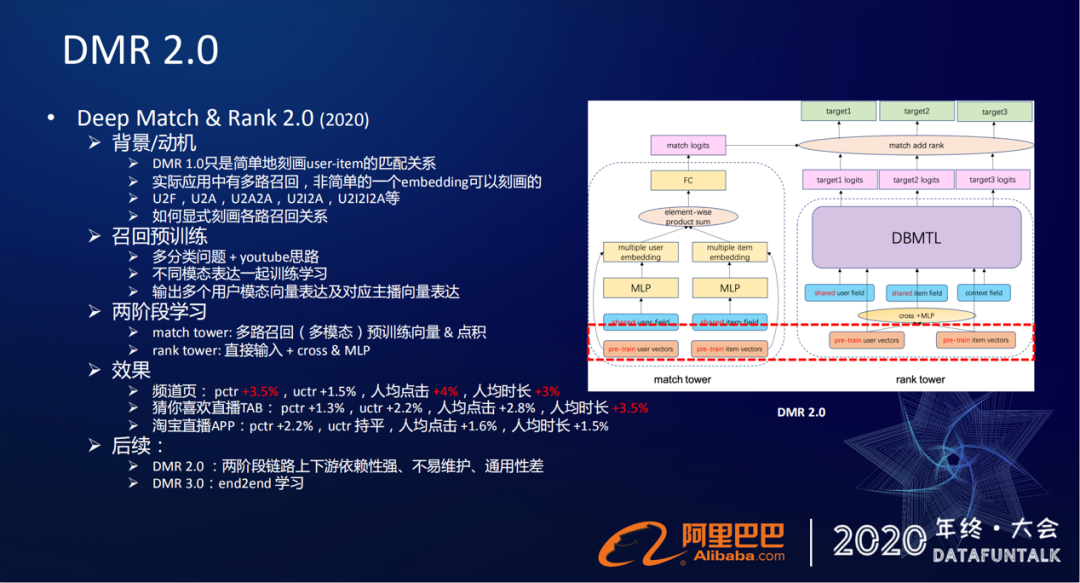
① 背景/动机
在1.0版本,只是通过简单的embedding刻画了user和item之间的匹配关系,实际上在直播的应用中是有多路的召回的。根据U2F(用户的关注关系)、U2A(用户的行为历史)、U2A2A(用户行为历史的协同),U2I2A(用户商品的历史),U2I2I2A(用户商品历史的协同)等等,在网络中怎么显式的把这些各路关系给表征出来呢?在我们2.0版本,我们采用了两阶段学习的方法。
② 召回预训练
首先通过一个召回模型,先去学习用户在不同的召回路数下的表征,然后拿到在不同召回/模态下的用户表征训练完的embedding,再拿到我们排序模型里面来作为feature进行进一步学习。
在召回的模型中,怎么来刻画用户多模态或者多路召回的表征呢?在这个模型下,我们的优化的问题就转化为用户在当前的模态下,预测下一个要给用户推荐什么?
