NeurIPS 2022 | 如何实现表格数据上的迁移学习和零样本学习?

今年的 NeurIPS 评分7/7/7 有惊无险中了一篇文章,做的是在表格数据上的pretraining, transfer learning,和 zero-shot learning。

论文标题:
TransTab: Learning Transferable Tabular Transformers Across Tables
论文链接:
文档链接:
https://transtab.readthedocs.io/en/latest/

不够flexible的表格学习
表格学习(tabular learning)顾名思义也就是在表格上的学习(废话)。比方说,很多 kaggle 上的比赛都是属于表格学习的范畴,都是构建若干个 feature,然后预测对应的标签。

可以说比起 CV 和 NLP,tabular learning 才是现实世界中机器学习会更经常用到的场景。
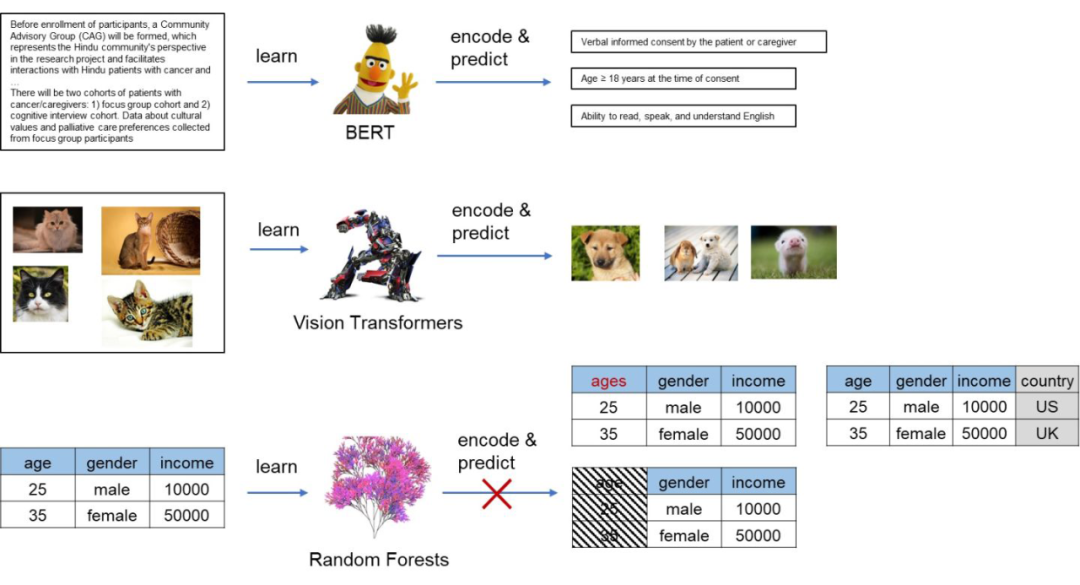
大家都知道最近在 NLP 和 CV 领域各种预训练模型大杀四方,属于深度学习方法的 BERT,ViT 之流都已经成了标配的 backbone。但是,在表格领域往往还是 “xgboost is all you need”。无他,简单直接好用,效果还不差。在这种情况下,自然就有了不少研究者把目光投到了这片传统机器学习的“最后的堡垒”。
最近的方法,比如 VIME [1],SCARF [2],SubTab [3] 等都把自监督学习引入了表格领域,或是做一些 masked cell modeling(感觉上就是 auto-encoder 的变种),或是做一些 contrastive learning 把一行的 feature 做一些替换,删除之类的操作来构建正负样本。
但是,他们的设定都不大符合真实场景。我们往往不是说有一个巨大的表格,然后只有其中一点点样本有标签。而是说我们有若干个有标签的表格,但是每个表格的列名(column)都不大一样。问题在于怎样把这些表格都利用起来,学习一个大模型,才能最大程度地利用手上的数据。
但是,已知的所有方法都只能处理固定 column 的表格。一旦表格的 column 有一丝丝变化,比如 age->ages,或者 age 这一列被删掉。那么之前训练好的模型就没用了,只能重新 数据处理->特征工程->模型训练 这一个流程。这无疑是不利于我们实现像 CV 和 NLP 里那样做表格学习的大模型训练的。
那么,有没有一种可能,我们设计一种模型,不管表格变成啥样,都能进行编码和预测呢?

