心慕手追,让机器像人一样理解句子 | 论文访谈间 #14

论文作者 | 王少楠,张家俊,宗成庆(中科院自动化所)
特约记者 | 张琨(中国科学技术大学)
学习句子的语义表示就是将句子的含义映射到一个向量空间中,同时保留句子本身的一些特性,例如:表达相似含义的句子在向量空间中应该距离更近。而句子表示模型是将句子的含义编码为计算机可以理解的形式,这是解决大部分自然语言处理问题的先决条件,因此直接影响了许多自然语言处理任务的性能,如在神经机器翻译中需要首先将源语言句子表示为一个向量、在问答系统中需要将问句和答案编码为向量表示等。
但是句子是由不同的词构成的,不同的词包含的信息量不同,对句子的语义表示影响也就不同。如何能区分出这些词汇,给予重要的词更多的注意力,对句子语义的表示有着重要的意义,同时也有助于机器对句子语义的理解。来自中国科学院自动化研究所的王少楠,张家俊和宗成庆老师发表在国际人工智能联合会议(IJCAI)上的文章“Learning Sentence Representation with Guidance of Human Attention”通过对人类阅读和句子理解机制的模仿,找到了一种新的编码句子语义的方法。
在理解句子语义方面,人类无疑是机器最好的老师,那么人类是如何阅读和理解句子的呢?由于组成句子的词所包含的信息量不同,因此人类在阅读和理解句子时会选择性的注意句子中的某些词汇,也会选择性的跳读一些词汇,这种注意力机制(图 1)让人阅读和理解句子变得更加高效。

▲ 图1:人类阅读过程中的眼动(注意力)轨迹
受人类注意力机制的启发,作者认为在构建句子表示时应该给重要的词汇赋予较高的权重,这样可以得到更好的句子语义表示。那么哪些词汇对句子含义的表达更重要呢?同样我们从人类阅读文本时的注意力分布寻找答案,大量的有关人类阅读时间的研究证明了词汇的特性,如词性、词长、词频、词汇惊异度(Surprisal)等,都会影响人类阅读文本时对这个词汇的关注程度。因此,作者选择了词汇惊异度和词汇的词性来对词汇的重要程度进行建模。
词汇惊异度:反应了一个单词在一个句子中传达的信息量,由词汇在句子中的负对数条件概率计算得到,通常这个值越高表示理解这个词越困难,需要更多的阅读时间。
词汇的词性:词的不同分类属性,例如:动词,名词,形容词,介词,连词等。心理学实验已经证实,人类在阅读文本时会更加注意如名词、动词、形容词等类型的词汇,而在如介词和连词等词汇上会花费较少的时间。
对于以上两种特征,作者分别提出了不同的词汇重要性计算方法,针对词汇惊异度特征,作者直接将它的数值作为词汇的重要性分数;针对词汇词性特征,作者通过赋予每个词汇类别一个向量表示,通过类别向量与对应的词汇向量进行点乘,然后归一化,将得到的结果作为这个词的注意力权重,最后将通过注意力机制的词的加权表示送给当前最好的句子表示模型(图 2)中,得到句子的语义表示。
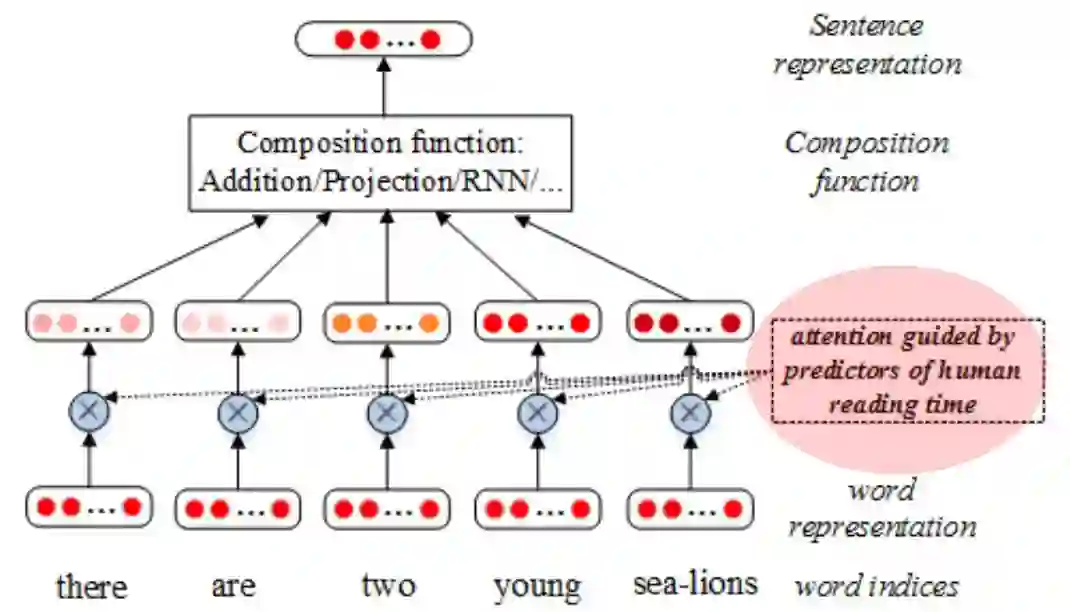
▲ 图2:嵌入注意力机制的句子表示模型
在实验设计上,作者利用 semantic textual similarity(STS)任务中的 24 个覆盖新闻,图片视频描述,注解,机器翻译评估等领域的数据集对模型进行了验证,结果证实了作者提出的方法可以更加准确有效的获得句子的语义表示。同时,这种方法是通过对人类阅读理解句子的方式的模仿,因此该模型学习到的注意力分布是否与人类的注意力分布类似呢?作者在 Dundee 语料(一种研究人类阅读和眼动轨迹的数据集)上进行了验证,实验结果(图 3)显示模型计算出的注意力权重与人类的阅读时间规律高度相似,这就证实了作者提出的模型成功模仿了人类的阅读理解方式。

▲ 图3:人类阅读时间和模型计算的注意力权重对比结果
作者有话说:
这篇文章的出发点很简单,由于目前在句子表示中的注意力机制与人类阅读和理解句子的注意力机制不相符,我就想去尝试能不能利用人类阅读过程中的注意力机制去改进现有的句子表示模型。这个工作最大的创新性在于结合了认知心理学的一些研究结论,通过返回的审稿意见,我发现这种研究思路是很受欢迎和认可的。目前,在自然语言处理领域越来越多的人开始尝试利用人类理解语言的机制来改进或者建立语言处理模型,相信这种跨领域的结合会带来意想不到的惊喜!
欢迎点击「阅读原文」查看论文:
Learning Sentence Representation with Guidance of Human Attention
关于中国中文信息学会青工委
中国中文信息学会青年工作委员会是中国中文信息学会的下属学术组织,专门面向全国中文信息处理领域的青年学者和学生开展工作。

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


点击 | 阅读原文 | 查看论文