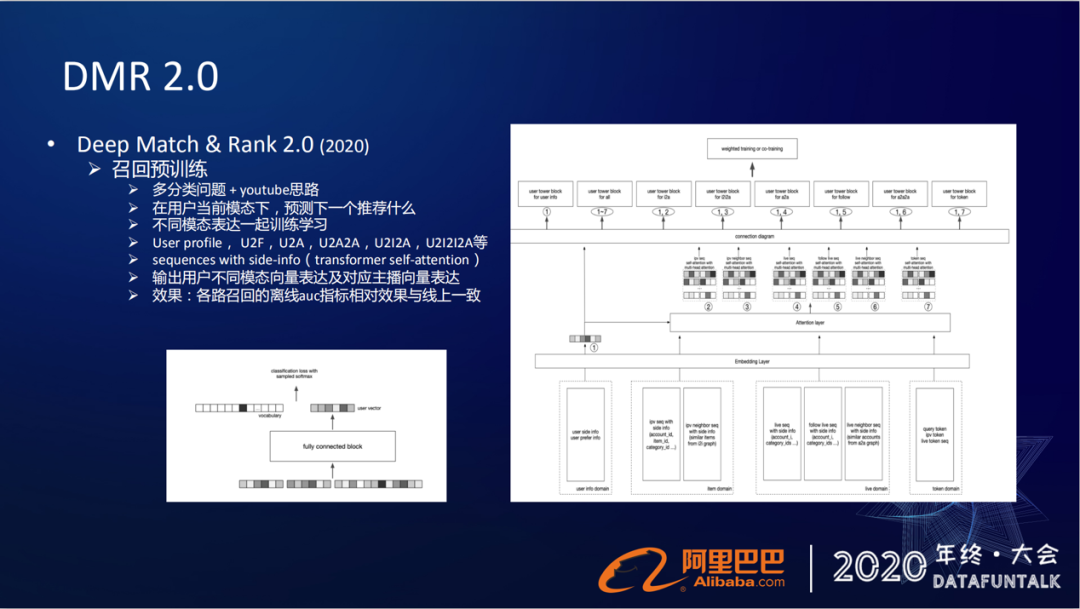
其实这就是一个多分类的问题,我们采用的也是youtube的那套召回模型的思路,把不同的模态表达放在一起去学习训练。我们输入的模态有下面几种,比如用户本自身的一些User profile(属性特征),还有U2F (用户的关注关系),还有U2A (用户的直播行为历史)、U2A2A (直播历史的协同)、U2I2A (商品历史),U2I2I2A (商品历史的协同)等。
这里要提一点的就是U2A2A,我们并不是在网络里面直接去学习A2A的这种协同关系,而是我们已经基于item CF得到了A2A的关系,通过U2A来join一个A2A这个操作来得到U2A2A这个用户的行为序列,每一个行为序列我们都也会把它带上相应的side-information(主播侧的信息)。
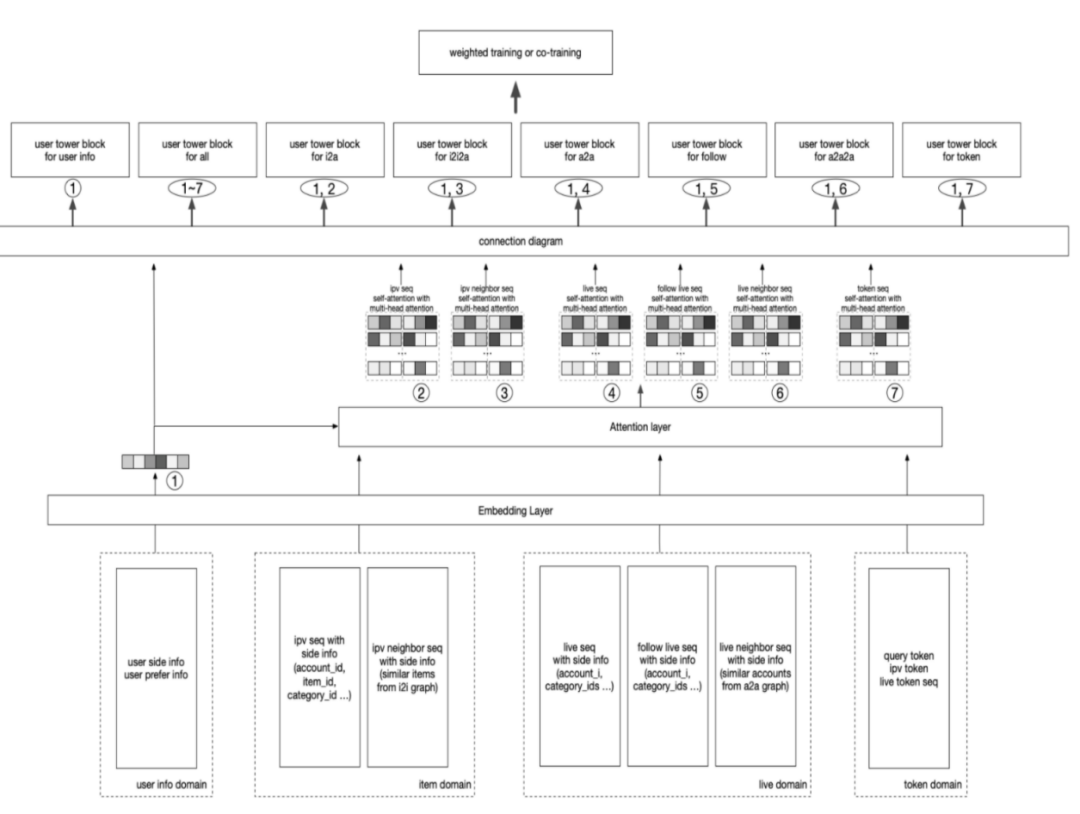
在这个框架图底层就是用户的输入的各个模态下的序列,每个序列会带上它的一些side-information,这些序列再往上层走的时候,会过一个基于transformer的share attention的特征抽取,然后再往上层才得到用户在不同召回模态下的表征。
