3D模型“换皮肤”有多简单?也就一句话的事
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
给灰突突的3D模型加“新皮肤”,这事儿能有多简单?
现在,只需要一句话就能搞定。
看!
一个普通小台灯,给个“Brick Lamp”的描述,瞬间变“砖块灯”:
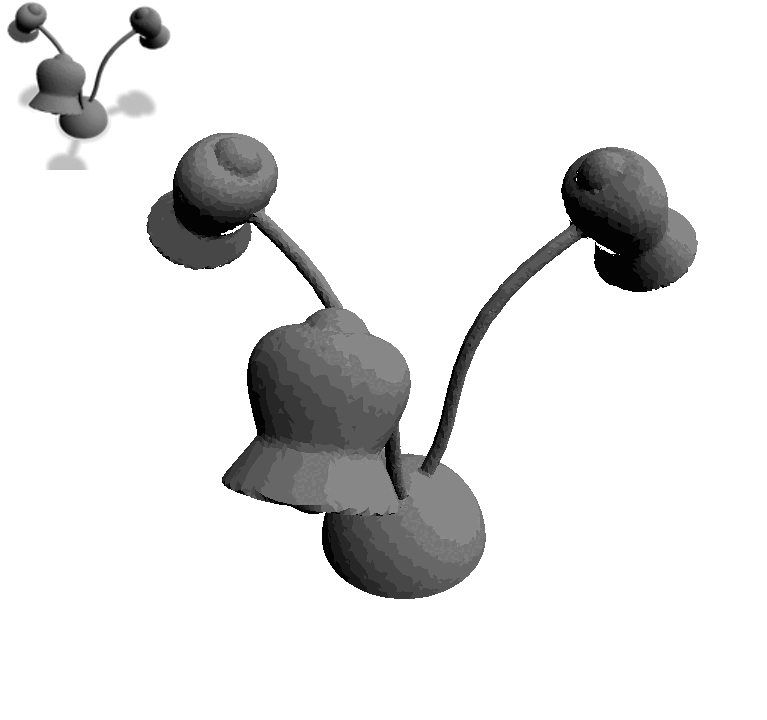