医疗多模态预训练:如何利用非天然配对的医疗图像和文本做对比学习?

©PaperWeekly 原创 · 作者 | 王子丰
单位 | 伊利诺伊大学香槟分校
研究方向 | AI for healthcare
EMNLP 2022 一共接收了我的三篇文章(两篇主会一篇 findings),分别是:
[1] MedCLIP: Contrastive Learning from Unpaired Medical Images and Texts
[2] PromptEHR: Conditional Electronic Healthcare Records Generation with Prompt Learning
[3] Trial2Vec: Zero-Shot Clinical Trial Document Similarity Search using Self-Supervision
今天介绍的是 [1] 这篇工作。做的内容是最近大火的图像文本联合预训练(Vision-Language pretraining)在医疗领域的应用。这篇文章的亮点主要是:
1. 探索了如何处理 False Negative 样本对预训练的影响;
2. 探索了怎么样在样本有限的情况下,最大化的扩充正负样本对来提高多模态预训练的 data efficiency。

收录会议:
论文链接:
代码链接:
代码和预训练权重见上方链接。那么接下来就是正文啦。

前情提要
CLIP [1](Contrastive Language-Image Pre-training)即图文对比预训练,是这推动这两年多模态领域大火的奠基之作。相信大家都已经比较熟悉了。
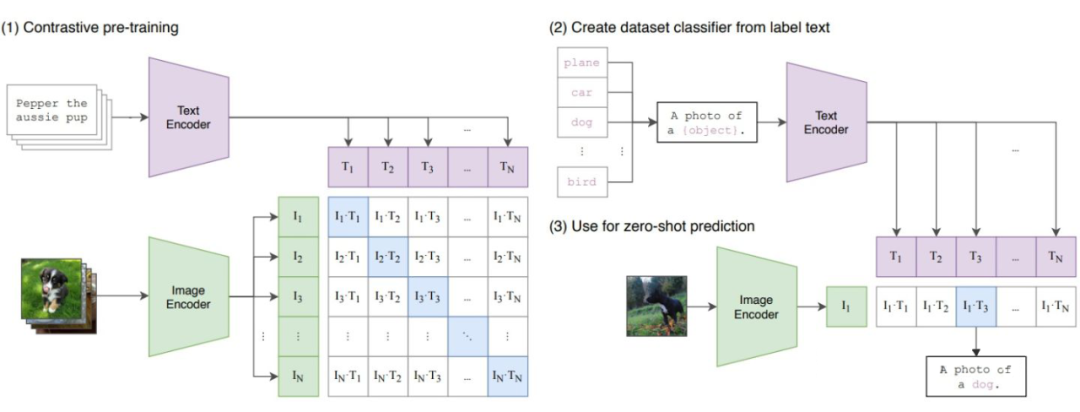
▲ CLIP 的示意图,来自原论文
在 4 亿个网络图片和对应的标题的加持下,CLIP 使用简单的 InfoNCE loss 大力出奇迹,在多个图像识别任务上的零样本预测能力吊打了很多的监督学习模型。这个特性再次强化了我们对于深度学习 more data, more intelligence 的印象。紧接着,就出现了非常多在 CLIP 预训练模型的基础上整一些花活的文章,比如在视频文本上预训练,在音频文本上预训练,等等。

CLIP在医疗数据
医疗相关也有可用的图像和文本的配对数据集。最知名的应该是一些列胸片和临床报告的配对数据,比如 CheXpert, MIMIC-CXR 等。早在 CLIP 之前,ConVIRT [2] 就已经展示了 InfoNCE 式对比学习在医疗图文数据上的能力。但是不幸的是,由于数据不够大,表现不够 excited,这篇文章没有搞出一个大新闻,最终才在今年的 MLHC 会议上发表。当时还让作为作者之一的 Christopher Manning 大佬发推吐槽了一番。
▲ Manning关于ConVIRT的推特
简单来说,ConVIRT 的思路和 CLIP 是一致的。在我们有胸片和对应的临床报告文本时,我们可以把每张胸片和对应的报告中的句子作为正样本对,而跟其他的报告中的句子作为负样本对。这样就可以在一个图片编码器(ResNet)和文本编码器(BERT)的加持下,愉快地做对比学习了。那么和 CLIP 不同的是,ConVIRT 并没有考虑零样本预测的情况,而只是利用预训练的图片编码器加上一个全连接层做分类器,然后还是加标签数据做微调那一套。
在 ConVIRT 之后,Stanford 又出了一篇 GLoRIA [3],在之前工作的基础上加了很多注意力(attention)机制。即考虑了图像编码器中间层里的特征图和文本中每个词之前的 attention,得到一个经过加权的局部特征(local representation)。相对应的就是原本的图像和文本特征,在文中叫做全局特征(global representation)。也是在这篇文章中,第一次实现了医疗图片在图文预训练之后的基于 prompt 的零样本预测。