得到这些表征之后,就要去预估在这个表征下应该给用户推荐哪一个主播。在上层的这个损失函数上,我们将多个模态的损失函数,做线性加权,通过得到最终的loss,然后去做模型的迭代。
通过这个模型,我们最终就可以得到用户在不同模态下的向量表达,以及它对应的主播向量的表达。这个模型也做了离线效果的刻画,各路召回的离线auc指标的相对效果跟我们线上是一致的。
我们拿到了这个用户在不同模态/召回域下的向量表达,以及对应的主播向量表达,就要喂到前面的DMR网络架构里。
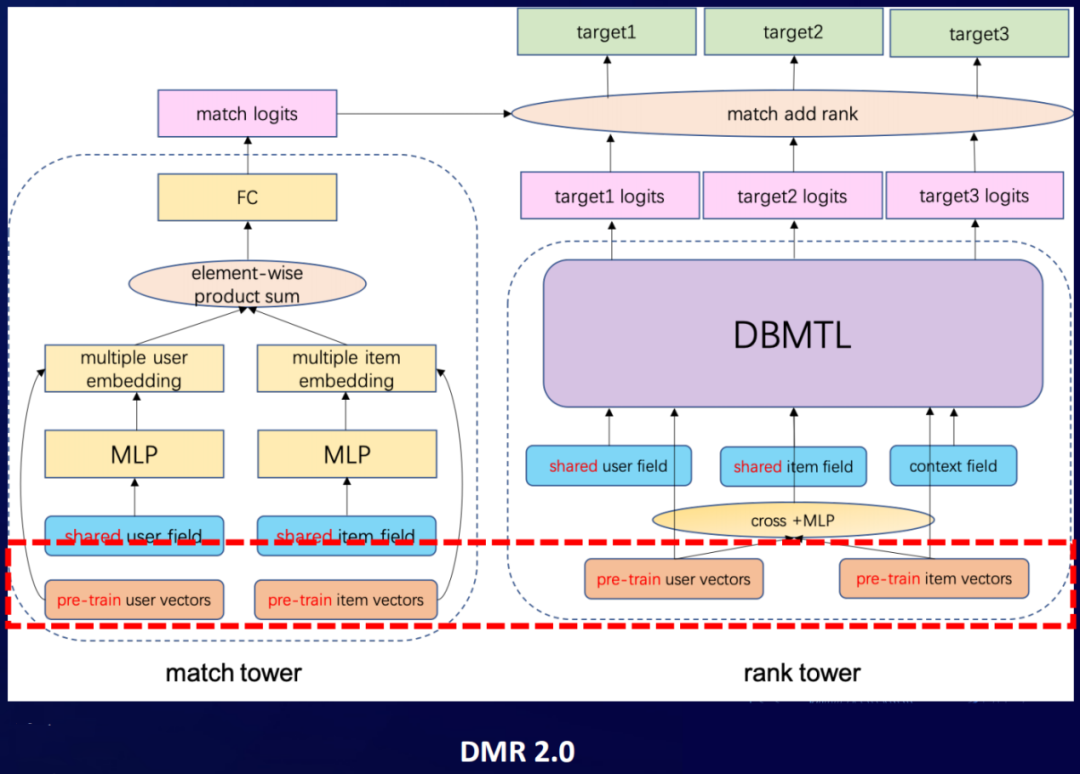
③ 两阶段学习
首先,在match tower里面,因为我们在pre-train的这些向量已经在空间里面得到表征,直接喂到上面点积的操作就可以了。直接给他们做一个点乘的操作,然后再跟原来得到的这个embedding去做一个sum pooling或mean pooling,过FC,得到logits。在rank tower里,我们同样把预训练好的一些特征,输入到网络里面去。
④ 效果
通过两阶段的方式,在各个场景里面去落地上线,也取得了正向的效果提升。
频道页:pctr+3.5%,uctr +1.5%,人均点击 +4%,人均时长+3%
猜你喜欢直播TAB:pctr+1.3%,uctr +2.2%,人均点击 +2.8%,人均时长 +3.5%
