

CASIA
解锁更多智能之美
导读 |** **NeurIPS全称神经信息处理系统大会(Conference on Neural Information Processing Systems),是机器学习和计算神经科学领域的顶级国际会议。本文将介绍中科院自动化所团队在NeurIPS 2022中收录的11篇论文,欢迎各位读者一同交流研讨。
**01. **紫东太素:1.66亿超大规模高质量中文多模态预训练数据集
TaiSu: A 166M Large-scale High-Quality Dataset for Chinese Vision-Language Pre-training 多模态预训练是从大规模、弱相关的多模态数据对中学习多模态统一语义表征,在众多的下游任务中展现了卓越的泛化能力。多模态预训练模型的性能也与数据集的规模呈现正相关。然而,当前几乎所有的亿级以上的多模态数据集采用的是英文语料,中文超大规模且高质量的多模态数据集还比较稀缺,这限制了中文多模态智能的发展。为此,本文提出了一个新颖的数据自动获取与清洗全流程处理框架,并构建了当前最大规模的中文多模态数据集-紫东太素(TaiSu)。 紫东太素首次提出结合网络图文数据与生成的图像描述共同构建多模态数据集,相比先前的超大规模图文数据集,紫东太素是唯一一个为图像提供多个中文文本描述的数据集。此外,紫东太素针对多模态数据对的相关性采用了自监督的图文匹配性过滤。紫东太素在多个下游任务上取得了优异的表现,充分的实验表明紫东太素是一个具有应用前景的中文超大规模多模态数据集。

图1:紫东太素数据集构建框架

图2:基于紫东太素的预训练模型的生成样本示例
数据集相关链接: https://github.com/ksOAn6g5/TaiSu. 作者:Yulong Liu, Guibo Zhu, Bin Zhu, Qi Song, Guojing Ge, Haoran Chen, Guanhui Qiao, Ru Peng, Lingxiang Wu, and Jinqiao Wang(刘雨龙,朱贵波,朱斌,宋奇,葛国敬,陈浩然,乔冠辉,彭茹,吴凌翔,王金桥)
