【泡泡一分钟】一种端对端的深度立体匹配方法 (ICCV-3)
每天一分钟,带你读遍机器人顶级会议文章
标题:End-to-End Learning of Geometry and Context for Deep Stereo Regression
作者:Alex Kendall Hayk Martirosyan
Saumitro Dasgupta Peter Henry Ryan Kennedy Abraham Bachrach Adam Bry
来源:ICCV 2017
播音员:包子
编译:刘彤宇
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

今天为大家带来的文章是——一种端对端的深度立体匹配方法,该文章发表于ICCV2017。
我们提出了一种新颖的深度学习架构,用于校正后立体图对的视差回归问题。我们利用几何知识构建使用深度特征表示的组成成本量,充分利用3D卷积提取上下文的纹理信息。视差值通过差分soft argmin操作规范化.同时,我们也实现了一种不需要后期处理和规范化就能达到亚像素精度的端到端的方法。我们在Scene Flow和KITTI数据集上对这种方法进行评估,同时设置了一个最先进的基准测试程序,最后结果显著快于相比对的方法。
通常来说,我们是在cost volume中进行argmin操作,估算出cost volume的深度偏移量。然而,这种操作有两个问题:一、这是离散的,不能产生亚像素深度偏差估计;二、这不是差分的,因此不能够使用反向传播。为了克服这些限制,本文定义了soft argmin,一个完全的差分运算并且有产生平滑深度估计的能力。
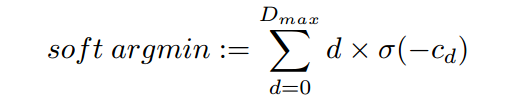
首先,将预测成本Cd(对于每个视差d)从成本量转换为概率量,取各个值的负值;接着,通过soft argmin运算把视差维度上的概率量规范化;最后,以规范化后的量作为权重,对每个d进行加权相加。
本论文的创新之处就是用微分方式建立几何代价体用于回归模型。从下图的结果来看,该方法估计的深度已经非常接近groundtruth。

图示从左到右:输入的左双目图,该文章深度估计结果,groundtruth
Abstract
We propose a novel deep learning architecture for regressing disparity from a rectified pair of stereo images.We leverage knowledge of the problem’s geometry to form a
cost volume using deep feature representations. We learn to incorporate contextual information using 3-D convolutions over this volume. Disparity values are regressed from the cost volume using a proposed differentiable soft argmin operation, which allows us to train our method end-to-end to sub-pixel accuracy without any additional post-processing or regularization. We evaluate our method on the Scene Flow and KITTI datasets and on KITTI we set a new stateof-the-art benchmark, while being significantly faster than competing approaches.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