淘宝直播APP:pctr +2.2%,uctr 持平,人均点击 +1.6%,人均时长 1.5%
⑤ 后续
但这个两阶段的学习过程,链路上严重依赖于上下游关系的,所以不太好维护,通用性也比较差。所以我们现在也在做一个端到端的学习模型,直接在端到端的时候去刻画这种召回匹配的关系。以上我们在淘宝直播这种列表式的信息流下做的一些优化的工作,主要围绕着多目标和召回匹配。
1. RUI Ranking1.0
① 背景/动机
我们淘宝直播还有另外一个比较重要的场景,是用户进入直播间之后可以进行上下滑动的推荐场景。模型标题是Refer-User-Item Ranking,很显然这个场景下我们需要去刻画refer、user、item之间的关系。

在排序模型里面,refer是什么?就是我们当前进入的直播间,也就是说滑动前的这个直播间。在这个场景下,我们应该给用户推荐什么?
从产品功能角度来考虑的话,假设我们用户是从列表页的信息流点进去的,直播间本身在信息流场景下,已经做了用户个性化的承接。如果我们在上下滑的时候还去做这种个性化的推荐的话,那就会存在产品功能上的重复了。
所以在上下滑场景,我们更倾向于做refer相关性的承接,也有一些历史经验来做参考的,像我们淘内的短视频/直播都是这样子的。
