赛尔原创 | 基于深度学习的候选答案句抽取研究
作者:哈工大SCIR硕士生俞霖霖 博士生尹庆宇
1 前言
近些年深度学习火热,很大程度上就是因为深度学习能够让计算机自动学习输入向量的特征,并且将特征的学习融入到了建立模型的过程中,从而大量减少了人为的工作量,因为特征提取是传统机器学习任务中最费时、最重要也最具技巧的步骤。除此以外,目前以深度学习为核心的某些机器学习应用,在一些特定的应用场景下,已经超越现有算法的最优性能,并被逐渐应用于各种实际场景下。
近些年来,深度学习成为自然语言处理领域的热点,几乎所有的研究热点都已成为深度学习的天下,当然,候选答案句抽取任务也不例外,也有许多专家学者利用深度学习来进行候选答案句抽取任务的研究[1,2,3]。Bord[4]将词语与知识库映射到相同的向量空间之中,模型学习得到一个低维的向量,然后利用这些向量的相似度来衡量问句与答案句之间的相关程度。在2016年ACL上,Tan[5]提出了一种结合了CNN和LSTM的网络结构,先使用LSTM学习,再使用CNN学习,得到一种更为复杂的模型,最终也得到了更优的实验效果。使用深度学习的方法来抽取候选答案句,能够让计算机自动学习问句与答案句之间的关系特征。因此我们的研究中,引入深度学习的方法,我们认为,传统机器学习也只能对人为提取的特征进行学习,而特征之外的信息,例如整个句子的语义等等无法很好的描述,但深度学习基于多层网络结构,让计算机自动将词向量进行结合,得到句子的信息,这包括了词汇信息、语法信息和最关键的语义信息。
2 方法
2.1 基于CNN候选答案句抽取
对于使用卷积神经网络进行候选答案句抽取任务,核心在于利用卷积神经网络去学习句子的向量表示。此外,相比于常规的卷积神经网络结构,我们使用的代价函数是hinge loss而不是常规的交叉熵代价函数。具体的网络结构见图1。

图1:CNN模型图
从图中可以看到,我们模型的输入是三个句子,问句、正确答案句和错误答案句,思路是利用卷积层和池化层分别对着三个句子进行卷积,学习得到相应的句子向量表示,之后再做一次隐藏层的向量维度变化,然后使用该向量进行相似度的计算,相似度使用的是余弦相似度,得到问句与答案句之间的分数,而代价函数使用的是hingeloss,目的是为了使的正确答案子得分能够领先于其他句子得分。
2.2 基于Attention-bi-GRU的候选答案句抽取
普通的LSTM或GRU模型是基于循环神经网络的改进模型,虽然有相应的机制来记忆前面的节点,但是仍然无法保证前后节点的信息都能得到同样的记忆,梯度消失问题只是得到了部分改善,并未完全解决,因此我们使用双向结构,即正向学习一遍每个节点,再逆向学习一遍每个节点,使得前后的节点都有差不多的权重。
此外,我们发现,在训练语料中,问句或者答案句很长,但是我们能够判断这个问句在问什么内容或者答案句是否正确的时候,通常只根据最关键的几个词或者短语就能判断出来,例如:“《计算机应用基础(中国铁道出版社出版图书)》卖价多少?”,整个问句中书名占了绝大多数,虽然在正常情况下,书名也重要,但是我们的候选答案句已经是所有该书的信息,并不涉及其他书籍,所以这个书名信息在我们的任务中的作用其实是很小的,而该问句真正的关键词在于“卖价”,但凡涉及到卖价或者数字的信息的答案句就很有可能是正确答案。这说明句子中不同成分之间的权重其实是不等的,而之前我们所使用的所有深度学习网络模型都将文本所有内容均等的进行学习,想必所得到的结果也不会尽如人意。
因此,我们加入Attention机制。Attention机制主要是对每次的输入与隐层输出又进行了一次计算,计算得到一个权重,这个步骤相当于专门设置了一个参数来给每个节点学习一个权重,这样对于句子中重要的部分能够更加重视,不重要的部分也可以进行遗忘,相比于之前的网络所有节点的权重基本都是一致的,全靠参数来学习,无论是在理论解释上还是最终的实验结果上,Attention机制都有使用的必要。