**02. **融合目标表达与语言知识的通用视觉基础模型
Obj2Seq: Formatting Objects as Sequences with Class Prompt for Visual Tasks 当前视觉任务的种类和输出形式多种多样,构建多专多能的通用视觉基础模型较为困难。其中最主要的挑战在于如何统一不同视觉任务的复杂输出形式。 在本文中,我们提出了一个通用视觉基础模型(简称Obj2Seq),该模型融合了语言预训练知识,并且利用seq2seq的思想统一视觉任务的输出形式,有效推动了覆盖多场景、多功能视觉模型的发展,并与文本等其他模态形成更加一致的结构。具体地,Obj2Seq以输入语言知识为指导,将单个目标物体当作最基本的单元,并将所有视觉任务统一定义为针对图像中物体的序列预测任务。我们将视觉任务拆分成两个阶段:识别由语言知识指定的目标物体以及生成描述这些物体的输出序列。依据不同任务需求,Obj2Seq可以灵活地修改输入的语言知识,以及输出序列的定义方式。从而,这一通用视觉模型能够广泛应用于不同的视觉任务中,构建统一的解决方案。Obj2Seq在多个视觉任务上均取得了优秀的性能,在MS COCO数据集目标检测、多标签分类、人体姿态估计任务中均超越了同级别单一任务模型的精度。
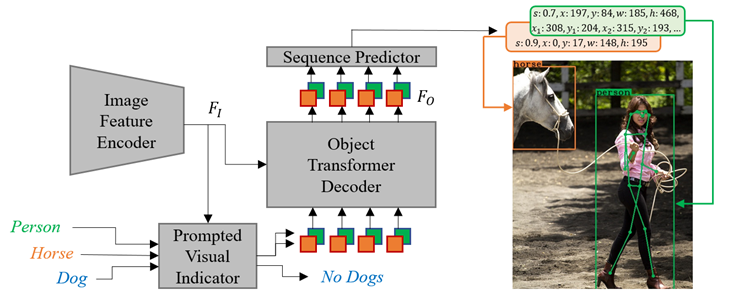
图1. 框架图
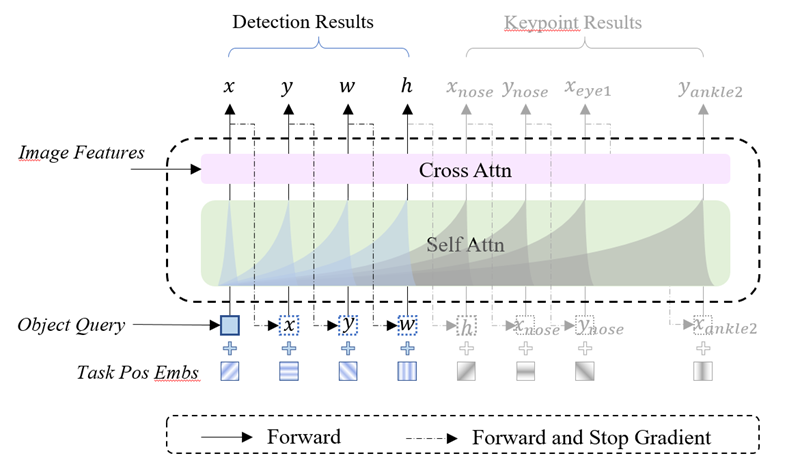
图2. 视觉序列输出结构图 代码已开源在: https://github.com/CASIA-IVA-Lab/Obj2Seq 作者:Zhiyang Chen, Yousong Zhu, Zhaowen Li, Fan Yang, Wei Li, Haixin Wang, Chaoyang Zhao, Liwei Wu, Rui Zhao, Jinqiao Wang, Ming Tang (陈志扬、朱优松、李朝闻、杨帆、李韡、王海鑫、赵朝阳、吴立威、赵瑞、王金桥、唐明)
**03. **全稀疏3D目标检测
Fully Sparse 3D Object Detection 本文提出了一种适用于自动驾驶场景的全稀疏3D目标检测器。通过稀疏实例识别模块克服了3D物体中心特征缺失的问题,避免了特征的致密化,同时也大大提高了点云算子的速度。全稀疏的结构使得本方法可以高效地实现超大范围的点云检测(感知半径>200m)。我们在Waymo Open Dataset和Argoverse 2 dataset上都取得了当前最佳的性能。