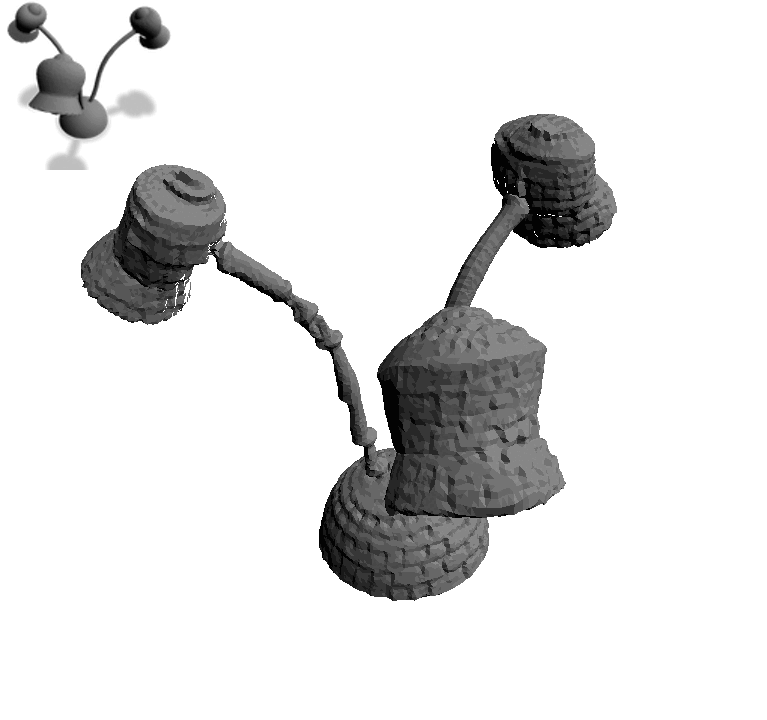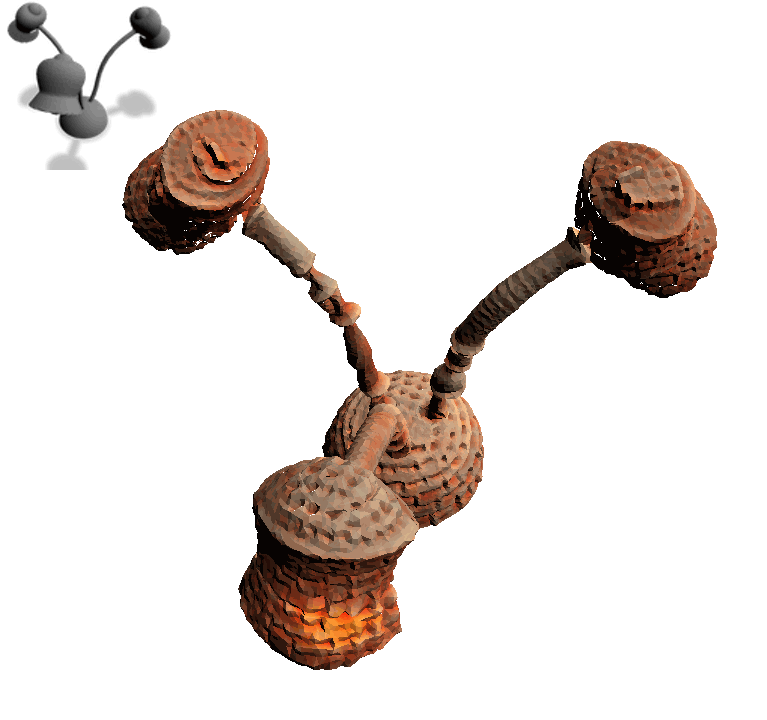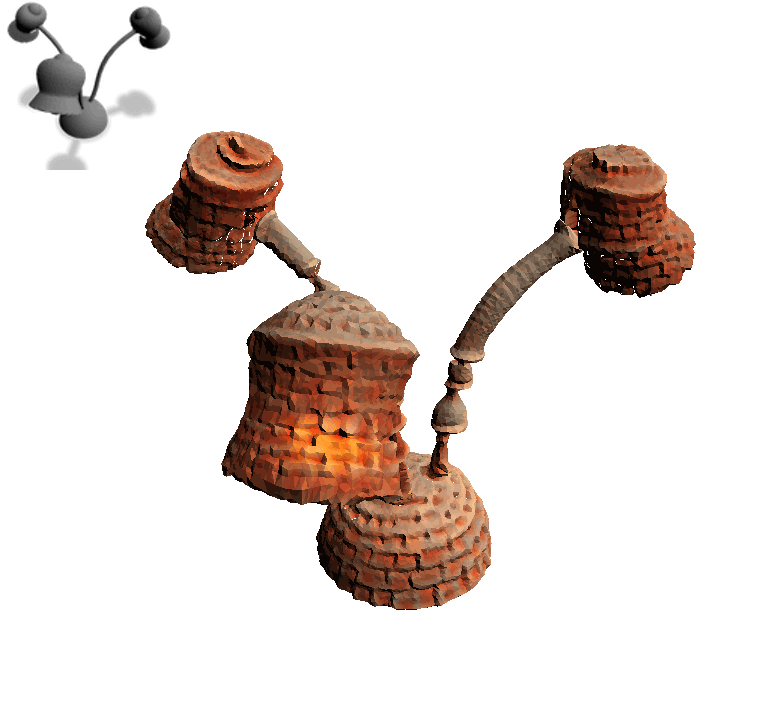
一匹灰色小马,加上“Astronaut Horse”,摇身一变就成了“宇航马”:
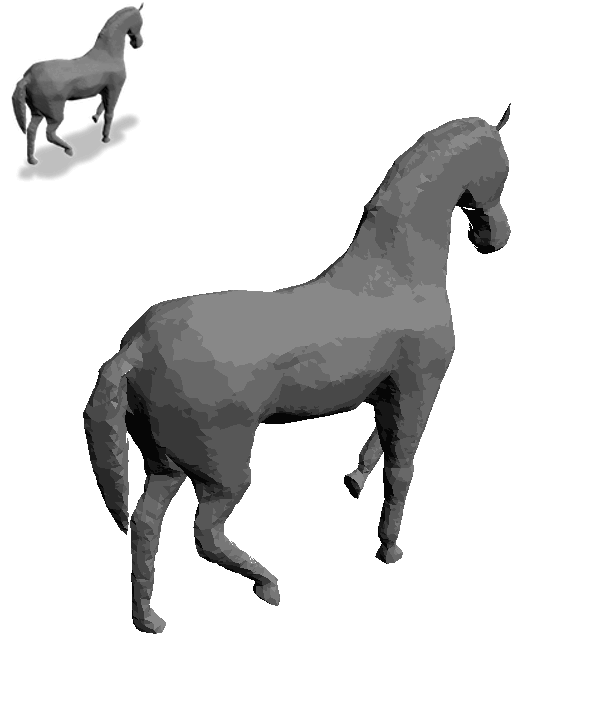