
对话推荐算法研究综述
A Survey of Conversational Recommendation Algorithms
作者:赵梦媛,黄晓雯*,桑基韬,于剑 单位:
北京交通大学计算机与信息技术学院 北京交通大学人工智能研究院 北京交通大学交通数据分析与挖掘北京市重点实验室 邮箱:{f19120453, xwhuang, jtsang, jianyu}@bjtu.edu.cn **论文:**http://www.jos.org.cn/jos/article/abstract/6521 *通讯作者
01
简介
推荐系统是一种通过理解用户的兴趣和偏好帮助用户过滤大量无效信息并获取感兴趣的信息或者物品的信息过滤系统。目前主流的推荐系统主要基于离线的、历史的用户数据,不断训练和优化线下模型,继而为在线的用户推荐物品,这类训练方式主要存在三个问题:基于稀疏且具有噪声的历史数据估计用户偏好的不可靠估计、对影响用户行为的在线上下文环境因素的忽略和默认用户清楚自身偏好的不可靠假设。由于对话系统关注于用户的实时反馈数据,获取用户当前交互的意图,因此“对话推荐”通过结合对话形式与推荐任务成为解决传统推荐问题的有效手段。对话推荐将对话系统实时交互的数据获取方式应用到推荐系统中,采用了与传统推荐系统不同的推荐思路,通过利用在线交互信息,引导和捕捉用户当前的偏好兴趣,并及时进行反馈和更新。在过去的几年里,越来越多的研究者开始关注对话推荐系统,这一方面归功于自然语言处理领域中语音助手以及聊天机器人技术的广泛使用,另一方面受益于强化学习、知识图谱等技术在推荐策略中的成熟应用。本文将对话推荐系统的整体框架进行梳理,将对话推荐算法研究所使用的数据集进行分类,同时对评价对话推荐效果的相关指标进行讨论,重点关注于对话推荐系统中的后台对话策略与推荐逻辑,对近年来的对话推荐算法进行综述,最后对对话推荐领域的未来发展方向进行展望。
2.1
什么是对话推荐系统?
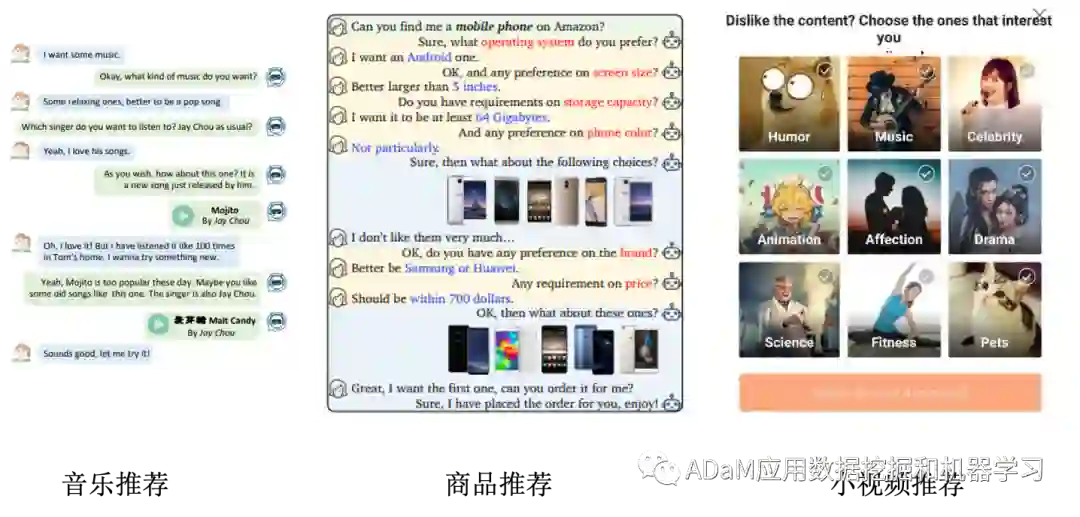
对话推荐系统的交互推荐方式就像是将传统静态推荐系统与对话系统结合,在与用户的交互中通过询问用户相关问题动态地更新用户的兴趣偏好。因此对话推荐系统可以有如下两种定义。
**定义一:**对话推荐系统是以推荐为目标导向的对话系统。系统通过与用户的在线对话达到捕捉用户兴趣从而推荐物品的目的。
**定义二:**对话推荐系统是具有多轮交互形式的推荐系统。交互的形式狭义上是自然语言形式或语音形式,广义上还包括推荐系统中用户的任何行为数据的形式(如:点击、浏览)
2.2