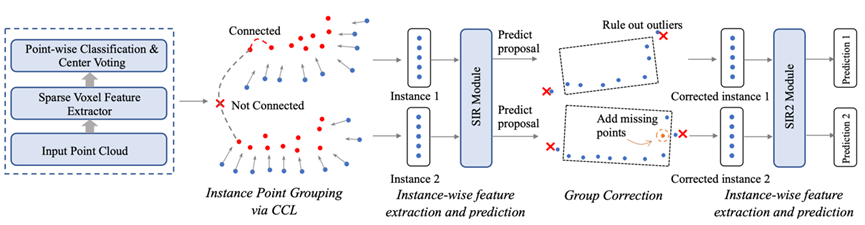
图1. 全稀疏检测器方法结构图
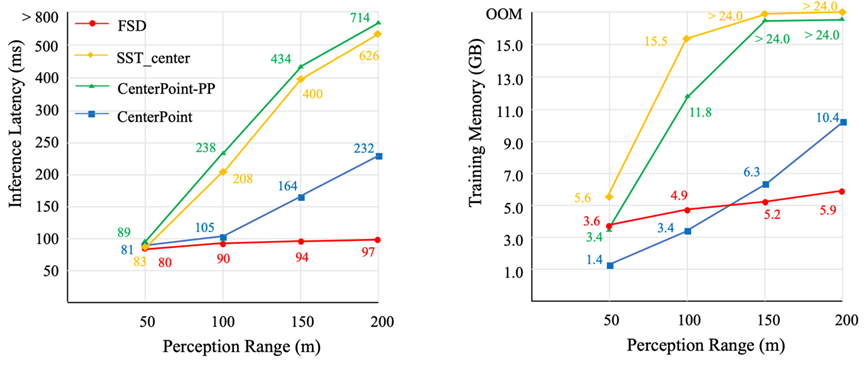
图2. 大感知范围下的效率对比 (图中FSD为本方法)
代码已开源在:https://github.com/BraveGroup/SST
作者:Lue Fan; Feng Wang; Naiyan Wang; Zhaoxiang Zhang (范略、王峰、王乃岩、张兆翔)
**04. **4D无监督物体发现
4D Unsupervised Object Discovery 无监督的物体发现具有重要的研究意义与应用价值。我们提出一种新的研究范式,4D无监督物体发现——从4D数据中(联合三维点云和图像视频序列)发现三维空间和二维图像上的物体。我们的方法充分利用了不同模态间的几何约束以及时序上的运动线索,通过三维聚类网络和二维定位网络的联合迭代优化,实现了复杂场景下无需任何标注的二维物体检测与三维实例分割。我们的方法在真实的、大规模驾驶场景数据集Waymo上进行测试,在物体检测和点云实例分割任务上均取得了优异的性能,远远超过10%人工标注的模型性能,显著缩小了无监督方法与全监督方法之间的差距,为无监督的物体发现提供了一种全新的研究视角。
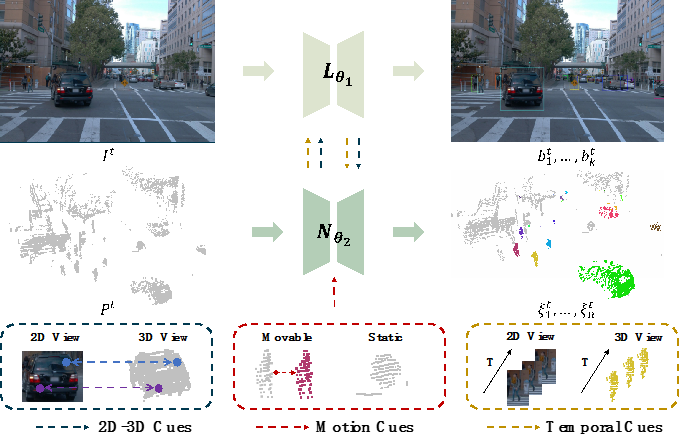

相关链接:https://github.com/Robertwyq/LSMOL 作者:Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang(王宇琪,陈韫韬,张兆翔)
**05. **基于多模态知识的少监督图文匹配
MACK: Multimodal Aligned Conceptual Knowledge for Unpaired Image-text Matching 近年来,基于大规模成对图文数据的预训练模型不断刷新图文匹配任务的最好结果,模型精度在多个国际公开数据库上基本接近饱和。与此不同,该工作探索了一个较为现实的新场景,即如果大量成对的图文匹配数据无法获取,那么我们该如何进行图文匹配?为了缓解成对监督信息的缺失,该工作构建了多模态对齐的语义概念知识,并以此为基础设计了知识推理与自监督学习方法,能够在不进行模型训练的情况下进行图文匹配。并且,该方法可以作为重排序方法来优化其它图文匹配模型的检索结果,能够进一步提升现有图文匹配预训练模型的精度。
