有图才更有真相 | 论文访谈间 #16

论文作者 | 谢若冰,刘知远,栾焕博,孙茂松(清华大学)
特约记者 | 杨凯杰(南京理工大学)
当人类需要学习和记忆大量的知识时,如果只有枯燥的文本作为学习材料(例如背英语单词、记数学公式),那么学习的过程会相当痛苦;假如能够加入一些具体的图片使得知识和概念变得生动形象起来,就能达到事半功倍的效果。那么在知识表示学习的任务中,能不能也借鉴类似的方法,从而获得更好的效果呢?
来自清华大学的谢若冰同学,刘知远老师,栾焕博老师,孙茂松老师,在国际人工智能联合会议(IJCAI)发表的文章"Image-embodied Knowledge Representation Learning"中,创新性地在知识表示学习任务中引入图像信息,并提出一个全新的融合实体图像的知识表示学习模型,建立了跨模态的知识表示。该工作探索了知识空间和图像空间的联合的可能,也为知识反馈辅助图像领域的任务打下一定的基础;同时,作者在真实数据集上对模型进行了验证,在知识图谱补全和三元组分类等任务上均获得了不错的效果,证明这种跨模态的知识表示可以更好地辅助知识驱动型的任务。

▲ 图1
图 1 即是一些实体图片的例子。每个实体都有多张图片提供丰富的视觉信息,对实体直观外表和行为进行描述。
基于实体图像的知识表示学习模型,在实现上存在以下一些难点:
首先,图像信息与知识信息是异质的,表达形式也存在巨大的差异。如何对图像信息进行合理的建模,使之能够与知识信息进行交互与联合学习,是首先需要解决的。
其次,现在的大规模图像数据库中,一个实体往往有成千上万张实体图像。这些实体图像质量良莠不齐,对实体描述的粒度与角度也不尽相同,甚至可能出现噪声与错误标注。如何自动地从这些图像候选中选择信息量较大、质量较高的实体图像进行联合学习,也是一项巨大的挑战。
例如对于高尔夫这个实体,有些图像样例给出了高尔夫球的特写,有些图像样例给出了运动员在打高尔夫球的场景,也有些图像给出了高尔夫球场的全景。这些实体图像提供的实体相关信息角度都不相同,选取更有信息量的图像与知识空间进行交互,显然能够进一步提升联合模型的知识表示效果。
