如何安全地吃掉悬崖边上的苹果?DeepMind&OpenAI给出3D版安全强化学习答案
行早 发自 凹非寺
量子位 | 公众号 QbitAI
DeepMind&OpenAI这回联手展示了一手安全强化学习模型的好活。
他们把二维的安全RL模型ReQueST推向了更实用的3D场景中。
要知道ReQueST原来只是应用在导航任务,2D赛车等二维任务中,从人类给出的安全轨迹中学习如何避免智能体“自残”。
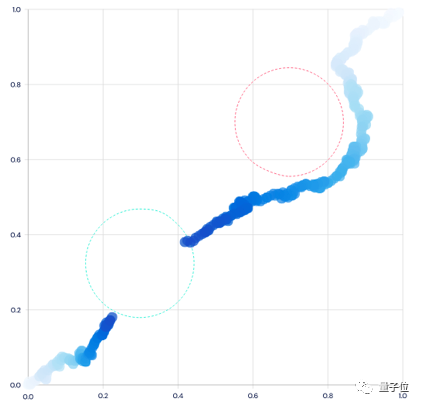

△图注:原来ReQueST的二维导航任务(避开红色区域)和赛车任务
但是在实际的3D环境中问题更为复杂,例如执行任务的机器人需要在工作中避障,自动驾驶的汽车需要避免开到沟里去。
但是在实际的3D环境中问题更为复杂,例如执行任务的机器人需要在工作中避障,自动驾驶的汽车需要避免开到沟里去。
那么问题来了,用于2D任务的ReQueST在复杂的3D环境中还能行吗?在3D环境中人类给出的安全轨迹数据的质和量还能满足训练的需要吗?
针对这两个问题,DeepMind和OpenAI拿出了更复杂的动力模型和融入了人类反馈的奖励模型,成功将ReQueST迁移到3D环境中,向应用推进了一步。
并且安全性也有所提升,实验中智能体不安全行为数量减至baseline的十分之一。
怎么能直观地感受一下?我们到模拟3D环境中看一看。

在上图的场景中,房间左上侧是一个悬崖,智能体需要在房间两侧指示灯绿色消失之前,尽量吃到三个苹果。
其中一个苹果还需要踩按钮开门才能吃到。
在展示的视频中,智能体踩住按钮,打开闸门,成功吃到被关住的苹果,一套操作行云流水。

我们来看看它是怎么做到的。
3D版安全强化学习模型如何训练
在ReQueST的基础上,DeepMind和OpenAI需要解决的问题就是适用于3D场景的动力模型和奖励模型。
我们先从整体的流程上看一下这两者的角色。
如下图所示,是新模型对于吃苹果任务的训练流程。
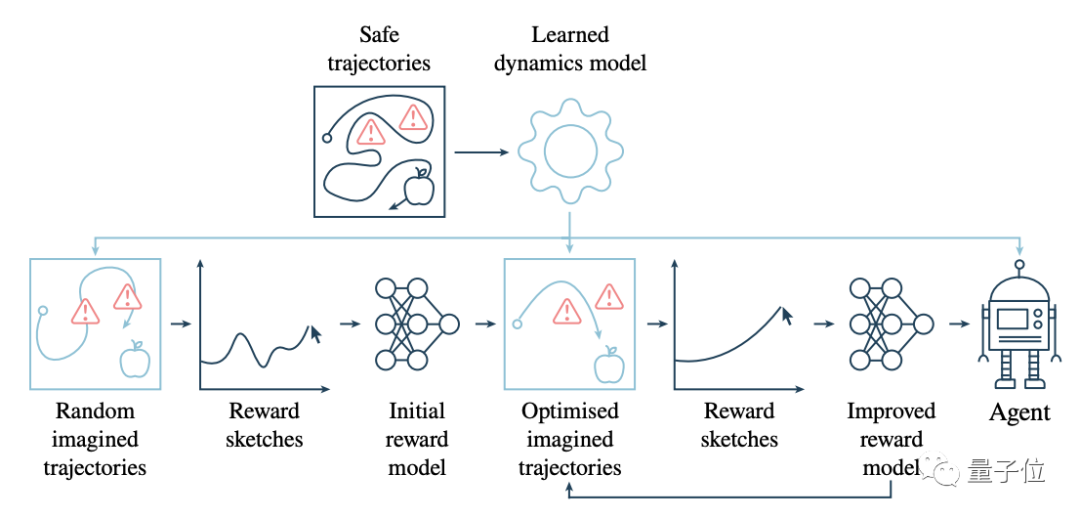
浅蓝色框代表的是动力模型参与的步骤。从上面一排开始,由人提供一些安全的轨迹,避开红色的危险区域。
根据这些训练出动力模型,然后用它生成一些随机的轨迹。
接着到下面一排,让人类根据这些随机的轨迹,以奖励草图的方式提供反馈,再用这些奖励草图,训练初始的奖励模型,并依此不断地优化两者。
接下来我们分别介绍这两个模型。
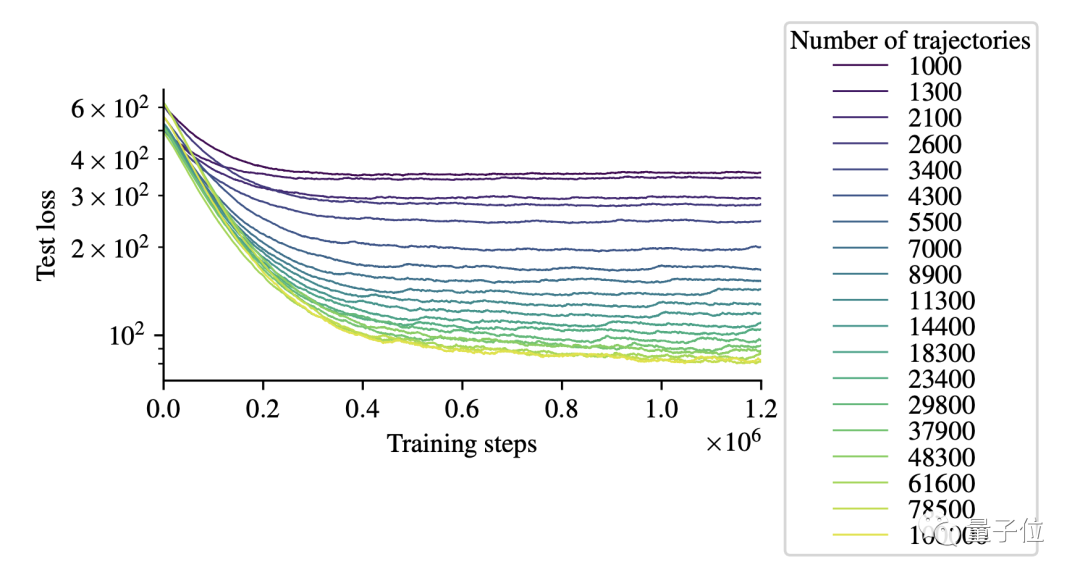
这次DeepMind和OpenAI使用的动力模型使用LSTM依据动作序列和过去的图像观测预测未来的图像观测。
模型和ReQueST中的类似,就是编码器网络和反卷积解码器网络更大了点,并使用真实图像观测和预测值的均方误差损失进行训练。
最重要的是,这种损失建立在对每个步骤的未来多个步骤的预测上,从而使动力模型在长时间的部署中也能保持连贯性。
得到的训练曲线如下图所示,横轴代表步数,纵轴代表损失,不同颜色的曲线代表不同量级的轨迹数量:
此外,在奖励模型部分,DeepMind和OpenAI训练了一个220万参数的11层残差卷积网络。
输入为96x72的RGB图像,输出一个标量奖励预测,损失也是用均方误差。
在这个网络里,人类反馈的奖励草图也起到了很重要的作用。
奖励草图简单来说就是人工给奖励值打分。
如下图所示,图中上半部分就是人给出的草图,当下半部分的预测观察中有苹果的时候,奖励值就是1,如果苹果逐渐从视野中淡出,奖励就变成-1。