为什么我们需要MedCLIP
写到这里,终于该轮到我们的工作 MedCLIP 出场了。MedCLIP 要解决的问题,我想可以用一张图说明。
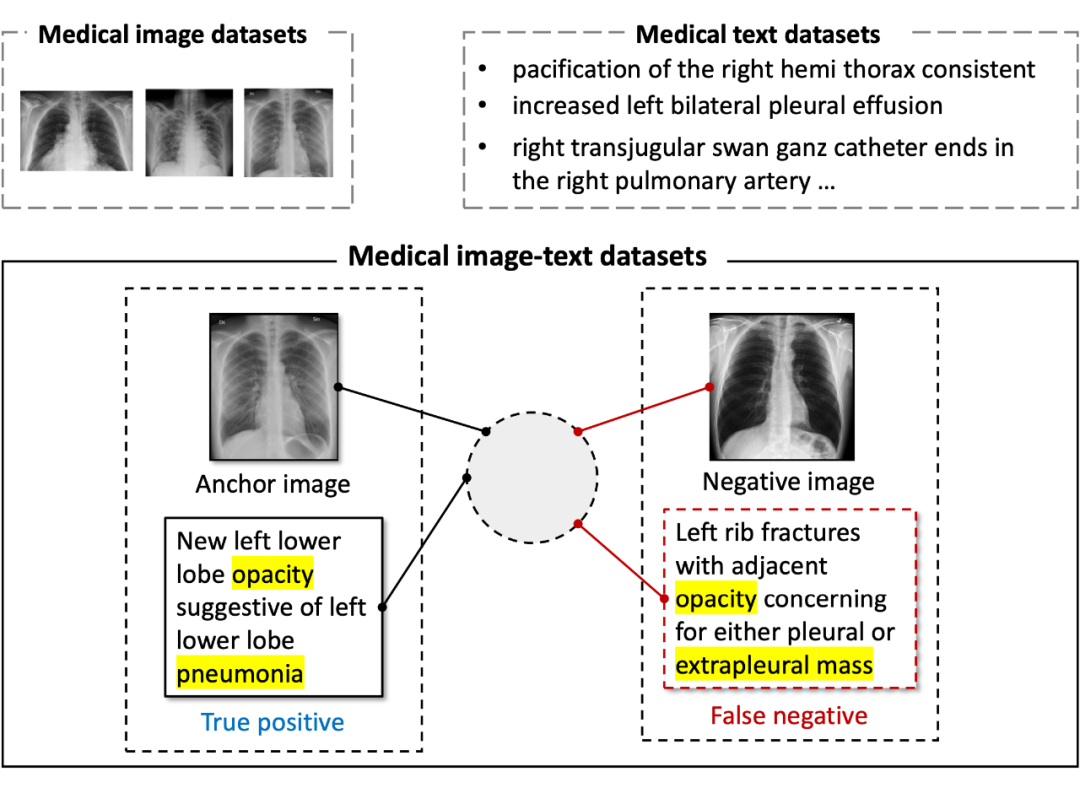
▲ MedCLIP 要解决的问题:1)如何解决只能利用配对图文训练的限制;2)如何解决由于只使用配对图文作为正样本带来的假阴性样本问题。
首先,跟 CLIP 相比,医疗领域的图像文本配对总量要小的多。CLIP 可以在 4 亿数据上充分训练,但是,X-ray 和配对的报告的公开数据集最大的也只有数十万这个级别,分别是 CheXpert(20万)和 MIMIC-CXR(37万)。这就严重限制了模型的能力。同时,我们其实还有大量的纯医疗图像或者纯文本数据。由于使用 CLIP 的对比学习方法,模型只能利用天生配对的图片+报告来训练。这就导致了医疗图文训练的天生在数据量方面的跛腿,从而很难达到 CLIP 那样的高度。
另外,由于假定只有配对的图片和文本是正样本,其它的都被当作负样本,很多的潜在正样本都被当作了负样本,即 False Negatives。同 CLIP 使用的日常图文不同,X-rays 之间的差别其实很小。在没有经过专业训练的普通人眼里几乎分辨不出来任何差别。并且,很多报告可能都描述了类似的症状和病情,但都被一律当作了负样本处理。这就导致了模型在训练过程中感觉到了疑惑:图片 1 和文本 B 明明匹配,却要求把它们的特征分开。这大大影响了学习到的表征的质量。