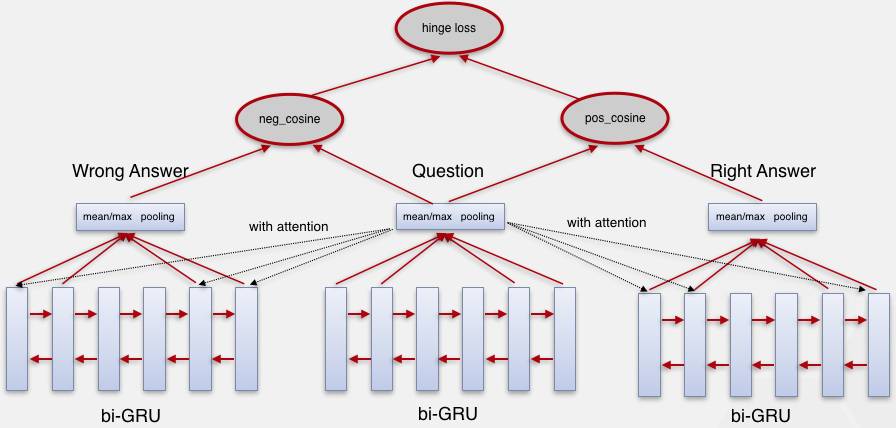
图2 Attention-bi-GRU模型图
2.3 融合方法的候选答案句抽取
在我们分析深度学习模型的错误用例和之前的错误用例的时候,本来我们是想看看深度学习模型相比于之前的模型改进了哪些用例,并且深度学习的不足在哪里,但是在错误用例中我们惊奇地发现,深度学习模型的错误用例和之前传统机器学习方法的错误用例很少有一致的地方,换句话说,实验数据中的大部分用例要么是深度学习模型能答对,要么是传统机器学习方法能答对,深度学习模型并不是我们设想的那样是在传统机器学习的基础上进行的改进,可以说两者之间各有优劣,只是最终的结果恰巧是深度学习更好一点。因此,我们的想法就是是否可以将传统机器学习与深度学习进行结合,获取两者的优势,以得到一个更优的结果呢?答案是肯定的。
我们做的两个融合方法分别是CNN与传统语义匹配融合,CNN与SVM融合的实验。将CNN与语义匹配方法进行融合,由于语义匹配方法直接计算两个问句之间的分数,并没有中间特征,所以结合的方式也是比较简单的将两种方法的分数进行加权求和,使得最终的分数能够结合两种方法的优势,我们尝试了各种不同的权重,最终的结果已经是最优的结果。而另一个实验是CNN与SVM进行融合的实验,由于SVM需要人工提取的特征,而深度学习的优势是能够自动学习特征,因此我们尝试将CNN模型自动学习到的特征加入到SVM中,与原有的人工特征一起进行训练。
3 实验数据及评价指标
3.1 实验数据
近些年,国内外有许多专家学者在答案抽取这个研究方向上做出了不懈的努力,但他们的工作绝大多数都是基于英文TREC评测的语料,基于中文的研究工作很少,去年NLPCC组织了第一届的中文语料的DBQA评测,给出了18万多的训练语料和12万多的测试语料,这份语料是我们实验部分所使用的语料。对于实验部分的数据,即NLPCC的DBQA评测语料,其格式为每一行为一个例子,每行有两个句子和一个标签,分别用制表符分隔,第一个句子为问句,第二个句子为答案句,签为0或1,而相同的问句都在一起,但是答案句之间的顺序都已打乱,并不是百科词条中的顺序。具体如图3。

图3:NLPCC评测语料数据格式
3.2 评价指标
在我们候选答案句抽取的实验中,我们使用的评价指标为平均排序倒数(MeanReciprocal Rank,MRR)和平均准确率(MeanAveragePrecision ,MAP),而最常用的要数MRR指标。其中,MRR指标无论从公式还是名字来看,都一目了然,即对所有排序倒数求平均。而MAP相对复杂一些,AveP求的是对于一个问句和n个候选答案句的准确率,k是检索回来答案句的排名,m是正确答案句的数量,n是所有候选答案句的数量,p(k)是前k个句子的准确率,rel(k)对应第k个句子如果是正确答案,则为1,否则为0。
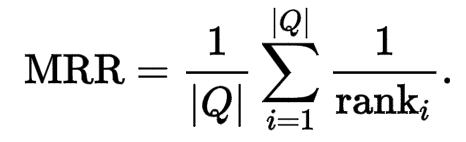
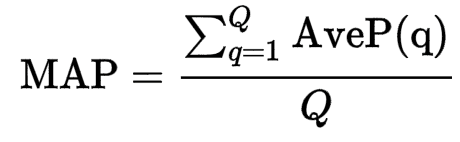
4 实验结果与结论分析
在NLPCC的数据集上,我们利用基于深度学习的候选答案句抽取方法进行了相关的实验。实验结果如表1所示。
表1:候选答案句抽取实验结果
方法 |
MAP |
MRR |
CNN |
70.29% |
70.24% |
LSTM |
61.54% |
61.49% |
GRU |
60.86% |
60.83% |
Attention-bi-LSTM |
66.55% |
66.48% |
Attention-bi-GRU |
66.60% |
66.56% |
CNN with sim-BM25 |
73.57% |
73.37% |
CNN with SVM |
78.90% |
78.66% |