为了解决这些问题,作者提出了 IKRL 模型,为每个实体设置了两种知识表示:基于结构的表示和基于图像的表示。文中首先使用基于卷积神经网络的图像表示模块和图像映射模块,从实体图像中构造图像在知识空间的表示;然后使用注意力模型自动选择高质量的图像,组成实体基于图像的表示,如图 2 所示。
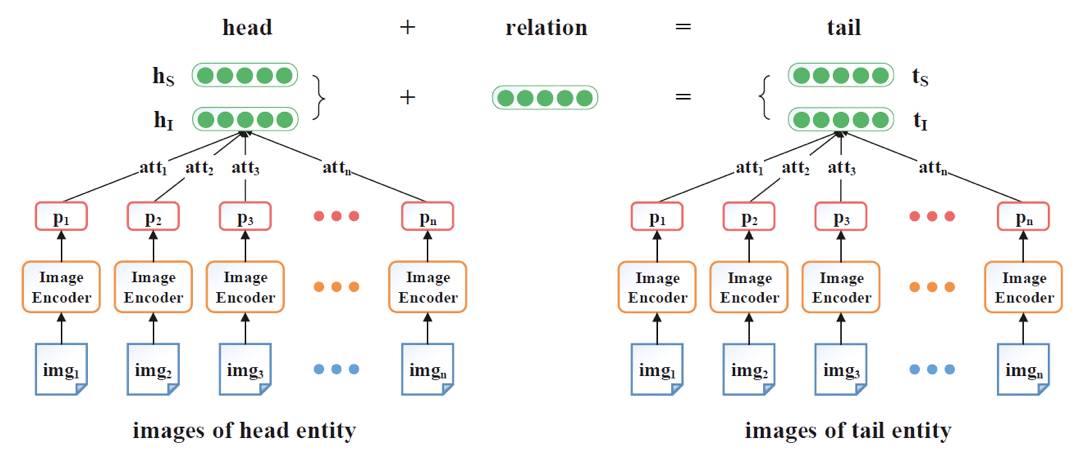
▲ 图2
为了评测模型的效果,作者在知识图谱补全和三元组分类等任务上进行了评测。
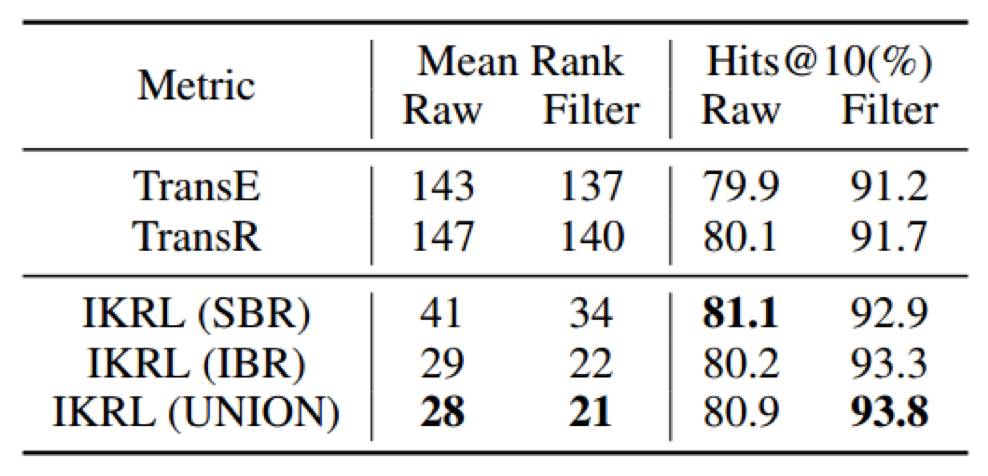
▲ 表1:实体预测结果
从表 1 的结果中可以看出,所有 IKRL 模型都在 Mean Rank 和 Hits@10 两个指标上超过了所有的基准模型,其中 IKRL (UNION) 取得了最好的效果。由此可见,来自图像的视觉信息已被成功地编码进了实体表示当中。
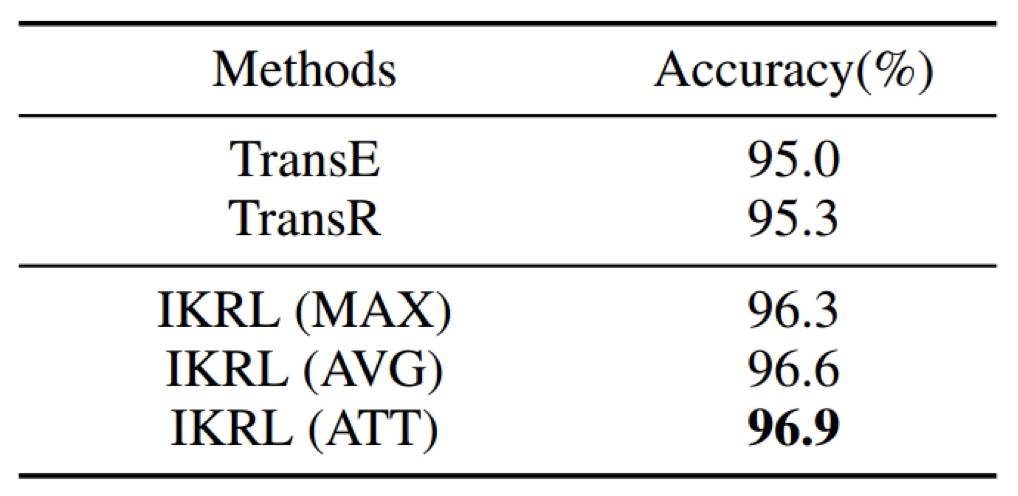
▲ 表2:三元组分类结果
IKRL 模型在三元组分类任务上同样取得了出色的效果。
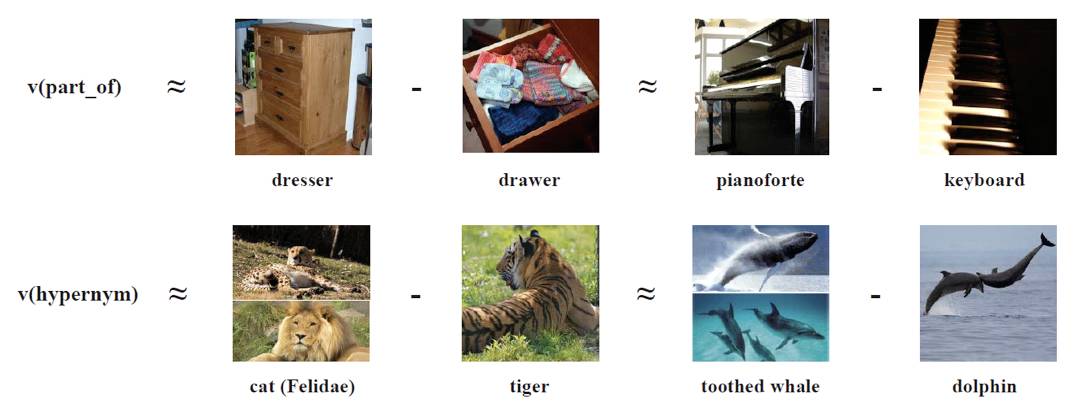
▲ 图3

▲ 图4
同时,作者还探索了基于图像的表示在图像-知识空间的语义平移现象(图 3),以及注意力机制自动选择高质量图像的效果(图 4),进一步证明了方法的有效性
作者有话说:
随着人工智能的发展,人们越来越重视知识的作用,并开始将知识图谱融入问答系统、信息检索和智能对话系统等知识驱动型的任务中。世界是复杂而多元的,我们认为充分运用知识图谱之外的文本、图像等多源异构的信息,能够帮助构建更好的知识表示,同时也能够使得知识反馈文本、图像等领域。我们的工作在融合知识空间和图像空间,建立跨模态的知识表示上做出了一个初步的尝试,未来在融合多源信息的知识表示上还有很大的研究空间。
欢迎点击「阅读原文」查看论文:
Image-embodied Knowledge Representation Learning
关于中国中文信息学会青工委
中国中文信息学会青年工作委员会是中国中文信息学会的下属学术组织,专门面向全国中文信息处理领域的青年学者和学生开展工作。

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


点击 | 阅读原文 | 查看论文