MedCLIP怎么做
针对上面的这两个问题,我们希望能够解耦(decouple)图片和文本的配对关系,转而用一个人工构建的弱标签系统作为匹配图片和文本的工具。见下图。
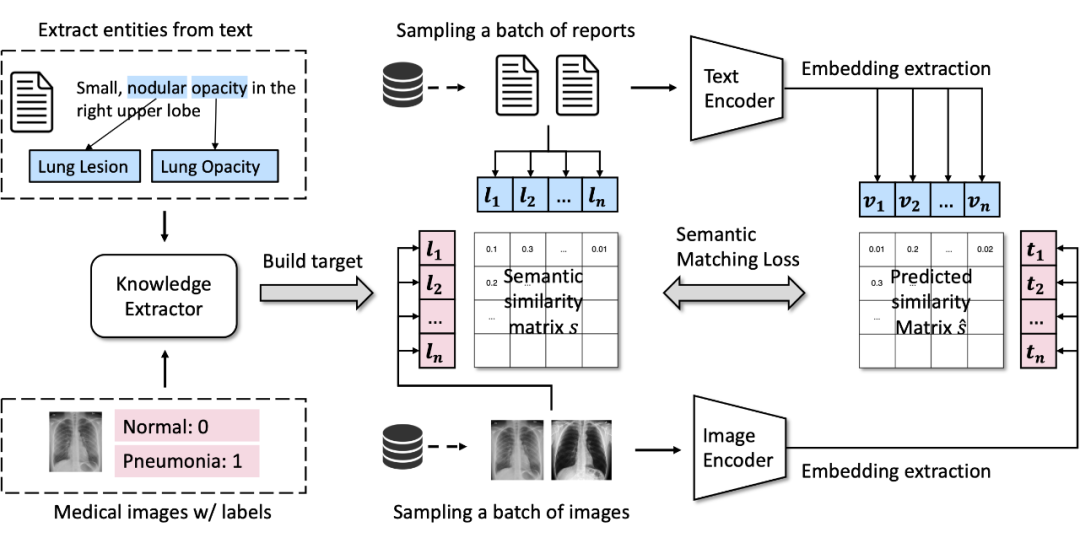
▲ MedCLIP的基本架构
咱们这里主要关注最左边这一块。对于每条文本,我们都可以抽取它之中存在的一些关键实体,作为这条文本的弱标签。对于图片,我们有它们的标签,因为它们可能来源于已经标注好的纯图像数据集,或者有对应的报告,那么就用报告的标签作为它的标签。
在获得这两个标签后,对比学习的目标就不再是一个对角的 identity 矩阵,而是两个标签向量的内积,作为图片和文本之间的一个相似度。