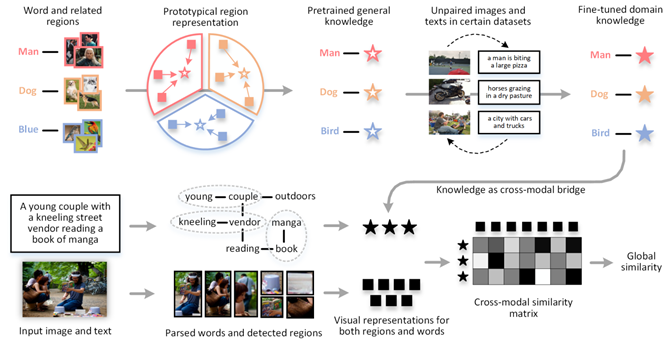
作者:Yan Huang, Yuming Wang, Yunan Zeng, Liang Wang(黄岩,王聿铭,曾宇楠,王亮)
**06. **基于样本相关性的神经网络模型指纹保护
Are You Stealing My Model? Sample Correlation for Fingerprinting Deep Neural Networks 模型水印旨在验证嫌疑模型是否窃取受害模型的模型参数或知识,在近年来逐渐受到人们的关注。之前的模型水印方法利用对抗样本的迁移性来识别窃取模型,但是这些方法一般对对抗训练敏感,模型窃取者可以通过对抗训练或者迁移学习规避模型所有者的模型指纹检测。 为了解决上述问题,我们提出了一种基于样本相关性检测的模型指纹算法(SAC)。具体来说,我们通过计算特定样本在受害模型以及嫌疑模型输出的相关性矩阵的L2距离来判断模型嫌疑模型是否从受害模型窃取相关知识。进一步地,为了降低不同模型中公有知识对于模型指纹识别的影响,我们利用错分样本或者数据增强样本作为模型输入,并提出了SAC-w和SAC-m两种算法。实验结果表明,SAC算法针对不同种类的模型窃取攻击均表现出优异的性能。
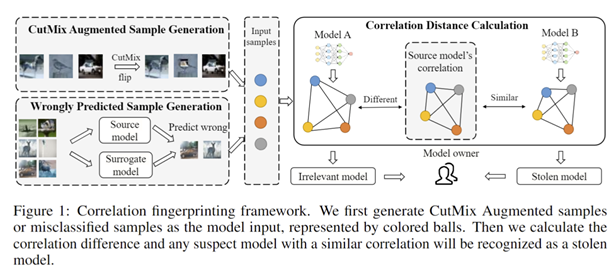
作者:Jiyang Guan, Jian Liang, Ran He(关霁洋、梁坚、赫然)
**07. **正交Transformer:一种基于Token正交化的高效视觉Transformer主干网络
Orthogonal Transformer: An Efficient Vision Transformer Backbone with Token Orthogonalization 视觉Transformer中的自注意力机制,可以有效建模图像中的全局依赖关系,但对于检测、分割等密集预测任务,往往面临计算开销大的问题。目前对自注意力机制的改进工作,难以同时兼顾局部特征相关性和全局依赖建模。 在本文中,我们提出了一种正交自注意力机制,将视觉Token特征变换到低分辨率的正交空间再进行自注意力计算,每一个正交Token都可以感知到所有的视觉Token,从而有效建模局部特征相关性和全局特征依赖关系。