此外,在一些资讯类的APP,我们看到在文章的详情末尾,也会做一些相关性的推荐,在一些长视频网站点击视频之后,在它右手边也会有一些相关内容的推荐。
由于之前淘宝直播算法小组的人力特别有限,很长时间都只有两三个人的资源,所以在旧策略上就做得很简单,只是做了在召回侧优先这层相关性。
② 优化
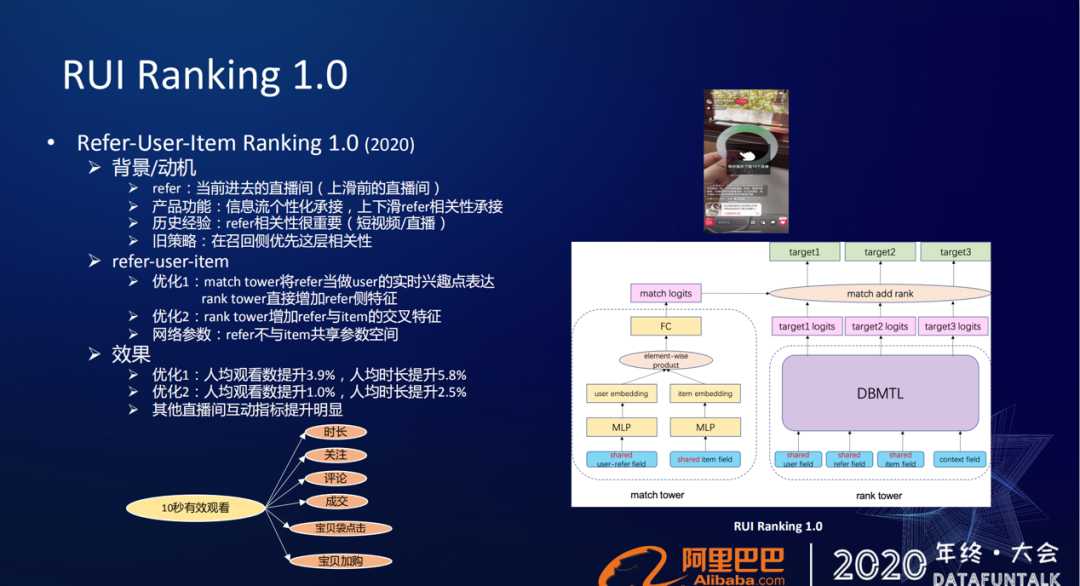
今年我们就可以把单独拎出来做了一个优化。因为一开始没有把refer引进来,所以我们在第一个优化里面就把refer的信息给引进来了,采用的还是我们前面提到的DMR框架。
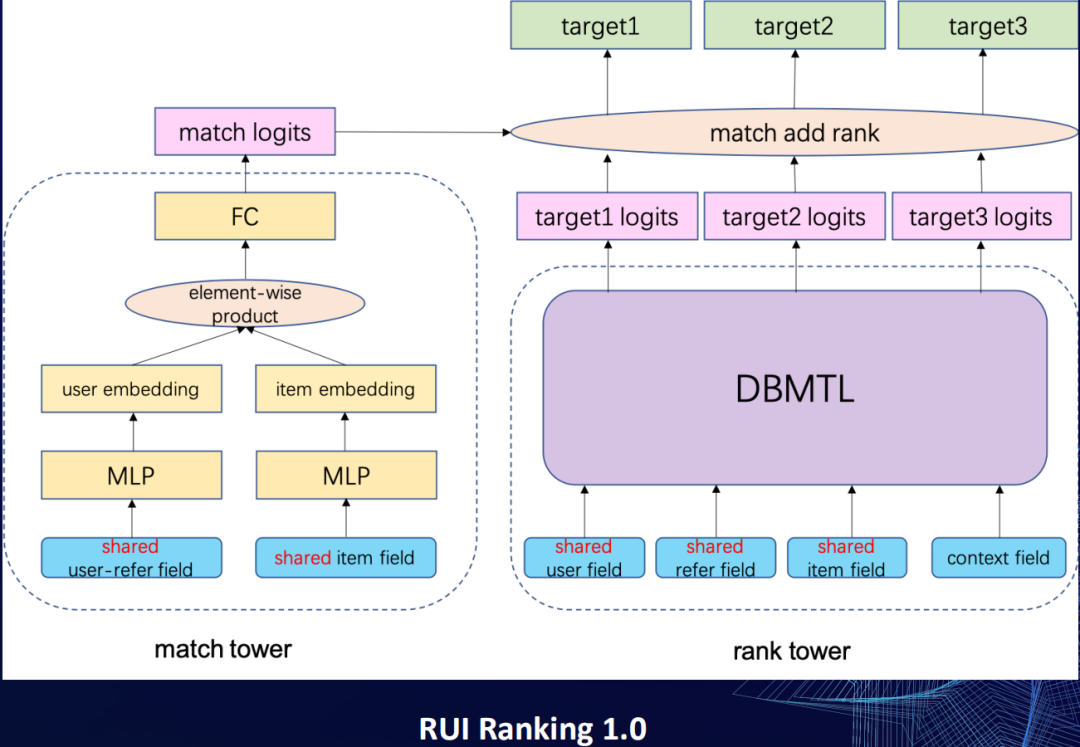
那么refer怎么用呢?我们将refer当成用户的一个实时兴趣点的表征,所以在match tower这侧,把refer引进到原先的user field中,当成用户的表达的一部分。在rank tower侧,我们同样把refer这些特征给引进来。另外由于要在这个场景下去推荐跟refer相关的一些主播,所以也会构建一些refer跟item跟主播相交叉的特征,而refer和item不会去共享参数空间,因为他们表达的信息是不一样的。
③ 效果
这样优化后,我们的人均观看数和人均时长也得到了明显的一个效果提升:
优化1:人均观看数提升3.9%,人均时长提升5.8%;