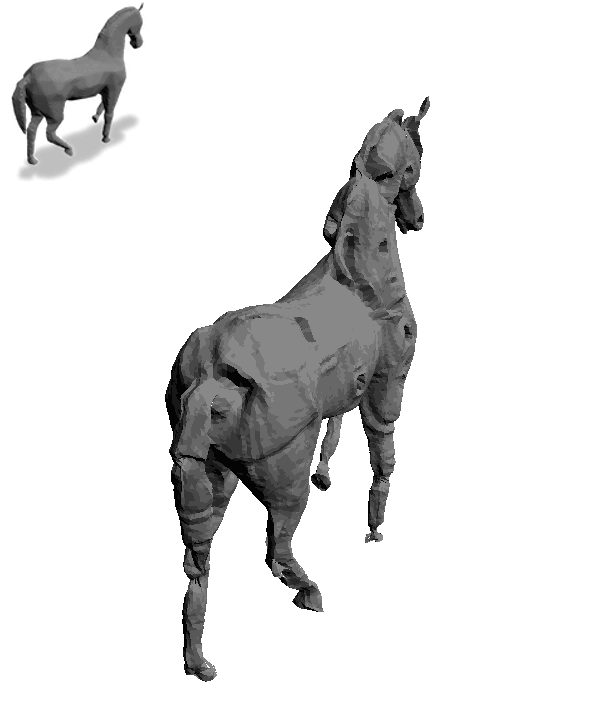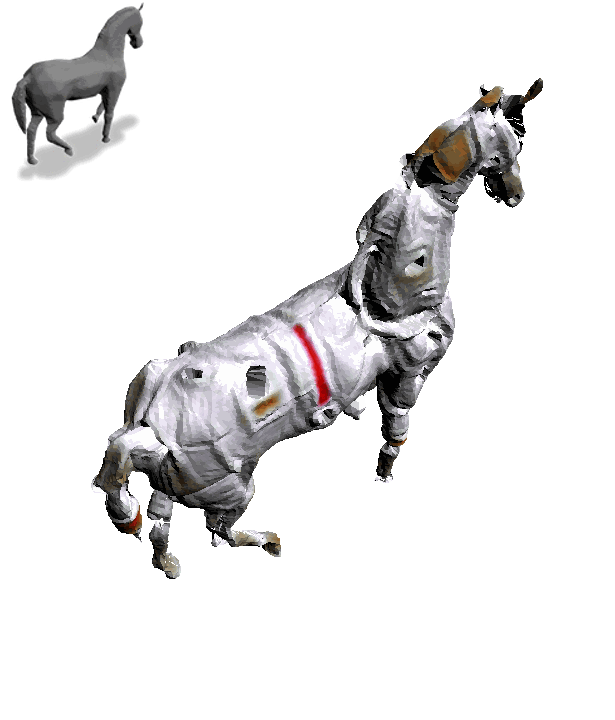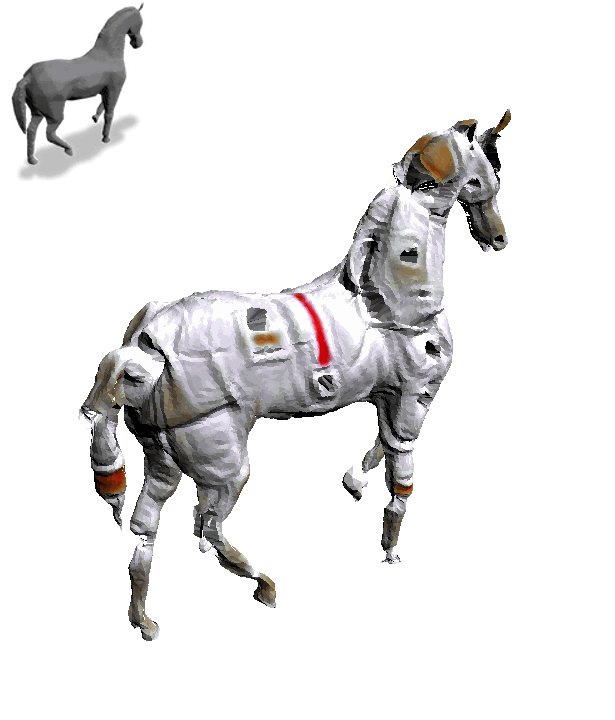
操作简单不说,每一个角度上的细节和纹理也都呈现出来了。
这就是用一个专门给3D物体“换皮肤”的模型Text2Mesh做出来的,由芝加哥大学和特拉维夫大学联合打造。

是不是有点意思?