我们提出了一种内生的正交变换矩阵来保证Token特征的正交性,该正交变换矩阵可以直接作为网络参数优化更新而无需引入额外的正交约束监督。此外,我们还提出了一种基于位置编码的多层感知机并搭建了一个层次化的主干网络,称为正交Transformer网络。我们提出的正交Transformer在图像分类、目标检测、实例分割和语义分割等领域均取得了超越SOTA方法的性能。
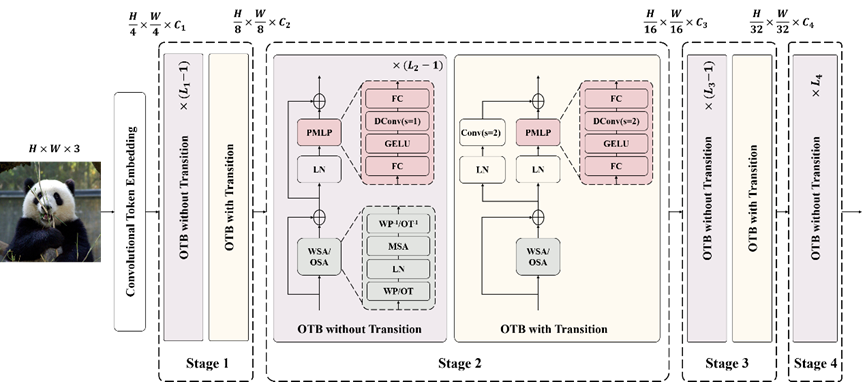
图1. Transformer的网络结构
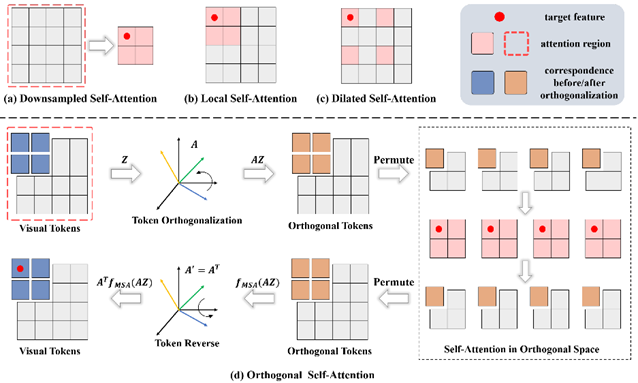
图2. 正交自注意力机制与其他自注意力机制比较
作者:Huaibo Huang, Xiaoqiang Zhou, Ran He (黄怀波、周晓强、赫然)
**08. **基于实例查询与候选框传播的在线视频实例分割
InsPro: Propagating Instance Query and Proposal for Online Video Instance Segmentation 视频实例分割旨在同时完成视频中的物体实例分割和跟踪。之前的方法采用显式的实例关联方法,即逐帧或逐片段地预测物体实例,再通过额外的跟踪模型或匹配算法,关联相邻帧或片段上的实例。此类方法增加了系统的复杂性,并且无法充分利用视频中的时序线索。 在本文中,我们设计了一个简洁、快速且有效的在线视频实例分割框架。该框架依靠实例查询和候选框传播机制,以及几个专门开发的组件,可以隐式执行准确的帧间实例关联。具体来说,我们基于从先前帧传播的实例查询-候选框对生成当前帧的物体实例。该实例查询-候选框对与一个特定实例跨帧绑定,当用其预测当前帧的物体实例时,不仅生成的实例会自动与先前帧的关联,而且模型在预测同一物体时获得了良好的先验。通过这种方式,我们实现了与分割并行的隐式实例关联,并高效地利用了视频中的时序线索。实验结果表明,本工作提出的方法在多个数据集上实现了比基准方法更优的性能,验证了方法的有效性。
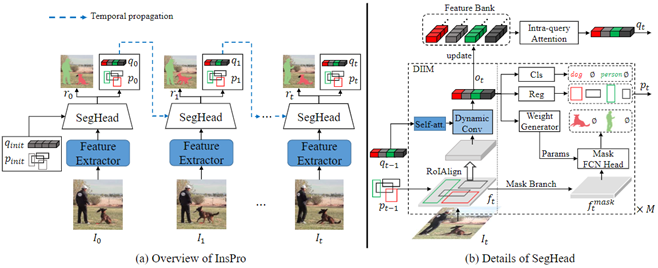
作者:Fei He, Haoyang Zhang, Naiyu Gao, Jian Jia, Yanhu Shan, Xin Zhao, Kaiqi Huang (何飞,张昊飏,高乃钰,贾健,单言虎,赵鑫,黄凯奇)