优化2:人均观看数提升1.0%,人均时长提升2.5%;
其他直播间互动指标提升明显;
④ 多目标
最后一点,这样全屏式的场景下,怎么去做目标的刻画的?在这个场景下,是没有像信息流式有用户的点击行为,所以在这个场景下,我们用的是一个10秒有效观看率。我们认为10秒观看行为才是有效的,所以我们的一跳的目标就定义为10秒有效观看率,在这个前序目标下,才会有时长、关注、评论、成交,然后宝贝袋点击、宝贝加购的这些目标。
2. RUI Ranking2.0
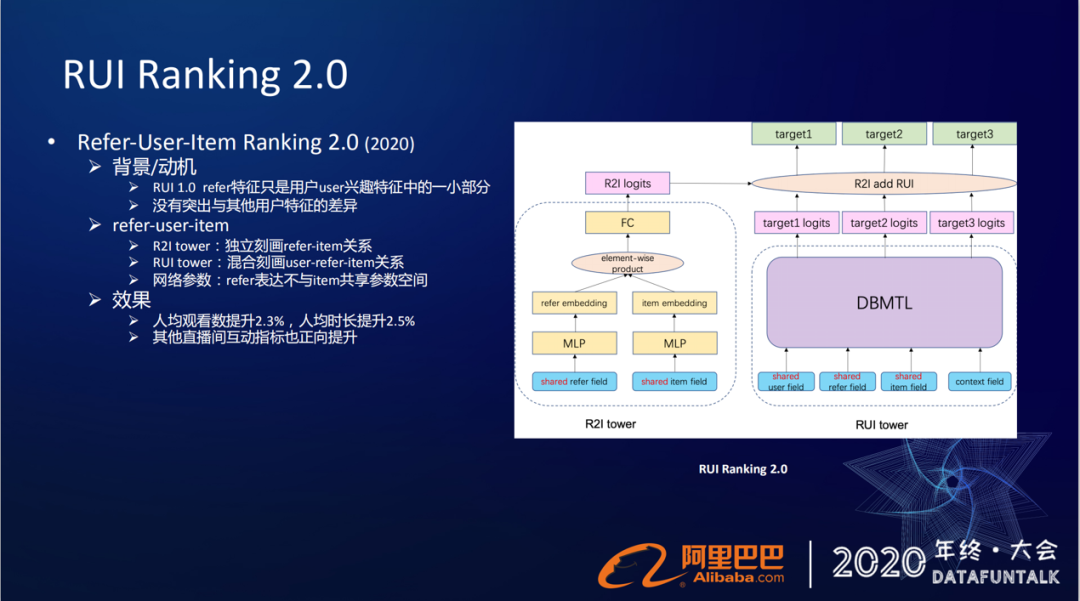
① 背景/动机
我们1.0版本只是简单地将refer信息给引进来了,它只是当成用户兴趣特征中的一部分,其实在网络中并没有突出跟其他用户的特征的差异。
② 优化
在2.0版本我们就做了简单的优化,左边的match tower,原来是先去刻画user和item的关系,现在直接换成了refer和item的关系刻画,还是原来的点积的框架match tower,只是把原先user的特征换成了refer特征,然后显式的去刻画refer和item的关系。
③ 效果
这个小改动,也取得了有两个点左右的效果提升。
人均观看数提升2.3%,人均时长提升2.5%
其他直播间互动指标也正向提升