足够flexible的表格学习
事实上,如果我们仔细观察每一个表格,会发现其实表格的列名(column names)其实蕴含了丰富的信息。比如在上图中,age 列对应了 25,我们自然就知道是 25 岁;income 列对应了 10000,我们知道可能是 10000 个某种货币单位。如果 age 列改成 weight,25 就不再表示 25 岁,而是 25kg 或者其它重量单位。由此可见,表格中 feature 所代表的语义信息是由 column 所决定的。如果我们想要迁移表格的信息,则必须要考虑到 column 的语义。

上表有三种 feature,分别是 gender (类别型),age(数值型),和 is_grduated(布尔型)。
对于三种类型的 feature,我们可作不同的处理。
对于类别型(categorical),我们直接把列名与其拼在一起,“male” 变为 “gender male”;
对于数值型(numerical),我们先把列名 tokenize 和 embedding,再把数值 和 embedding 作 element-wise 相乘;
-
对于布尔型(boolean),我们把列名 tokenize 和embedding,再根据 feature 是 1 或者 0 来决定是否保留此 embedding。如果是 1,则直接保留;是 0 则不将此 feature 加入之后的 embedding;
对应下图的特征处理模块。
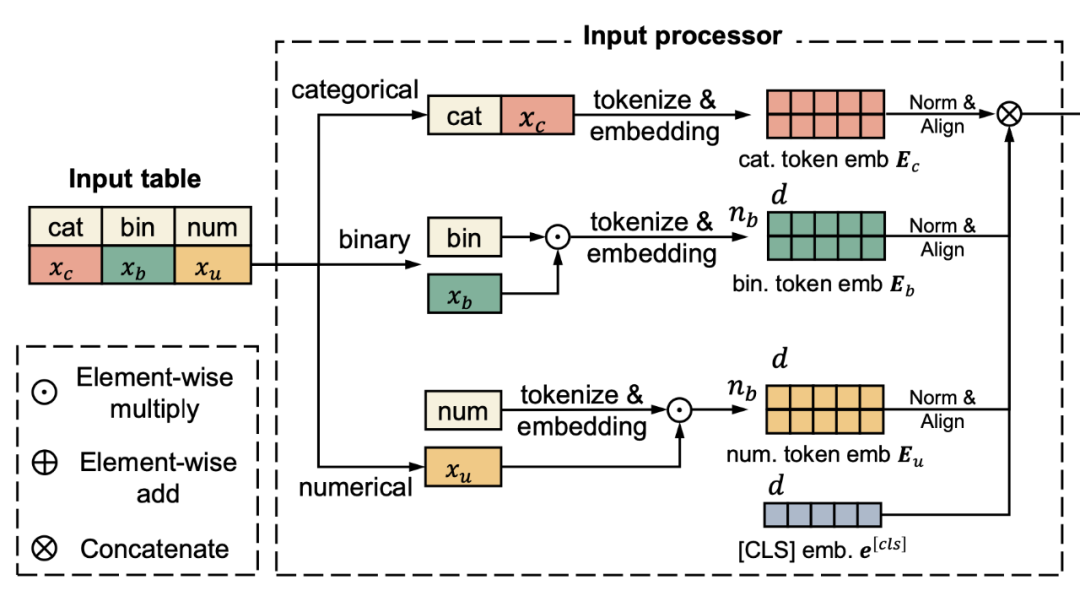
▲ TransTab的特征处理模块
有了这个处理模块,理论上任意 column 的表格,TransTab 都可以将其处理成 embedding,作为后续 transformers 的输入进行处理和预测。