传统推荐系统vs对话推荐系统
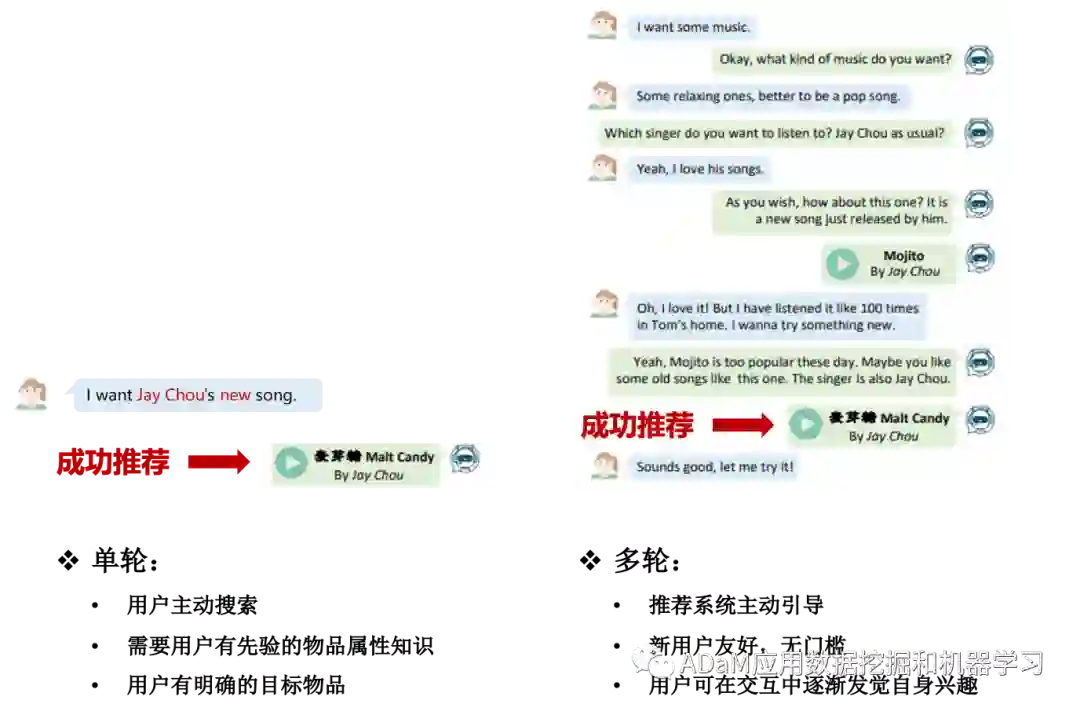
传统的推荐系统中,用户在寻找具有特定属性的物品时,可以通过主动搜索来进行,例如,用户可以搜索“春季的短款夹克”,其中关键短语“春季”和“短款”是“夹克”的属性。在这个场景中,用户自己构造查询,推荐效果不仅依赖于搜索引擎,更依赖用户在构造查询方面的专业知识。推荐系统需要用户根据自己的先验知识输入可能的属性选项限制,从而更准确地定位到合适的推荐候选项集合,推荐系统才能在此基础上帮助用户找到目标物品。总之,这种推荐系统中的主动搜索方式需要用户熟悉自己想要的每一件物品,然而在实际操作中并非如此。当用户并不熟悉自己想要物品的属性时,推荐系统就被期望能够主动向用户介绍他们可能喜欢的潜在物品,然而,传统的推荐系统无法做到这一点,它只能使用静态的历史记录作为输入,这也就导致了传统单向、静态的推荐系统中存在三个主要问题:基于稀疏且具有噪声的历史数据估计用户偏好的不可靠估计、对影响用户行为的在线上下文环境因素的忽略和默认用户清楚自身偏好的不可靠假设。
2.2.1 **共性:**面向推荐任务,都需要理解用户兴趣偏好,为用户筛选信息 **区别:**使用数据不同: (1)传统推荐系统主要依赖用户的历史交互数据。 (2)对话推荐系统主要依赖用户的在线反馈数据。 推荐模型更新方式不同: (1)传统推荐系统是静态的,其从用户的历史交互信息中来估计用户偏好,上线后不做更新,更新需定期下线。 (2)对话推荐系统是动态的,其与用户进行交互,在模型有不确定的地方,可以主动咨询用户,实时更新推荐模型参数。
03
对话推荐系统特点:多轮交互、目标导向
04
对话推荐系统的流程
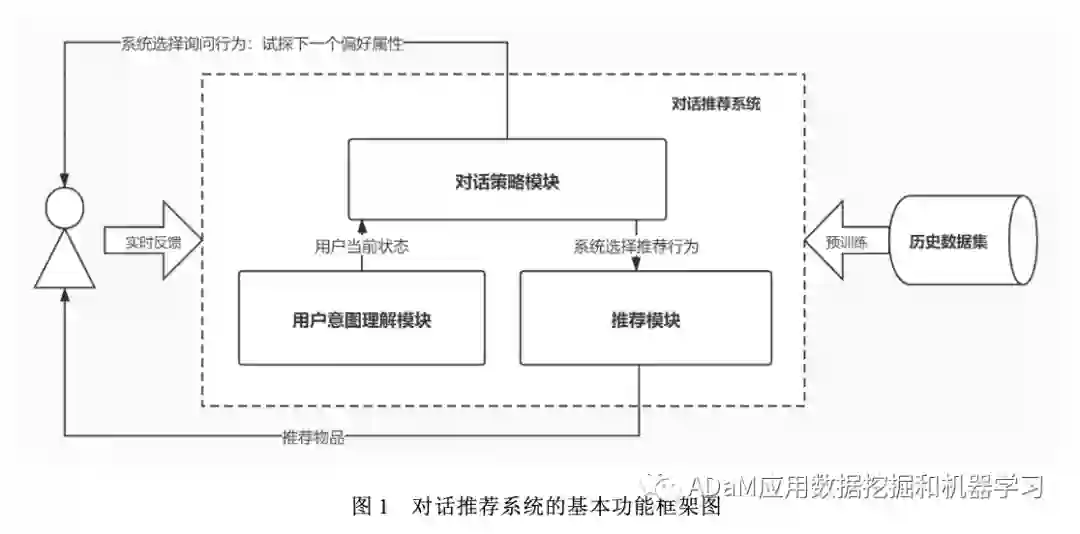
一个标准的CRS框架包含了三大功能模块:用户意图理解模块、对话策略模块和推荐模块。从功能模块来看,CRS与DS非常相似,这进一步说明CRS的核心思路来源就是DS。