一句话给3D物体“换皮肤”
Text2Mesh模型的输入只需一个3D Mesh(无论原始图像质量高低),外加一句文字描述。
具体变换过程如下:
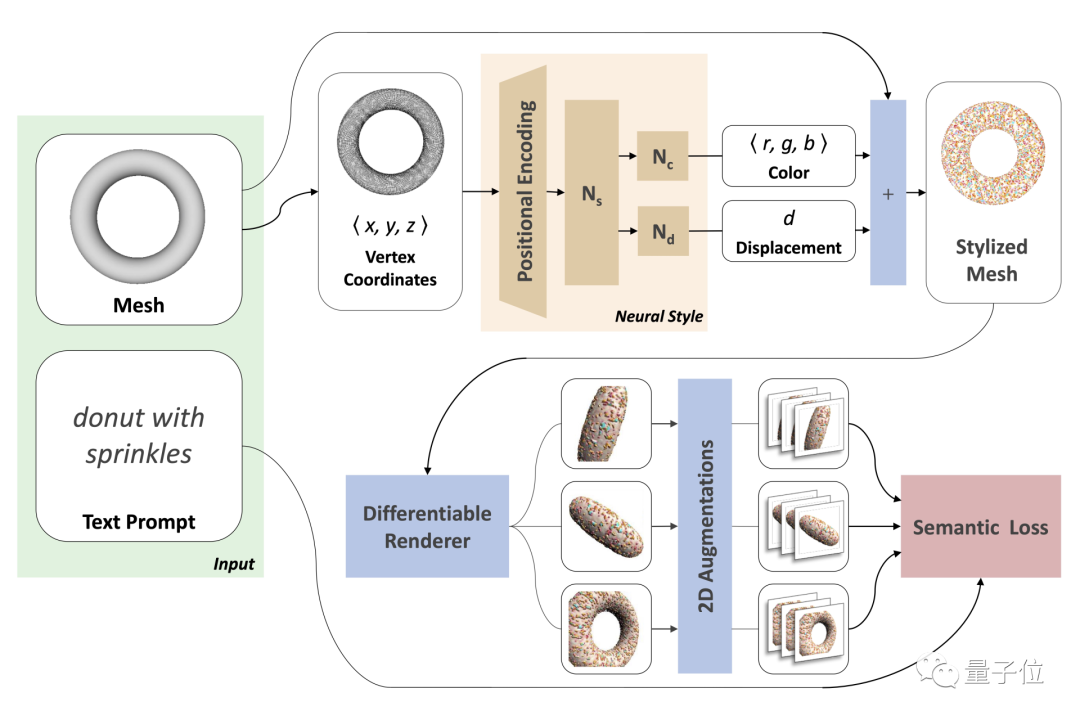
输入的原始网格模型mesh,顶点V∈Rn×3,表面F∈{1, . . . , n}m×3,它们在整个训练过程中固定不变。
然后再构造一个神经风格(neural style)网络,为mesh每个顶点生成一个样式属性,后续好在整个表面上定义风格。
具体来说,该网络将网格表面p∈V上的点映射成相应的RGB颜色,并沿法线方向位移,生成一个风格化了的初始mesh。
接着从多个视图对这个mesh进行渲染。
再使用CLIP嵌入的2D增强技术让结果更逼真。
在这个过程中,渲染图像和文本提示之间的CLIP相似性得分,会被作为更新神经网络权重的信号。
整个Text2Mesh不需要预训练,也不需要专门的3D Mesh数据集,更无需进行UV参数化(将三角网格展开到二维平面)。
具体效果如何?
