【泡泡一分钟】基于图神经网络的情景识别
每天一分钟,带你读遍机器人顶级会议文章
标题:Situation Recognition with Graph Neural Networks
作者:Ruiyu Li, Makarand Tapaswi, Renjie Liao, Jiaya Jia, Raquel Urtasun, Sanja Fidler
来源:International Conference on Computer Vision (ICCV 2017)
编译:张鲁
审核:颜青松 陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

我们解决了识别图片中的情景的问题。给定一个图像,我们的任务是预测最显著的动词(动作),并为其填充其语义角色,例如谁在执行动作,动作的来源和目标是什么等。不同的动词具有不同的角色(例如:“攻击”具有“武器”这一角色),并且每个角色可以采用许多可能的值(名词)。我们提出了一个基于图结构神经网络的模型,它允许我们使用在图上定义的神经网络来高效地捕捉角色之间的相互依赖关系。具有不同图形连接性的实验表明,我们在角色之间传播信息的方法明显优于现有的工作,以及多个基线方法。在预测完整情景的方面,本文方法相对于先前的工作大致获得了3~5个百分点的提升。我们还对我们的模型进行了全面的定性分析,并对动词中不同角色的影响进行了分析。
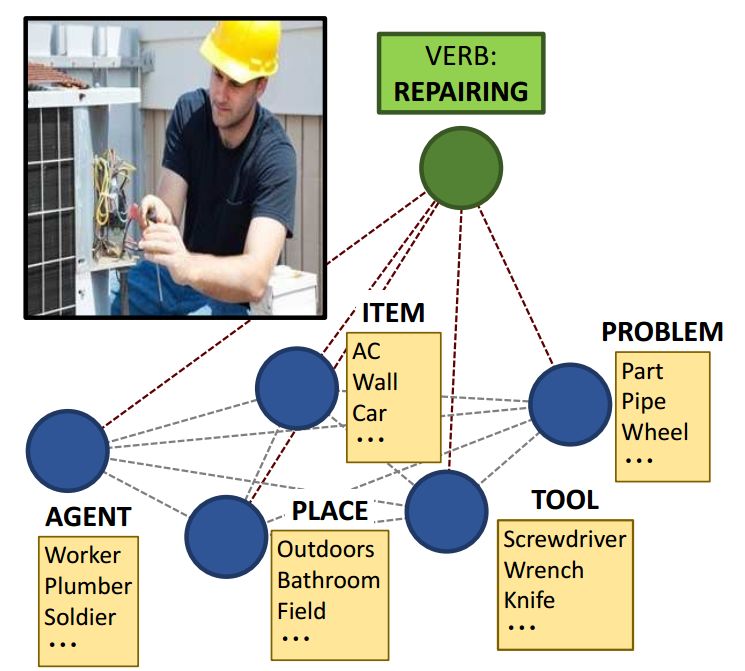
图1. 理解图像不仅仅是预测最显著的动作。我们需要知道是谁在进行这个动作,他/她在使用什么工具,等等。情景识别是一个结构化的预测任务,它旨在预测由多个角色-名词对组成的动词及其框架。该图大致展示了我们的模型,该模型使用图来模拟动词及其角色之间的依赖关系。
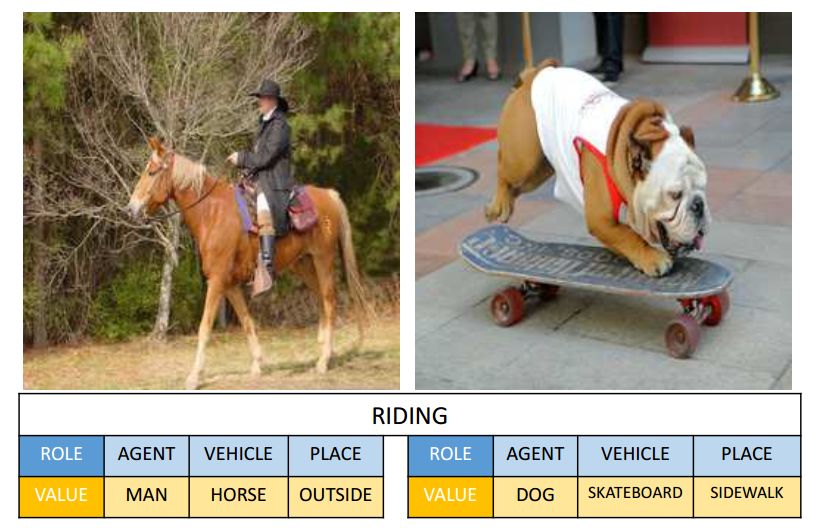
图2. 对应于相同动词的图像在涉及动词角色的内容上可能完全不同。这使得情景识别变得困难。

Abstract
We address the problem of recognizing situations in images. Given an image, the task is to predict the most salient verb (action), and fill its semantic roles such as who is performing the action, what is the source and target of the action, etc. Different verbs have different roles (e.g. attacking has weapon), and each role can take on many possible values (nouns). We propose a model based on Graph Neural Networks that allows us to efficiently capture joint dependencies between roles using neural networks defined on a graph. Experiments with different graph connectivities show that our approach that propagates information between roles significantly outperforms existing work, as well as multiple baselines. We obtain roughly 3- 5% improvement over previous work in predicting the full situation. We also provide a thorough qualitative analysis of our model and influence of different roles in the verbs.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com





