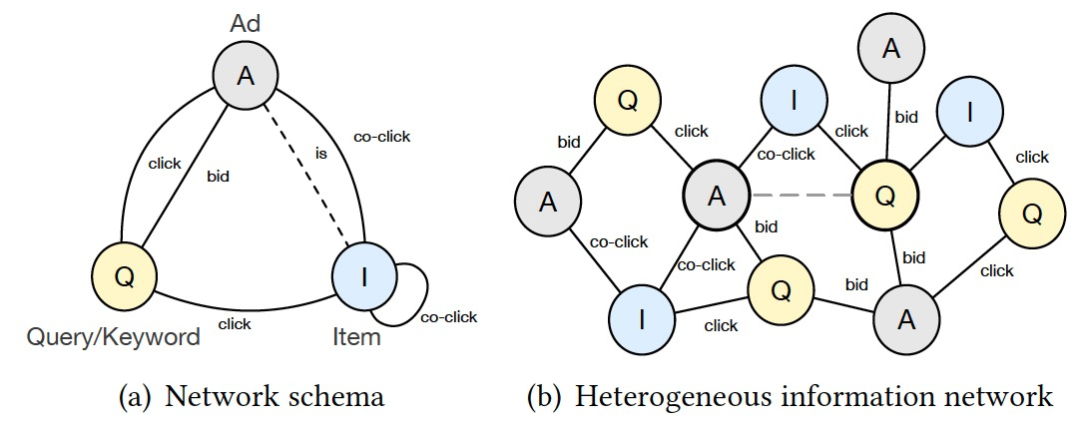
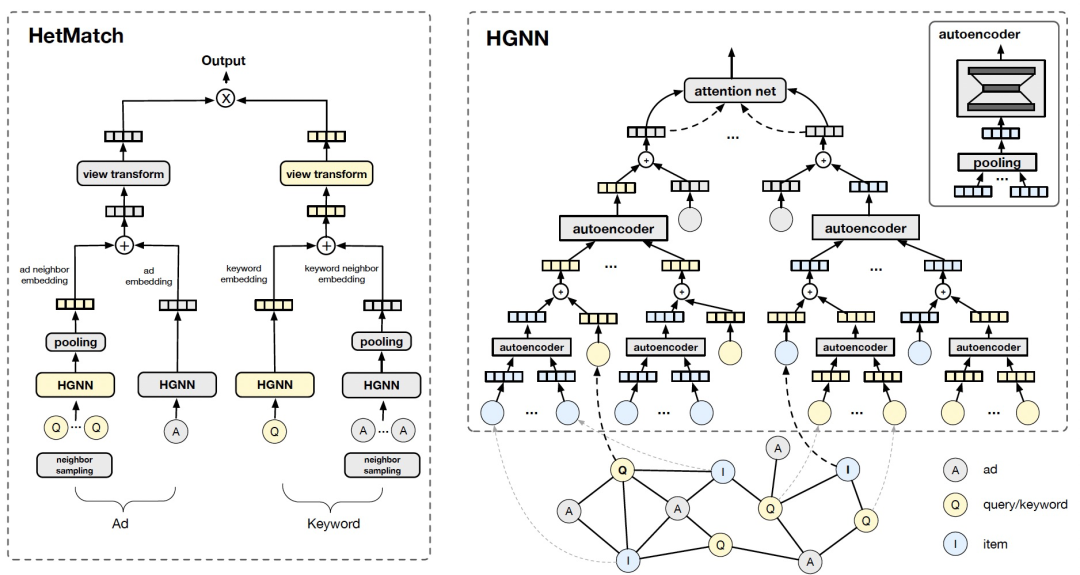
通常在获得语义表征层后,模型会直接计算点积分数并计算 loss 进行优化。在该步骤之前,我们将引入一种孪生匹配网络,来缓解异构图匹配问题中由于不同类型节点的模型参数和 metapath 定义不同,导致 ad 和 keyword 的表征难以分布在同一空间的问题。为了解决这一问题,我们将 ad 和 keyword 的匹配问题改为同构超节点(meta node)的匹配问题,即两组 ad-keyword pair 之间的匹配,保证匹配左右两端结构的同质性。对于 ad 侧,我们通过计算得到 ad 侧的 embedding,以及和 ad 最为相关的 topK 个 keyword 的 embedding 的均值,求和后通过线性变换得到最终的 embedding;keyword 侧的作法也类似。更通俗地说,我们将 ad 及其关联最紧密的 keyword 邻居与 keyword 及其关联最紧密的 ad 邻居进行匹配。
multi-view 学习和view转换
为了提高冷启动 ad 的效果,相比于以前只基于点击关系建立学习目标,我们引入了多种类型的 ad-keyword 的关系作为我们的优化目标。具体来说,我们选取 ad-keyword 点击关系,采买关系和 ad 背后的商品(item)和 keyword 的点击关系进行建模。考虑到不同 view 下标签分布存在较大的差异,不适合混合不同的标签进行学习,我们设计了一种高效的 multi-view 结构。即在利用 GNN 获得共享表征的基础上,针对 ad 侧不同的视图任务使用不同的神经网络进行分布调整,而 keyword 侧只学习一份 embedding。我们使用 sampled softmax loss 进行任务优化,其基本思想为最大化正样本点积的同时最小化不相关的 ad-keyword 对。
本项工作中,我们基于围绕关键词和商品的超大规模异质网络进行了关键词召回任务的探索。在未来工作中,我们将探索迈向更大的图网络,通过考虑更丰富的节点类型和属性信息来更好地对广告与关键词进行建模。此外,HetMatch 仍然主要依赖于较简单的分词 id 特征进行文本建模,考虑到基于 transformer 的语言模型在不同文本任务上的出色表现,结合 GNN 和 transformer 来进一步提升关键词推荐质量也是我们未来的工作方向。
相关文献
[1] Wu, Shiwen, Fei Sun, Wentao Zhang, and Bin Cui. "Graph neural networks in recommender systems: a survey." arXiv preprint arXiv:2011.02260 (2020).
[2] Xu, Jiarong, Yang Yang, Chunping Wang, Zongtao Liu, Jing Zhang, Lei Chen, and Jiangang Lu. "Robust Network Enhancement from Flawed Networks." IEEE Transactions on Knowledge and Data Engineering (2020).