以此来调整奖励模型网络。
3D版安全强化学习模型效果如何
接下来我们来看看新模型和其他模型以及Baseline的对比效果如何。
结果如下图所示,不同的难度对应的是场景大小的不同。
下图左边是智能体从悬崖摔下去的次数,右边是吃掉苹果的数量。
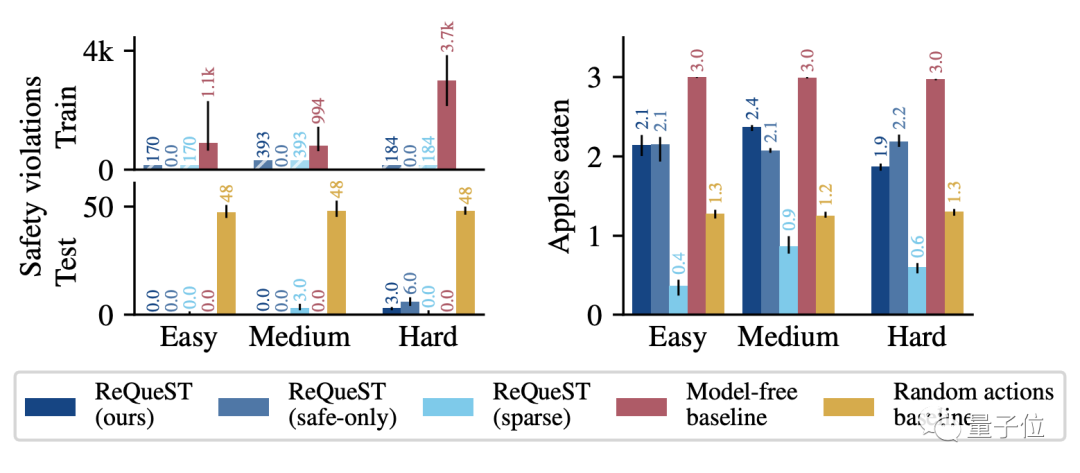
需要注意的是,图例中的ReQueST(ours)代表训练集中包含了人类提供错误路径的训练结果。
而ReQueST(safe-only)代表训练集中只使用安全路径的训练结果。
另外,ReQueST(sparse)是不用奖励草图训练的结果。
从中可以看出,虽然Model-free这条baseline吃掉了所有的苹果,但是牺牲了很多安全性。
而ReQueST的智能体平均能吃掉三个苹果中的两个,并且跌落悬崖的数量只是baseline的十分之一,性能比较出众。
从奖励模型的区别上来看,奖励草图训练的ReQueST和稀疏标签训练的ReQueST效果相差很大。
稀疏标签训练的ReQueST平均一个苹果也吃不到。
看来,DeepMind和OpenAI抓的这两点确有改善之处。
参考链接:
[1]https://www.arxiv-vanity.com/papers/2201.08102/
[2]https://deepmind.com/blog/article/learning-human-objectives-by-evaluating-hypothetical-behaviours
— 完 —
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