3. RUI Ranking3.0
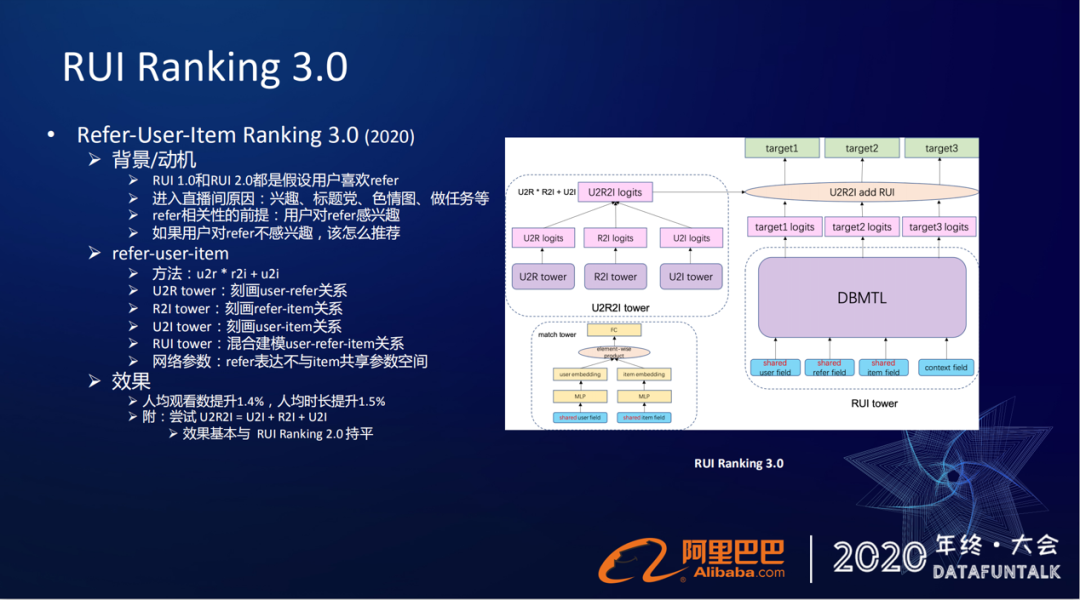
① 背景/动机
但我们1.0和2.0这个版本都是假设用户喜欢当前的直播间refer,但是用户进入直播间的渠道是非常多的,他有可能是因为自己的兴趣进去的,有可能是因为标题党吸引的,还有可能是因为去做金币、去果园或者农场做任务进来的。如果用户对refer不感兴趣的时候,我们要怎么样去做这个推荐?
② 优化
如果我们还是去推荐跟refer相关的主播,就会存在着推荐一错再错的问题。所以我们在3.0版本里,在网络里把user和refer的关系给刻画进来了。
整个三元的关系刻画,通过公式来表达就是 u2r*r2i+u2i。原来框架下左边的match tower现在换成了三个小塔,每个小塔还是点积的框架,每个小塔就分别去刻画这三者之中的两两之间关系,从左到右就是user2refer的关系,中间是refer2item,右边是user2item关系,然后在上层我们通过u2r*r2i+u2i公式来进行融合。
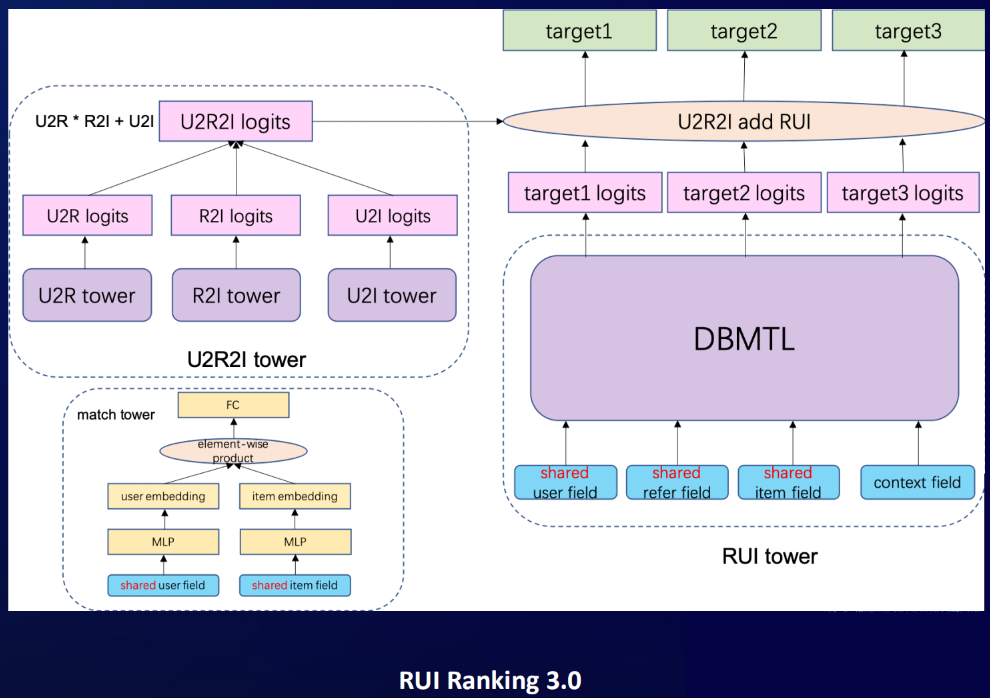
这个公式告诉我们:当用户对refer感兴趣的时候,可以去推荐跟它相关的。如果user对refer不感兴趣的时候,可以用个性化user2item的关系来做承接。