**09. **基于自适应门控的统合脉冲神经元
GLIF: A Unified Gated Leaky Integrate-and-Fire Neuron for Spiking Neural Networks 脉冲神经网络(Spiking Neural Network, SNN)自提出以来就被认为是第三代人工智能网络,从而被广泛研究。它最核心的特殊点就在于仿生的激活单元,即脉冲神经元。这几年,随着各种研究场景的不同,各种不同的脉冲神经元建模被提出。这些不同的脉冲神经元在不同神经行为上拥有相对不同的生物特征。 受到大脑神经元层级结构差异性的启发,我们提出了Gated LIF模型,将这些不同的特征都统合起来,并利用门控机制将同一个神经行为上的对偶特征进行平衡。得益于参数化技术和反向传播的充分利用,基于Gated LIF的SNN在每个通道上都会学得神经元特性完全不同的脉冲神经元,进而极大地提升网络的内部异质性。我们在CIFAR、ImageNet、CIFAR10-DVS数据集上进行验证,均取得了SOTA。
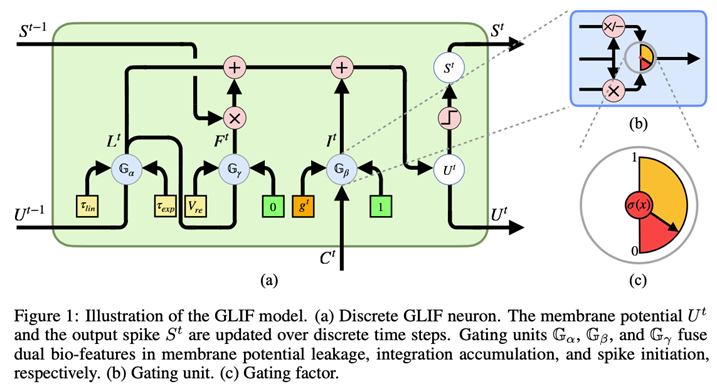
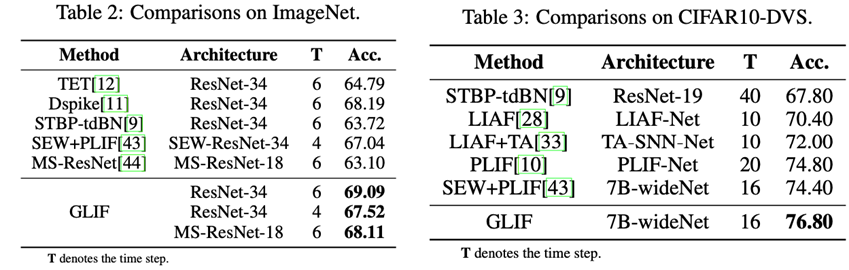
作者:Xingting Yao,Fanrong Li,Zitao Mo,Jian Cheng(姚星廷,李繁荣,莫子韬,程健)
**10. **PKD:基于皮尔逊相关系数的通用目标检测知识蒸馏框架
PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient 知识蒸馏(KD)是一种在目标检测中广泛应用的模型压缩技术。然而,目前对于如何在异构检测器之间进行知识蒸馏还缺乏相关研究。本文通过实验证明,尽管模型结构、检测头和标签分配算法不同,来自异构教师检测器的表达能力更强的FPN特征依然可以改善学生检测器。然而,直接对齐学生和教师网络提取的特征存在两个问题。首先,教师和学生网络特征幅值上的差异可能会对学生施加过于严格的约束。其次,激活程度较高的FPN层和通道会主导蒸馏损失的梯度,这将压倒知识蒸馏中其他特征的影响,并引入大量噪声。 针对上述问题,我们提出利用皮尔逊相关系数进行特征对齐,聚焦于来自老师的相关信息,放松对特征幅值大小的约束。我们的方法性能优于现有的针对目标检测的知识蒸馏方法,并适用于同构和异构学生-教师检测器对。