TransTab能做什么
因为可以编码任意的表格数据,TransTab 可以支持以下一些新任务:
在多个表格上直接进行 supervised learning,然后做 finetuning
在来自同一个领域但是 feature 不同的表格上一起 supervised learning
在多个领域有或无标签的表格上做 contrastive pretraining
-
在多个表格上 supervised learning 后在一个新的表格上直接做预测
对应下图的(1)-(4)项任务。
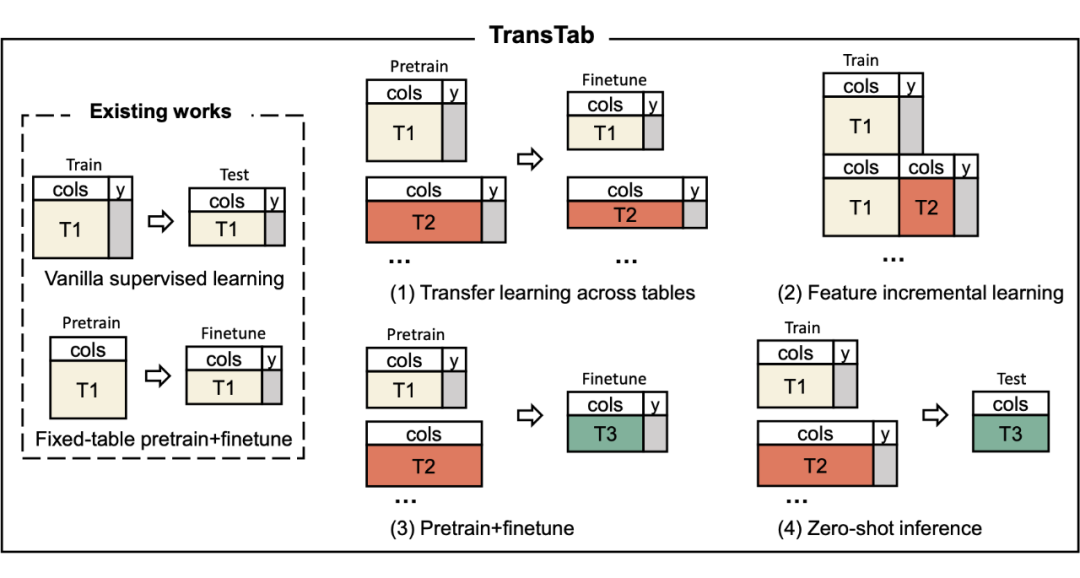
▲ TransTab支持的tabular learning任务。

TransTab的预训练
下面我们再简单讲一下怎样基于 TransTab 做预训练。我们的设定如上图(3)所示,假定我们有一系列上游表格,它们有可能有标签或者没标签。