③ 效果
这个优化,在场景下去落地实验也取得了有1点多的提升(人均观看数提升1.4%,人均时长提升1.5%)。这个提升相对是比较弱的,可能的原因是大部分用户进入直播间还是比较感兴趣的。
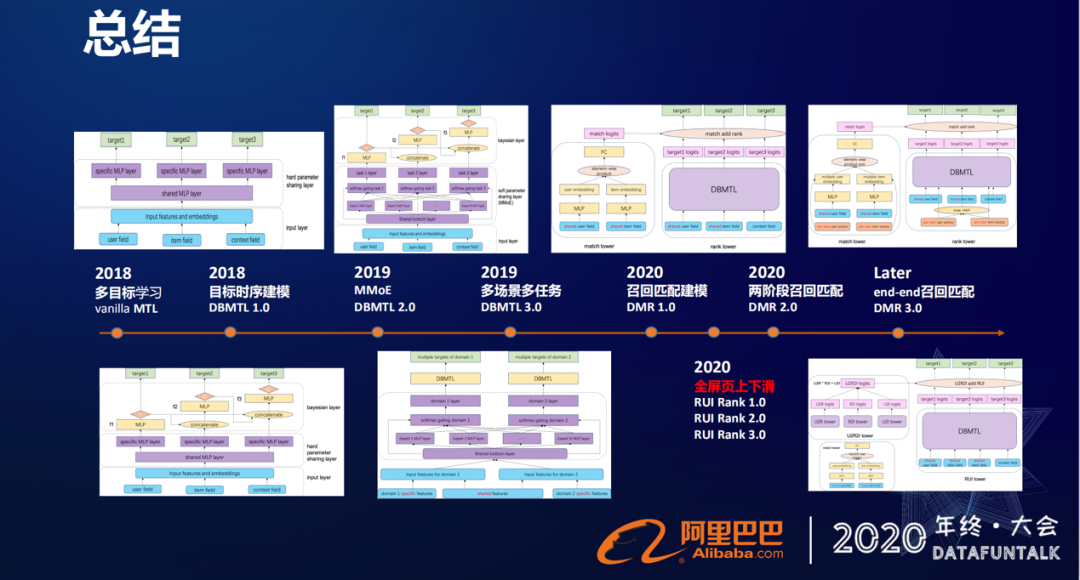
最后给大家做一下简单的总结,从2018年开始,我们的多目标的排序模型就升级到了深度学习的多目标学习框架,就是原生的这种Multi-task Learning,然后我们又基于目标的时序建模提出了DBMTL。2019年我们又结合MMoE,做了升级,之后我们又提出了一个多场景多任务的学习框架。
今年我们围绕着召回匹配建模提出了一个双塔的DMR框架,然后我们又做了一个两阶段的召回匹配学习。此外我们也在全屏页直播间上下滑做了基于业务特性上优化的一些工作。
顺着这个时间轴,大家可以看到我们的工作其实是比较有连续性的哥迭代性的。这里每一个网络的框架,都是由一个个简单的模块组成的,就像积木一样,而我们要做的工作就是将这些积木怎么样去拼凑起来,搭建出能够满足我们业务需求,促进我们业务发展所需要的样子,最终服务于我们的业务。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~