**用户意图理解模块:**用户与系统交互的“翻译器”,将用户的输入(文本、图像、评分、浏览等交互行为)处理成会话的状态表示,作为对话策略模块的输入,如果是基于自然语言交互的对话推荐,该模块还需要生成流畅的自然语言反馈。
**对话策略模块:**是核心模块,是用户意图模块和推荐模块的连接桥梁,该模块处理和记录用户偏好,并根据用户当前的交互历史数据,决定系统当前轮次反馈给用户的交互内容,引导用户决策,最终实现符合用户偏好的一次成功推荐。
**推荐模块:**建模用户与物品的关系,在被对话策略模块调用时输出当前轮次下契合该用户偏好的推荐物品列表。
05
对话推荐系统的用户意图理解模块
用户与系统交互的“翻译器”,与用户直接进行信息交换的模块,处理用户的输入数据(文本、图像、评分、浏览等交互行为)处理成会话的状态表示,作为对话策略模块的输入。
(1)面向自然语言、语音和图像的用户意图:理解处理自然语言、语音和图像,研究如何像人类一样沟通交互。

(2)面向用户行为数据的用户意图理解:处理数据为用户偏好集合,接受用户二值反馈,输出系统策略行为(询问或推荐)
06
对话推荐系统的对话策略模块
是对话推荐系统的核心模块,该模块处理和记录用户偏好,并根据用户当前的交互历史数据,决定系统当前轮次反馈给用户的交互内容,引导用户决策,最终实现符合用户偏好的一次成功推荐。
对话推荐的交互性使得用户有机会及时表达自己的意图,以获得更好的个性化推荐服务,并且由于具有交互性,对话推荐还可以主动探索用户看不见的物品空间,从而引导用户发掘自己的偏好。然而对话推荐的探索过程是有代价的,与利用已经获得的偏好推荐高置信度的物品相比,暴露不相关的物品空间的信息可能会伤害用户的偏好,失去做出准确推荐的机会。此外由于用户与系统互动的时间和精力有限,一次失败的探索将浪费用户的时间与精力,可能造成用户的流失。因此追求探索和收益的平衡(exploration and exploitation,E&E)是对话推荐研究中的一个关键问题,对话策略模块主要解决的问题就是权衡探索与收益,它是CRS核心模块。
这个模块的研究工作根据目前研究者使用的核心策略技术,主要分成以下四大类:
(1)基于人工规则
基于人工规则的的方法非常简单,根据人的先验领域知识,设置对话规则,例如,设置限制,规定固定轮次交互后都要提供一个推荐物品,或者根据置信度推荐前k个物品。

(2)基于神经网络
利用神经网络模型输出的动作概率分布决定对话策略,例如,通过GRU将当前对话的上下文编码成隐状态向量输入,softmax层输出概率分布,根据概率分布决定是否推荐以及推荐什么物品。

(3)基于****强化学习
将对话上下文、用户偏好等编码为状态向量,输入到强化策略网络中,策略网络基于奖励函数进行训练,学习对话策略,输出系统动作向量。