实验结果中,深度学习之间的方法各有差异,通过attention实验,我们可以看到,加入了attention机制之后的方法相比于不加的方法效果提升了很多,这说明attention机制的确对长文本的权重学习有较大的指导意义,并且适用于我们的候选答案句抽取任务,因为我们任务的核心就是学习问句或者答案句的向量表示。而实验效果最高的CNN模型,并且CNN模型只是简单的基础模型,并没有其他额外改进,就达到了最高的效果,这说明在学习句子向量表示的任务上,卷积神经网络比循环神经网络有更大的优势。融合方法中,分数的加权求和融合方法实验结果比之前效果最好的CNN方法要高出三个百分点,而利用不同特征进行的实验融合比之前的结果提高了八个百分点,这是一个很大的提升。这些改进说明,不同思路的方法进行结合的确能够发挥各自的优势,使得原本深度学习或者传统方法回答不对的问题现在能够兼顾两者的特点,最终回答对或者回答的更好。
5 总结
本文使用了多种基于深度学习模型的候选答案句抽取方法,并提出了相应的改进措施,通过最终的实验发现,attention机制下的bi-GRU模型达到了最优的实验结果,说明了attention机制对于句子权重的学习有着重大的指导意义。此外,我们还提出了将传统方法与深度学习方法进行结合的方式,分为简单的分数结合与模型的特征结合这两种,无论是哪种融合方式,相对于单纯的一种方法在实验效果上都有很大的提升,而最优效果还是利用特征进行结合,让模型再自动学习特征中的信息。
参考文献:
[1] V. Punyakanok, D. Roth, and W.Yih. 2004. Mapping dependencies trees: Anapplication to question answering.
[2] Bilotti, M. W., P. Ogilvie, J. Callan, andE. Nyberg. 2007. Structured retrieval for question answering. In Proceedings of the 30th Annual International ACM SIGIR Conferenceon Research and Development in Information Retrieval, pages 351–358, Amsterdam.
[3] Wen-tau Yih, Xiaodong He, and Christopher Meek, and Andrzej Pastusiak.2013. Question answering using enhanced lexical semantic models. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics,pages 1744-1753. Association for Computational Linguistics.
[4] Antoine Bordes, Sumit Chopra, and Jason Weston. 2014.Question answering with subgraph embeddings. CoRR, abs/1406.3676.
[5] Tan M, Santos C N, Xiang B, et al. Improved Representation Learning for Question Answer Matching[C]. meeting of the association for computational linguistics, 2016: 464-473.
本期责任编辑: 丁效
本期编辑: 蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,郭江,赵森栋
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