实验结果
实验比较多,这里只放一个我认为最重要的。见下图。
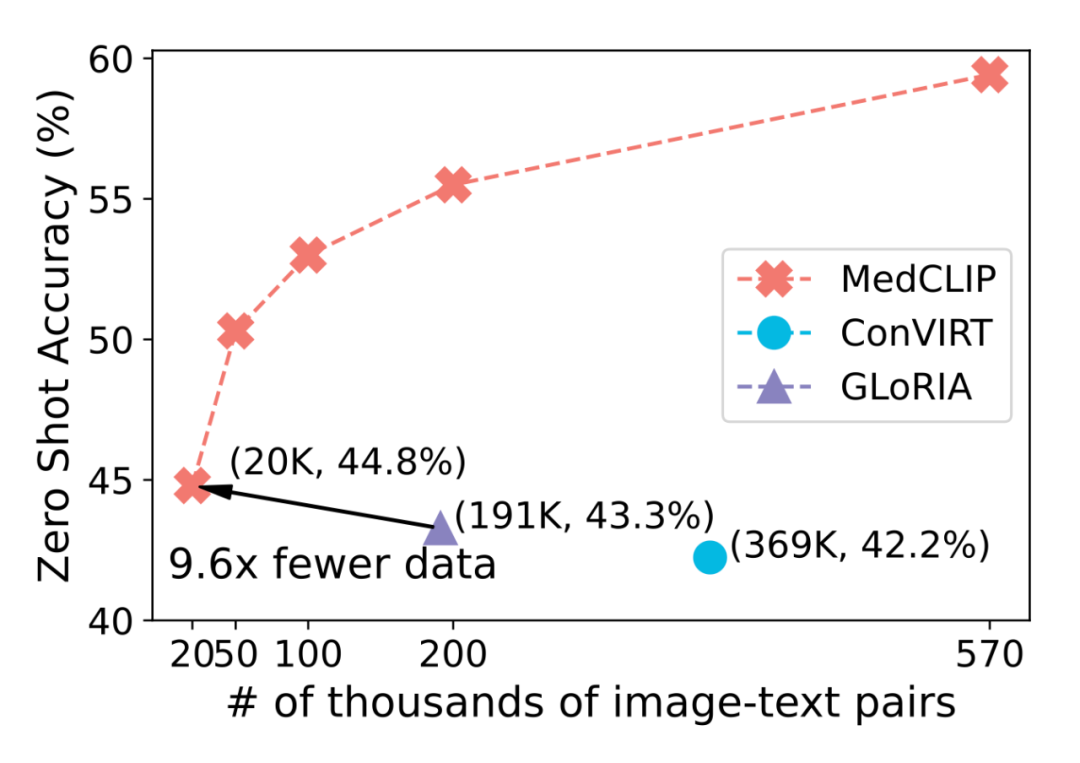
可以看到,相比 GLoRIA [4],我们的方法在只用 20K 数据的时候就已经达到了更强的零样本预测能力。随着样本量的增大,MedCLIP 的表现也在逐渐scale。可以期待如果更多的数据可用,它的表现还可以更好。值得注意的是,在我们的实验里,CheXpert+MIMIC-CXR 作为预训练数据集。但是,因为 MedCLIP 的特性,我们还可以考虑加入更多的图片数据进来。

总结
这篇文章的方法和思想非常简单,就是一个利用外部知识来构建文本和图像的弱标签,从而能够解耦图片和文本对,做到指数级扩大可用的正负样本。同时,利用弱标签,我们能够甄别出很多的 False Negative 样本,从而提高模型的表征学习能力。
后续的工作可以考虑如何进一步提高弱标签的质量,以及在有噪弱标签的情况下进一步提高预训练的鲁棒性。或者,在模型架构主要是图片编码器一侧提升设计,让模型更多的抓住医疗图片的重要区域,从而提升表征的判别能力。

参考文献
[1] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR. https://arxiv.org/pdf/2103.00020.pdf
[2] Zhang, Y., Jiang, H., Miura, Y., Manning, C. D., & Langlotz, C. P. (2020). Contrastive learning of medical visual representations from paired images and text. arXiv preprint arXiv:2010.00747. https://arxiv.org/pdf/2010.00747.pdf
[3] Huang, S. C., Shen, L., Lungren, M. P., & Yeung, S. (2021). Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 3942-3951). https://openaccess.thecvf.com/content/ICCV2021/papers/Huang_GLoRIA_A_Multimodal_Global-Local_Representation_Learning_Framework_for_Label-Efficient_Medical_ICCV_2021_paper.pdf
[4] 关于GLoRIA:我们使用了其原代码提供的预训练权重。由于作者并没有公开他的测试集,我们重新切分了训练集和测试集,所以结果和原文中报告的有比较大的差异。而且,GLoRIA源代码里有一个奇怪的对batch内作平均的操作,导致模型测试结果严重受到batch size的影响。我们的实验里,这个对于batch内求平均的操作被移除。https://github.com/marshuang80/gloria/blob/416466af1036294301a872e4da169fefc137a192/gloria/gloria.py#L270
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」