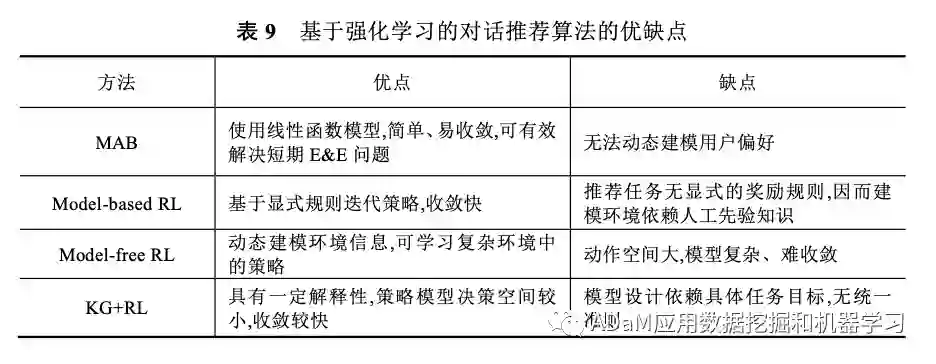
(4)基于元学习
核心思想是“学习如何学习一个推荐模型”。将元学习应用到对话推荐算法中是个值得研究的思路。

07
对话推荐系统的推荐模块
推荐模块是CRS中实现推荐功能的模块,根据已经捕捉到的用户偏好推荐用户当前最感兴趣的目标物品。大部分的研究工作中,推荐模块都采用简单的推荐模型,例如矩阵分解(matrix factorization),这是因为简单的推荐模型就已经可以满足对话推荐系统的推荐需求,使用过于复杂的推荐模型,反而会使系统整体复杂度上升,使对话推荐模型的训练变得困难。
(1)基于自编码器的模型(autoencoder-based models) 自编码器(autoencoder)本身就常被用于推荐系统中,可以克服冷启动问题(cold-start problem)
(2)基于图卷积神经网络的模型(GCN-based models) 图卷积神经网络面向应用场景中的图结构数据,通过卷积操作,同时考虑节点的属性以及邻居节点的属性,让模型学习到节点更好的局部表示,从而提高基于图结构数据的模型性能。
08
对话推荐任务-常用数据集

对话推荐的交互形式既可以是语音、自然语言语句,也可以是更为一般的用户交互行为数据(如点击、浏览、购买等)。因此在对话推荐的研究工作中,常用的数据集也分为两类:第一类是研究者将用户交互语音或语句与推荐数据结合,人工构造的数据集;第二类是更为一般的推荐系统通用数据集。
09
对话推荐任务-评价指标
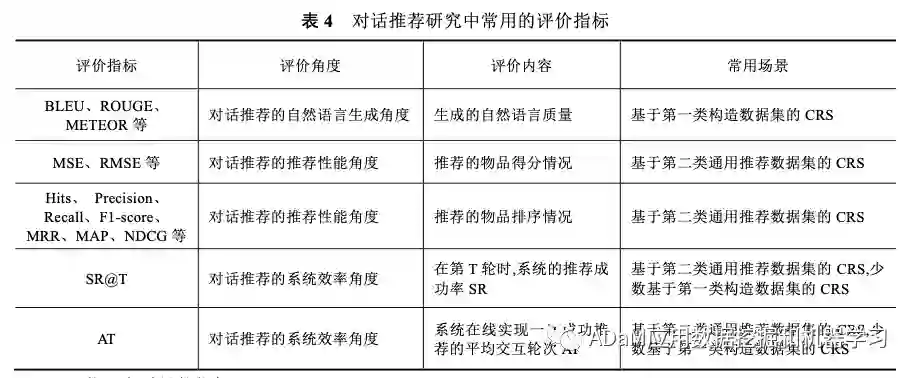
在两类不同类型数据集的应用场景下,对话推荐的评价指标也不相同,目前尚没有统一且成熟的评价指标体系来评价对话推荐系统的功能。如表所示,在对话推荐相关的研究工作中,研究者由于研究的出发点和关注的角度不同,往往在实验中使用不同的评价指标,从其关注的某几个方面评价对话推荐的效果。 根据各类指标的评估内容和角度,把目前对话推荐任务的相关评价指标分为三类: (1)评价对话推荐的语言质量的指标; (2)评价对话推荐的推荐性能的指标; (3)评价对话推荐的系统效率的指标。
10
对话推荐任务-评估方式
(1)在线用户评估