Text2Mesh在单个GPU上训练的时间只需不到25分钟,高质量的结果可以在10分钟之内出现。
它可以生成各种风格,并且细节还原非常到位:

再比如下面这个,不管是变雪人、忍者、蝙蝠侠、绿巨人,还是乔布斯、梅西、律师……衣服的褶皱、配饰、肌肉、发丝……等细节都可以生动呈现。

研究人员还设计了一个用户调查,将Text2Mesh与基线方法VQGAN相比。
评分涉及三个问题:1、生成的结果自然程度;2、文本与结果的匹配度;3、结果与原始图像的匹配度。
57名用户打分后,得出的结果如下:
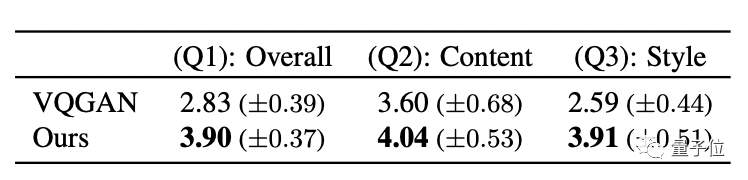
Text2Mesh在每一项上得分都比VQGAN高。
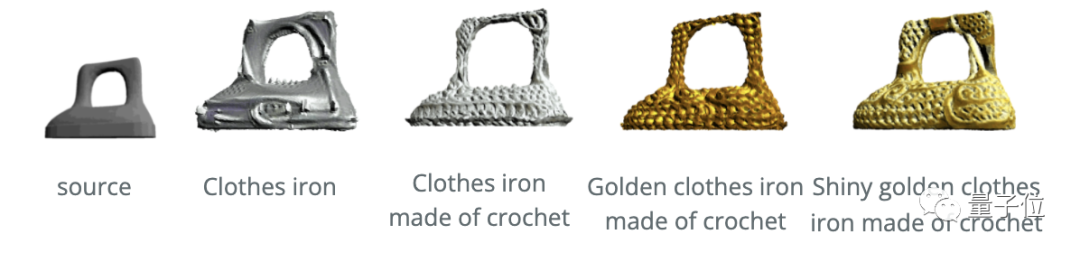
此外,在更复杂、更特殊的文本描述之下,Text2Mesh也能hold住。
比如“由钩针编织成的闪亮的金色衣服熨斗”:
“带波纹金属的蓝钢luxo台灯”:

更厉害的是,Text2Mesh模型还可以直接使用图片驱动。
比如就给一张仙人掌的照片,也能直接把原始灰色的3D小猪变成“仙人掌风格”:

One More Thing
Text2Mesh代码已开源,在Kaggle Notebook上也有人上传了demo。感兴趣的便朋友可以一试:
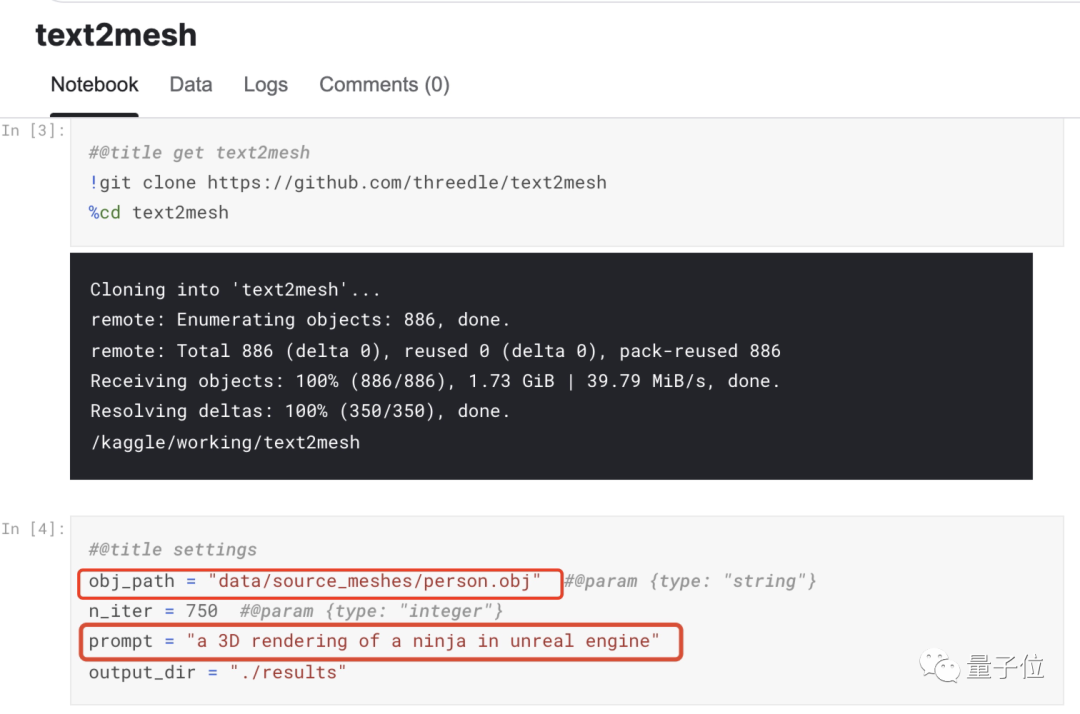
最后,大家知道这是只啥么?


demo地址:
https://www.kaggle.com/neverix/text2mesh/
论文:
https://arxiv.org/abs/2112.03221
代码:
https://github.com/threedle/text2mesh
参考链接:
https://threedle.github.io/text2mesh/
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