我们在有标签的数据上更希望能利用到标签信息,那么可能的想法是:对于所有表格共享一个 backbone,然后对每一个表格单独设置一个 classification head 做 supervised learning。
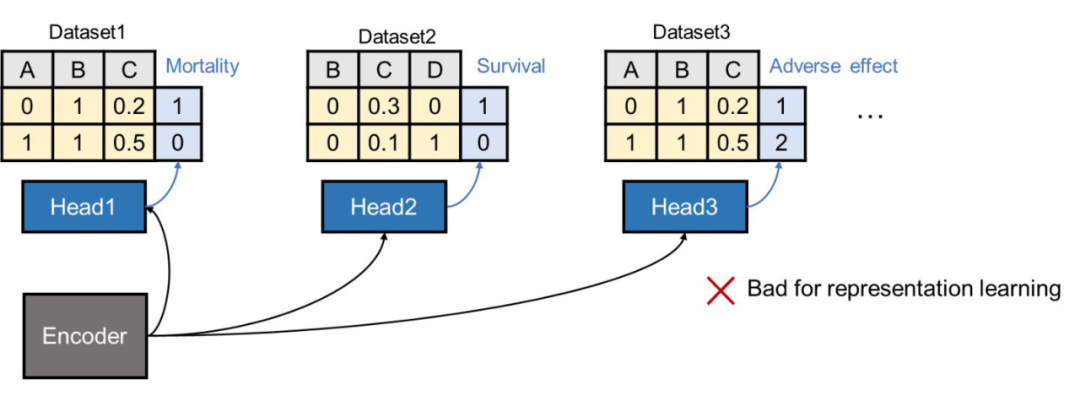
但是我们发现,这样做会导致 backbone encoder 很难学到好的表征。因为每个表格的标签类别不同,或者可能是相反的定义(比如 mortality 和 survival)。考虑到这点,我们引入了一种基于标签的 supervised contrastive learning,在论文里叫做 vertical partition contrastive learning(VPCL)。
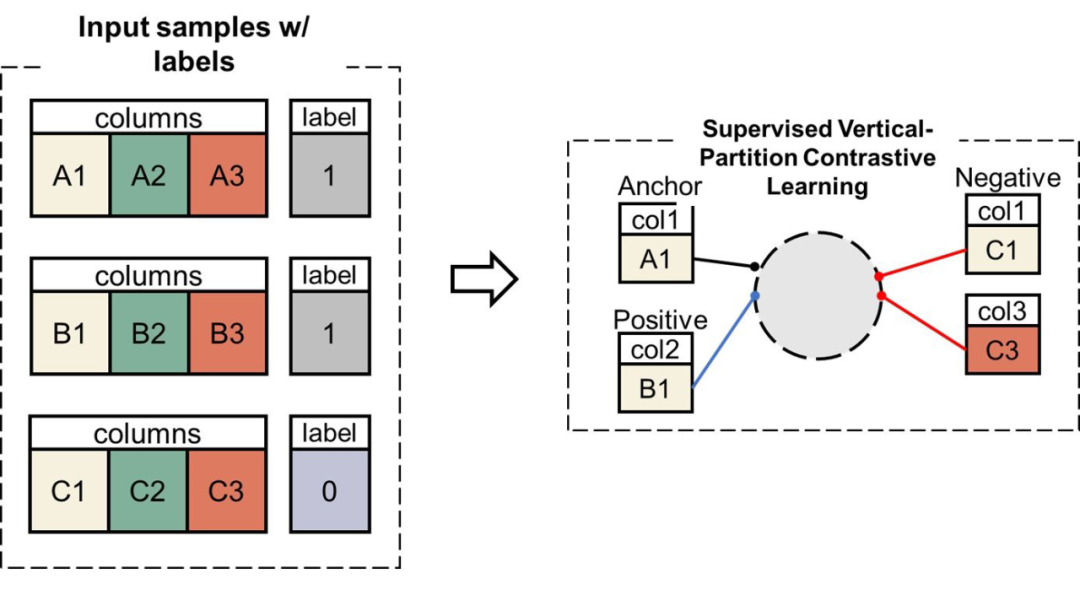
实验发现,这种 supervised CL 获得更好的预训练模型。