此外算法收敛速度也较现有方法更快,且只有一个超参数并对参数设置不敏感,易于实际部署。在MaskRCNN-Swin检测器的指导下,基于ResNet-50的RetinaNet和FCOS检测器在COCO2017上的mAP分别达到41.5%和43.9%,分别比基线高4.1%和4.8%。

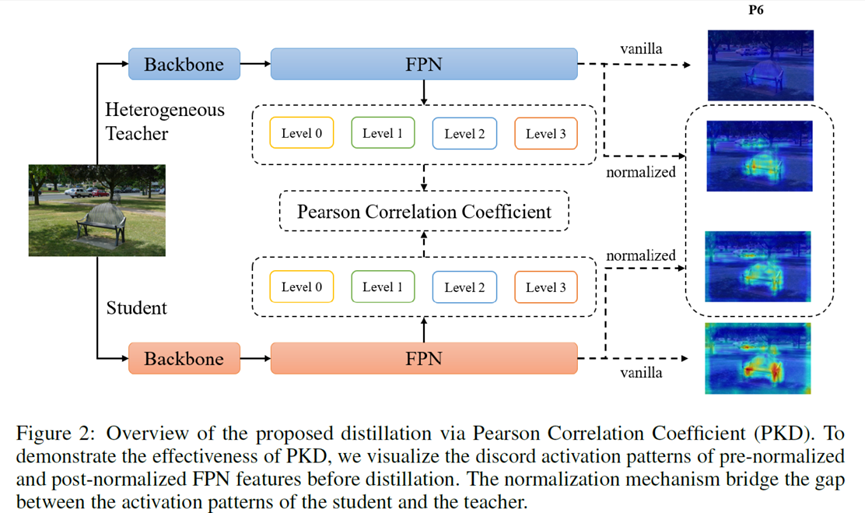
相关链接:https://arxiv.org/abs/2207.02039 作者:Weihan Cao,Jianfei Gao,Anda Cheng,Ke Cheng,Yifan Zhang,Jian Cheng(曹巍瀚、张一帆、高剑飞、程安达、程科、程健)
**11. **一种元强化学习中梯度偏差的理论理解
A Theoretical Understanding of Gradient Bias in Meta-Reinforcement Learning 基于梯度的元强化学习(GMRL)是指一种双层优化过程的方法,其中外层元学习器引导内层基于梯度的强化学习器实现快速适应。在本文中,我们提出了一个统一的框架来囊括所有GMRL 算法的变体,并指出目前 GMRL 采用的随机元梯度估计器实际上是有偏的。这种元梯度估计偏差有两个来源:1)由双层优化问题结构引起的嵌套优化偏差,并指出这种偏差关于内层更新步骤 K,学习率α,估计方差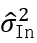
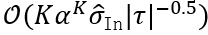
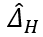
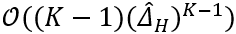
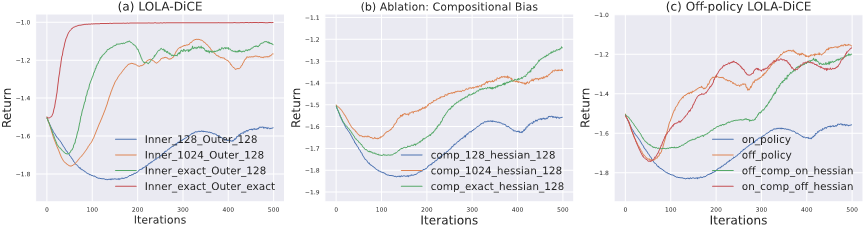
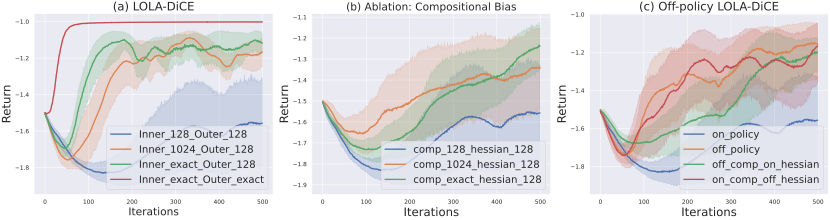
相关链接:https://arxiv.org/abs/2112.15400 作者:Bo Liu, Xidong Feng, Jie Ren, Luo Mai, Rui Zhu, Haifeng Zhang, Jun Wang, Yaodong Yang (刘博 冯熙栋 任杰 麦络 朱锐 张海峰 汪军 杨耀东)