与真实的用户交互,在真实的环境中验证系统的效果,评估的结果真实且可信。虽然在线用户评估的结果很优越,但实际的研究工作大多没有条件进行线上用户评估,在线用户的评估方式很难被广泛使用。原因有二,一是使用在线用户进行训练和评估,不成熟的对话推荐系统会损害用户体验,造成实际的损失;二是在线用户评估数据的收集和整理需要额外的时间和精力,投入的成本加大。
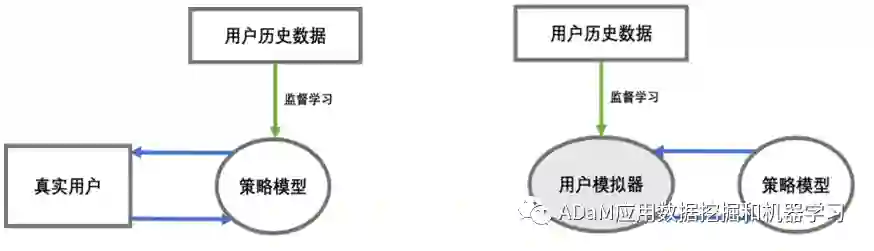
(2)用户模拟器评估
用户模拟器(user simulator)通过拟合用户的历史数据,提供对话推荐的交互环境,为对话推荐系统每轮交互的输出动作模拟用户可能的行为。使用用户模拟器,使得对话推荐系统的交互训练更加快捷,也极大降低了评估成本。但该方式也有明显的缺点,即用户模拟器无法完全正确地预测在线用户的真实反馈。
11
对话推荐系统研究中存在的问题
1、评价指标不统一
人类评估和专家分析是必要的,目前没有完美的指标可以全面评估对话推荐系统的功能。
2、探索与收益的平衡
(1)如何在保证推荐准确率的前提下,减轻用户的交互负担; (2)如何将会话数据与用户历史数据结合,推断用户具有时序性特点的偏好; (3)如何利用用户历史兴趣引导用户发掘未来偏好。
3、数据稀疏性
(1)物品冷启动问题:一定程度上可以解决传统推荐系统中的用户冷启动问题,但在物品冷启动问题上没有非常好的解决方式。 (2)用户反馈数据稀疏问题:对话推荐受制于有限的对话轮次,获取到的用户反馈只有有限轮次数量的数据。
4、对话策略模型低效
(1)模型训练方式问题:对话推荐系统的环境缺少明确的规则,从而导致使用强化模型时没有明确奖励函数以及清晰的动作空间。
(2)模型面向任务的设计问题:强化对话推荐算法中的强化模型设计完全依赖于研究者的直觉与经验,与任务不合适的强化模型会导致对话策略模型的训练低效,甚至是无效。
12
未来研究方向
协同优化的端到端对话推荐 * 知识增强的对话推荐 * 基于多模态交互数据的对话推荐 * 无偏的对话推荐 * 用户反馈的改进 * 更智能的对话推荐策略设计
13
总结
作为解决目前传统推荐系统中存在问题的有效手段,对话推荐的研究具有重大意义。近两年大量的对话推荐相关工作在推荐领域和数据挖掘领域的顶级会议与期刊中被发表,对话推荐的研究进入新的发展阶段。本文详细讨论了对话推荐的研究内容与特点,重点关注对话推荐中的算法设计,对目前的对话推荐算法进行了归类和总结,并介绍了对话推荐的评价指标及当前研究的挑战与未来的研究方向。本文有助于人们理解对话推荐的研究内容、研究难点与研究思路,引发人们对未来对话推荐研究的思考。