TransTab表现如何
接下来就是枯燥的实验环节啦。篇幅所限,只展示一小部分,更多的请参考论文。
5.1 预训练
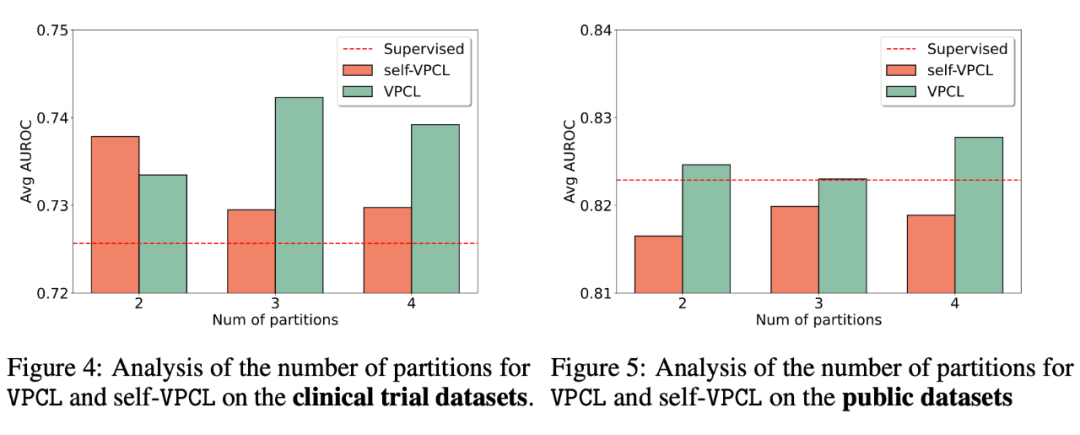
▲ TransTab预训练实验结果
左边是在多个临床试验数据集上进行预训练和 finetune 之后的结果。与单独在每个表格上训练的 baseline 相比,预训练带来了较大的平均提升。
右边是同样的实验,但是在一些公开表格数据上进行预训练和 finetune。因为公开数据来自多种领域,非常不同,我们看到 VPCL 还是升。
5.2 零样本预测
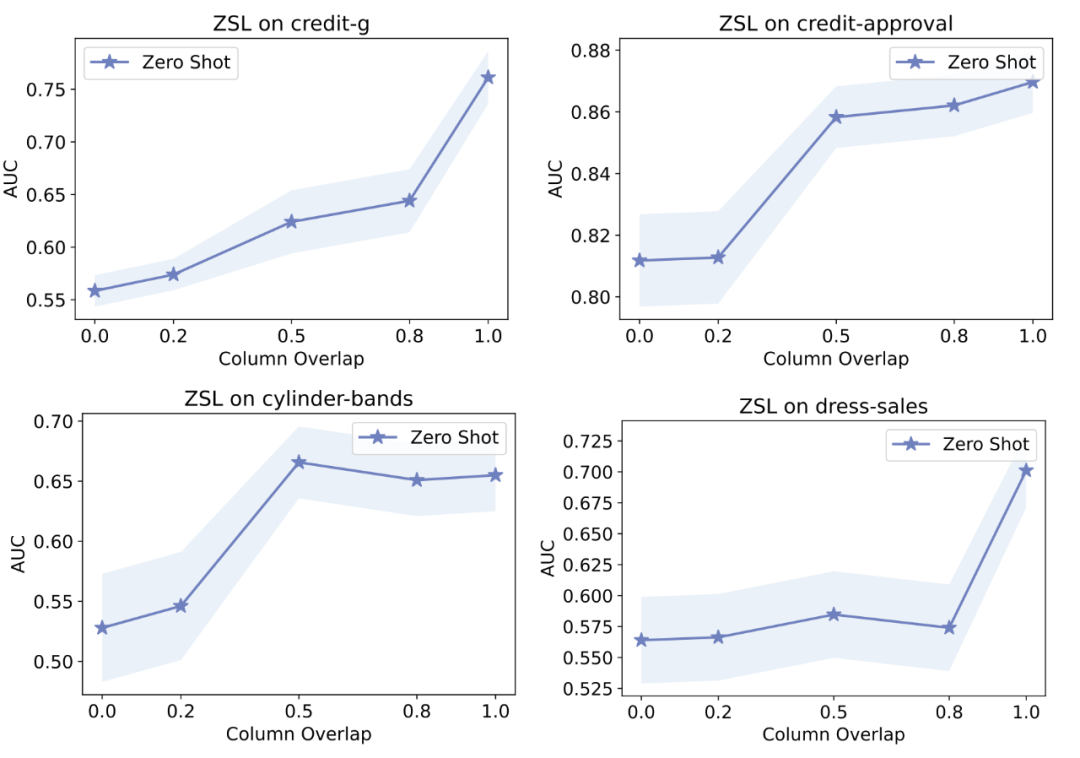
▲ TransTab零样本预测结果
我们尝试了在上游数据上 supervised learning 然后在下游表格上不训练直接预测。上图的 x 轴是上下游表格列之间重合的比例。我们可以看到,在上下游表格没有任何重合的情况下,TransTab 仍然能在多个表格上做出优于 random guess 的预测(AUC 达到 0.55 左右)。这说明了 TransTab 具有一定的零样本推断能力。

总结
总体来说,这篇文章的方法属于 simple and effective (高情商)。我们希望能够让 deep learning 在表格领域发光发热,就需要发挥 deep learning 做表征学习的能力。这篇文章初步探索了做表格学习的迁移和零样本预测。之后可以更多地利用 language modeling 的方法,来提升语义学习的能力,提升迁移能力和预测能力。

参考文献
[1] Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar. VIME: Extending the success of self-and semi-supervised learning to tabular domain. Advances in Neural Information Processing Systems, 33:11033–11043, 2020.
[2] Dara Bahri, Heinrich Jiang, Yi Tay, and Donald Metzler. SCARF: Self-supervised contrastive learning using random feature corruption. In International Conference on Learning Representations, 2022.
[3] Talip Ucar, Ehsan Hajiramezanali, and Lindsay Edwards. SubTab: Subsetting features of tabular data for self-supervised representation learning. Advances in Neural Information Processing Systems, 34, 2021.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编



